Open topic with navigation
Overview
Flow control can have a serious impact on the efficiency of executing a kernel. Especially if a lot of flow control decisions are divergent, forcing the threads of a warp into very different control paths through the kernel code. The Branch Statistics experiment helps answering the question of how often flow control instructions were executed, how many of them were uniform versus divergent, and how much the flow control impacted the overall kernel execution performance.
Background
A flow control instruction is considered to be divergent if it forces the threads of a warp to execute different execution paths. If this happens, the different execution paths must be serialized, since all of the threads of a warp share a program counter; this increases the total number of instructions executed for this warp. When all the different execution paths have completed, the threads converge back to the same execution path. Conditional expressions that evaluate to a uniform decision across all threads of a warp, do only execute the single, selected code path - consequently causing a lot less overhead. The ratio of executed uniform flow control decisions over all executed conditionals is defined as Branch Efficiency.
The actual performance impact caused by divergent flow control is proportional to the combination of how many different code paths need to be evaluated and how expensive the serialized code segments are. One way of capturing this is to track for all executed instructions how many of the threads in a warp were actually participating in the execution, i.e. how many threads were not predicated off. This is typically referred to as Control Flow Efficiency. By definition this is independent of the number of flow control decisions made, but rather states an upper limit of the utilization of the available compute resources due to flow control.
Charts
Efficiency
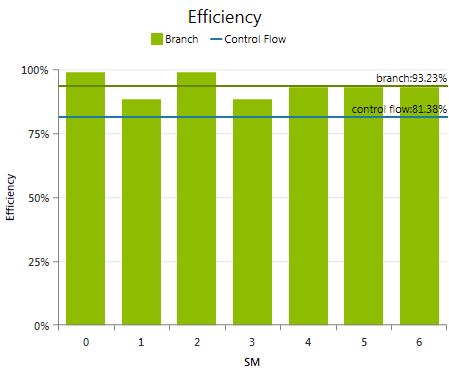
The efficiency chart shows the two primary metrics for evaluating the impact of flow control. Focus on the Flow Control Efficiency to estimate the expected maximum peak performance taking branching into account.
There are many ways a conditional expression written in CUDA C can be translated to final assembly code. Note that not all possible variants of a conditional operation can be accounted for with the shown metrics. Hence, it is valid to state that low control flow efficiency always indicates a performance issue. However, the reverse might not necessarily be true – and a kernel exposing close-to-optimal control flow efficiency might still be hindered by flow control.
Metrics
Branch Efficiency
States the ratio of uniform control flow decisions over all executed branch instructions. Shown per-SM (the bars) and averaged over all SMs (the Branch line). Higher values are better, as warps more often take a uniform code path. A value lower than 100% is a necessary, but not sufficient indicator for a negative impact on the kernel execution performance, since the metric does not have any knowledge about the size of the code regions enclosed by the conditionals. For example, one divergent flow control decision out of ten executed branches may be negligible if it encloses very few lines of code only; but it may have a huge impact if it forced the warp to execute many different code paths with thousands of instructions.
Control Flow Efficiency
Defined as the ratio of active threads that are not predicated off over the maximum number of threads per warp for each executed instruction. Gets lower with fewer threads per warp being active per instruction; therefore serving as a metric for the efficiency in using the available processing units. Lower control flow efficiency can be caused by: Launching warps with less than 32 threads active. Terminating some threads in a warp earlier than others. Or executing instructions with only a subset of the threads enabled.
|
Branches Per Warp
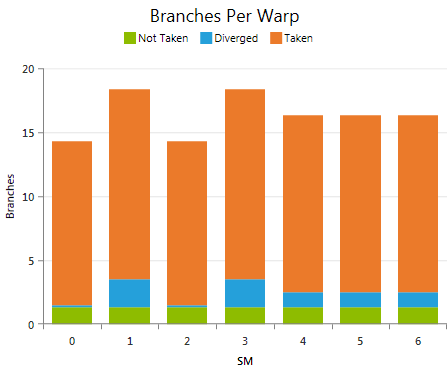
Shows the average count of executed branch instructions per warp per SM grouped by the outcome of the evaluation of the conditional statement. Useful to investigate the total amount of flow control instructions executed for the warps of the kernel grid. Compare the number of executed branch instructions per warp to the total number of executed instructions per warp as reported by the IPW metric of the Instructions Statistics experiment to get an understanding of the frequency of executing branch instructions in the kernel code.
The reported values for branches taken and not taken refer to the conditional statements as executed on the device. This does not necessarily match to the definition expressed in the CUDA-C or PTX code, if the compiler chose to negate the condition during the optimization stage. Check the Source View page to investigate the mapping between high-level code and assembly code.
Metrics
Not Taken / Taken
Average number of executed branch instructions with a uniform control flow decision per warp; that is all active threads of a warp either take or not take the branch.
Diverged
Average number of executed branch instruction per warp for which the conditional resulted in different outcomes across the threads of the warp. All code paths with at least one participating thread get executed sequentially. Lower numbers are better; however, check the Flow Control Efficiency to understand the impact of control flow on the device utilization.
|
Branches Condition
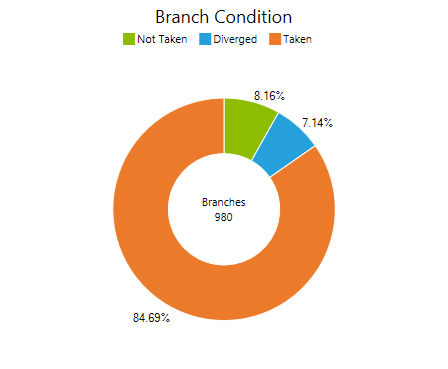
Shows the distribution of executed branches that were uniform versus divergent aggregated across all warps of the kernel grid. In case the percentage of divergent branches is high, consider reorganizing the way the workload is split into blocks and warps; an alternative workload distribution scheme may allow for less divergent control flow and may also reduce the overall need for flow control decisions. For more details also see the section Branching and Divergence of the CUDA C Best Practices Guide.
The reported values for branches taken and not taken refer to the conditional statements as executed on the device. This does not necessarily match to the definition expressed in the CUDA-C or PTX code, if the compiler chose to negate the condition during the optimization stage. Check the Source View page to investigate the mapping between high-level code and assembly code.
Metrics
Not Taken / Taken
Total number of executed branch instructions with a uniform control flow decision; that is all active threads of a warp either take or not take the branch.
Diverged
Total number of executed branch instruction for which the conditional resulted in different outcomes across the threads of the warp. All code paths with at least one participating thread get executed sequentially. Lower numbers are better, however, check the Flow Control Efficiency to understand the impact of control flow on the device utilization.
|
Analysis
Several general coding guidelines around Control Flow are highlighted in the CUDA C Best Practices Guide:
Based on the results of this experiment, check for applicable statements:
-
If the Control Flow Efficiency is low and …
-
… and Branch Efficiency is high, check the execution configuration of the kernel launch. If the number of threads in each block is not a multiple of the warp size, the partially active warps use only a portion of the available processing units - lowering the overall control flow efficiency.
-
… and Branch Efficiency is low, the kernel execution is less efficient due to divergent control flow. Where possible try to rearrange the workloads so that the thread of a warp all follow a common path. Use the Divergent Branch experiment to identify which branch instructions cause the most divergence and affect the largest areas of code. Focus on optimizing those branches first.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.