NVIDIA® Nsight™ Development Platform, Visual Studio Edition 4.7 User Guide
Send Feedback
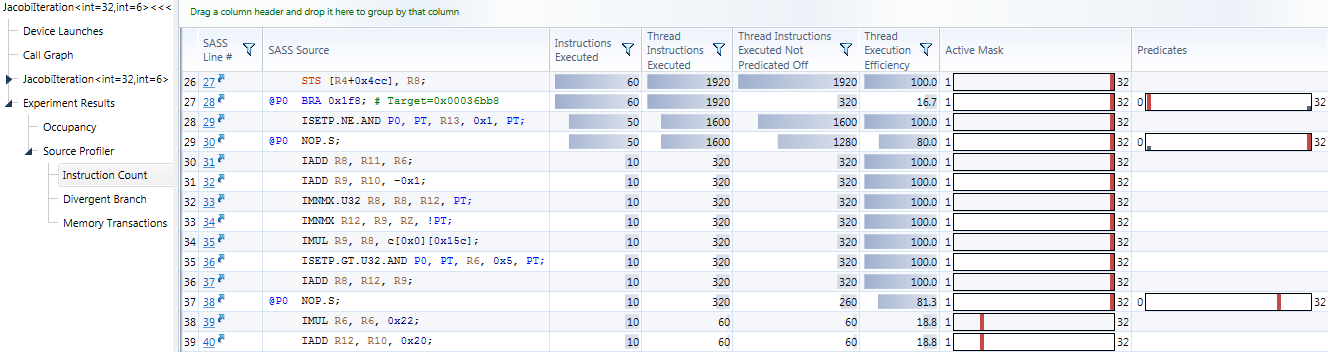
The Instruction Count source-level experiment identifies instructions which do not execute for all threads in the warp. If enabled, the experiment can also provide histograms of active mask and predication.
CUDA devices operate most efficiently when all threads in a warp are enabled. There are two reasons threads within a warp can be disabled: being inactive, and being predicated off. If the block size is not a multiple of the warp size, the last warp in the block will have inactive threads. When some threads within a warp exit the kernel while others continue, the exiting threads become inactive. Threads become predicated off when divergent branches occur, because the separate paths taken by the threads must be serialized, and threads are disabled for paths they do not take. For each instruction executed, the ratio of threads enabled in the warp to full warp size is called control flow efficiency, and the goal should be to achieve 100%. The Efficiency chart in the kernel-level Branch Statistics experiment shows control flow efficiency averaged over the duration of the kernel.
This experiment includes options to capture histograms for number of active threads, and number of threads not predicated off. The options must be enabled in the activity page's configuration, which is only accessible when using the Custom options for configuring experiments. Histogram bins with a non-zero count have gray bars, and the highest bin has a red bar.
Total executed instructions (any semantics per warp) regardless predicate or condition code.
Total executed instructions (per thread), regardless predicate or condition code.
Total executed instructions (per thread), with predicate and condition code evaluating to true.
Percentage of threads in the warp that were executed. 100% means all threads in a warp executed the instruction. Less than 100% means threads were inactive due to suboptimal launch or early return, or predicated off due to control flow divergence.
Distribution of active threads per instruction executed. There are bins for 1 to 32, since at minimum one thread must be active for the warp to remain active, and the maximum is the full WARP SIZE of 32. An optimal histogram has only counts in the bin close to WARP SIZE.
Distribution of active threads that are not predicated off per instruction executed. There are bins for 0 to 32, since at minimum all threads can be predicated off, and at maximum all 32 threads in the warp are enabled (not predicated off). The histogram is only displayed for instructions with predicates, which can be seen by enabling the SASS Source column. An optimal histogram has only counts in the bin close to WARP SIZE, although it is common to see single instructions or short sequences of instructions fully predicated off (a count in the zero bin). This is due to how control flow is implemented by the compiler, using branches (for long divergences) or predication (for short divergences, where avoiding the overhead of a branch is preferable).
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.