Architecture Summary#
The inference service runs as a confidential kubernetes workload. The model provider ships a signed container image and encrypted model artifacts. The platform operator schedules that workload onto approved confidential GPU nodes through a confidential runtime class.
The model stays encrypted until the HW and SW infrastructure is cryptographically attested. Encrypted model artifacts are mounted or fetched as ciphertext and are decrypted only after attestation-gated key release. The validation of the state of the HW infrastructure (CPU and GPU) along with their feature capabilities is part of the infrastructure setup and validation. Successful attestation, triggers the workflow to perform a key-release, (through the KMS services), into the Trusted Execution Environment (TEE), which is the confidential pod in this case.
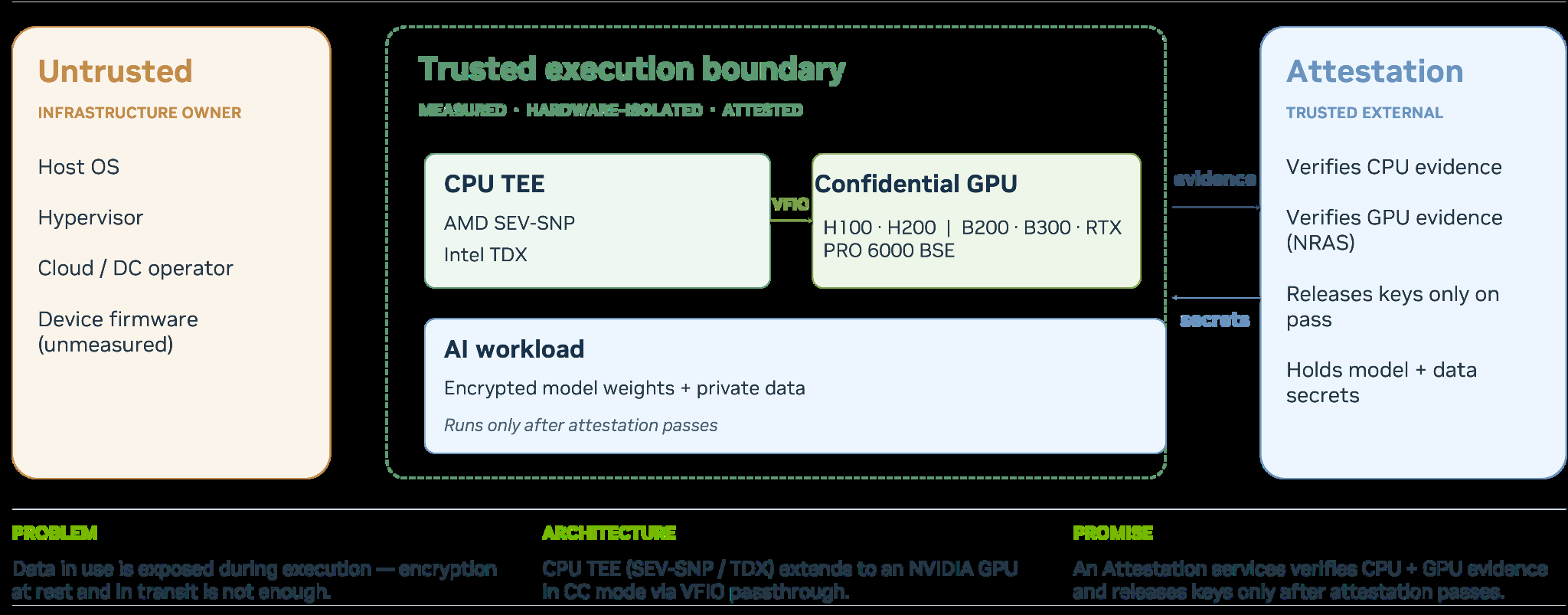
Figure 2 Confidential Container trust boundaries#
Kubernetes can schedule, route, monitor, and recover the workload, but the platform cannot read the model or inference payloads. The inference runtime, such as NIM, Triton, vLLM, TensorRT-LLM, or a custom model server, runs inside the confidential pod.
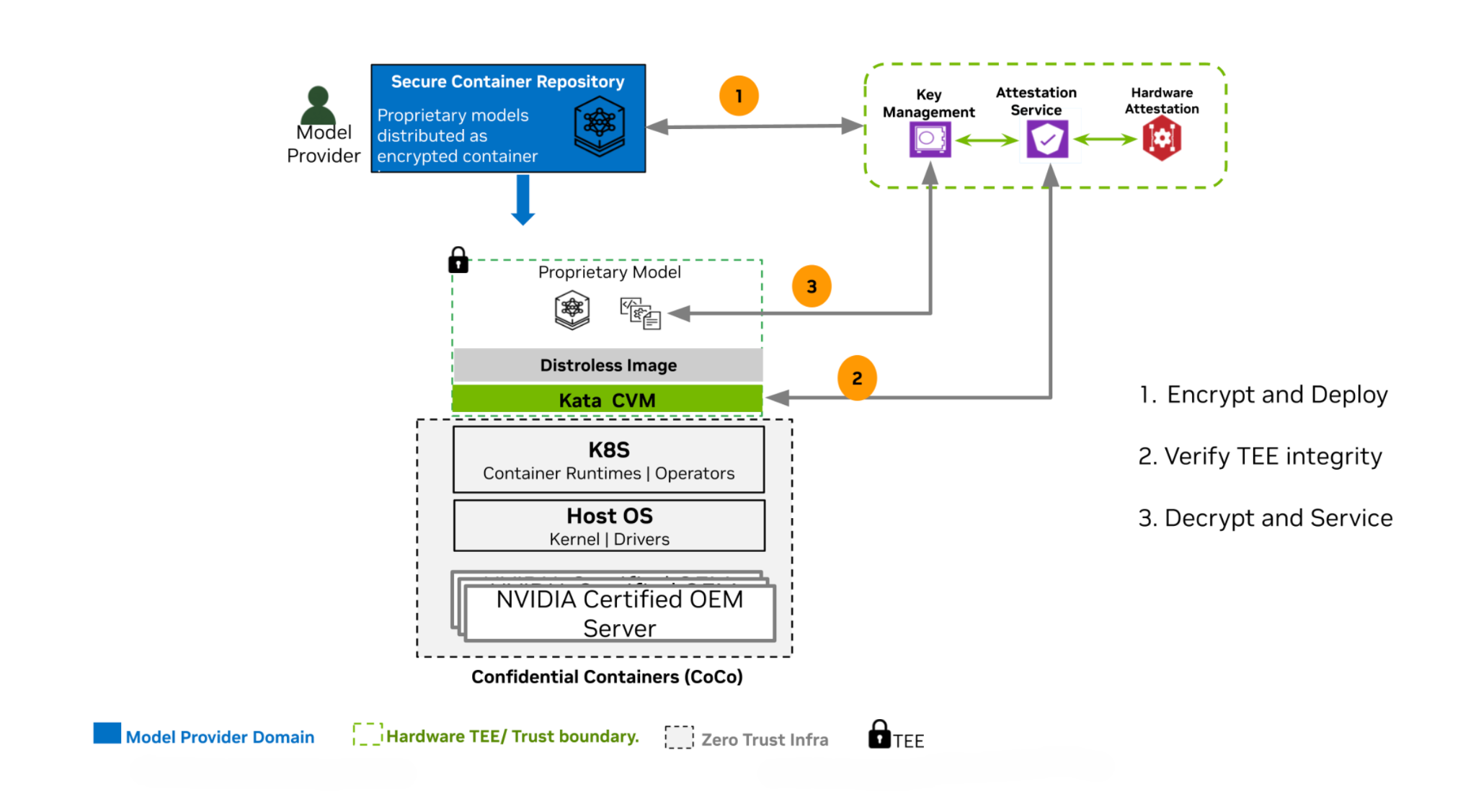
Figure 3 CoCo data flow, isolation layers, and policy boundaries#