Open topic with navigation
Overview
The Instruction Statistics experiment provides a first level triage for understanding the overall utilization of the target device when executing the kernel. It answers the following questions: Is the kernel grid able to keep all multiprocessors busy for the complete execution duration? Is a well-balanced distribution of workloads achieved? Does the achieved instruction throughput come close to the hardware's peak performance?
Background
For devices of compute capability 2.0 and higher the global work distribution engine schedules thread blocks to Streaming Multiprocessors (SM). A multiprocessor is considered to be active if it has at least one warp assigned to it. The total number of cycles a SM was active for the duration of the kernel execution is defined as Active Cycles.
Each multiprocessor exposes multiple warp schedulers that are able to execute at least one instruction per cycle. On the Fermi architecture (compute capability 2.x) an SM has two warp schedulers. The Kepler architecture (compute capability 3.x) features four warp schedulers per SM. At every instruction issue time, each warp scheduler selects one warp that is able to make forward process from its assigned list of warps. For this selected warp the scheduler then issues either the next single instruction or the next two instructions. Dual issue is supported by devices of compute capability 2.x and higher and is applicable to independent instructions only.
A warp scheduler might need to issue an instruction multiple times to actually complete the execution for all 32 threads of a warp. The two primary reasons for this difference between Instructions Issued and Instructions Executed are: First, address divergence and bank conflicts on memory operations (for more details see the memory sections of the technical specification for each compute capability). Second, assembly instructions that can only be issued for a half-warp per cycle and thus need to be issued twice. Double floating-point instructions are the prime example for such instructions. As each executed instruction needs to be at least issued once, the following statement holds true in all cases:
Instructions Issued >= Instructions Executed
Issuing an instruction multiple times is also referred to as Instruction Replay. Each replay iteration takes away the ability to make forward progress by issuing new instructions on that warp scheduler. Also the compute resources required to process the instruction are consumed for every instruction replay. In short, the more instruction replay iterations are required the higher is the performance impact on the kernel execution.
Charts
Instructions Per Clock (IPC)
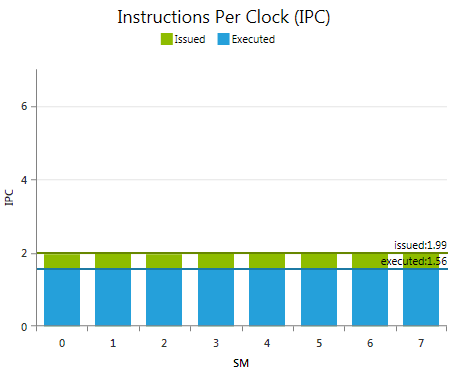
A z-ordered column graph showing the achieved instructions throughputs per SM for both, issued instructions and executed instructions. The theoretical maximum peak IPC is a device limit and defined by the compute capabilities of the target device. The y-axis is scaled to this peak value.
The peak IPC value is the maximum number of executed instructions achievable on a single cycle. The maximum sustainable executed IPC might be lower.
Metrics
Issued IPC
The average number of issued instructions per cycle accounting for every iteration of instruction replays. Optimal if as close as possible to the Executed IPC. As described in the background section of this document, some assembly instructions require to be multi-issued. Hence, the instruction mix affects the definition of the optimal target for this metric.
Executed IPC
The average number of executed instructions per cycle. Higher numbers indicate more efficient usage of the available all resources. Keep in mind that the reported values are given per multiprocessor. As each warp scheduler of a multiprocessor can execute instructions independently, a target goal of executing one instruction per cycle means executing on average with an IPC equal to the number of warp schedulers per SM. The maximum achievable target IPC for a kernel is dependent on the mixture of instructions executed.
|
SM Activity
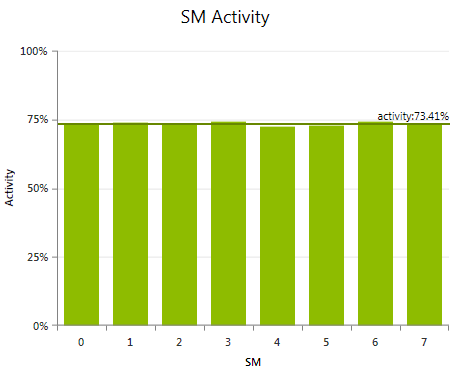
Shows the percentage of time each multiprocessor was active during the duration of the kernel launch. A multiprocessor is considered to be active if at least one warp is currently assigned for execution. An SM can be inactive - even though the kernel grid is not yet completed - due to high workload imbalances. Such uneven balancing between the SMs can be caused by a few factors: Different execution times for the kernel blocks, variations between the number of scheduled blocks per SM, or a combination of the two.
The observable result of a load imbalance are highly different activity values across the multiprocessors; simply caused by the fact that some SMs are still busy executing work, while others SMs already completed their share of work and stay idle as no more work items are left to be scheduled. This is typically referred to as a Tail Effect. Small kernel grids with a low number of blocks are more likely to be affected by a tail effects. Concurrent Kernel Execution can utilize the idle multiprocessors for processing a subsequent kernel launch. As profile activities observe each kernel launch in isolation, the profile results can only indicate the existence of a tail effect. To analyze the effectiveness of concurrent kernel execution run a CUDA trace activity.
|
Instructions Per Warp (IPW)
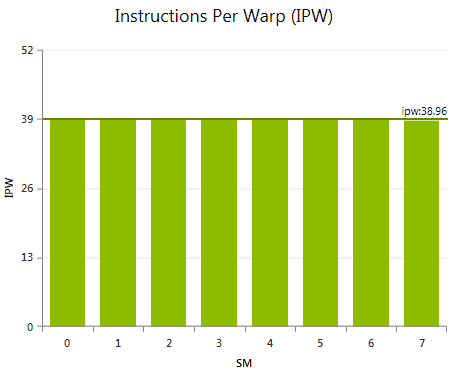
Shows the average executed instructions per warp for each multiprocessor. High variations in the IPW metric across the SMs indicate non-uniform workloads for the blocks of the kernel grid. While such imbalance does not necessarily have to result in low performance, IPW is very useful to understand the cause of variations in SM Activity.
The most common code pattern to cause high variations in IPW is conditionally executed code blocks where the conditional expression is dependent on the block index. Examples include: special pre-processing or post-processing operations executed for a single block only. Or costly detection and handling of edge conditions that are only triggered for some subset of the grid.
|
Warps Launched
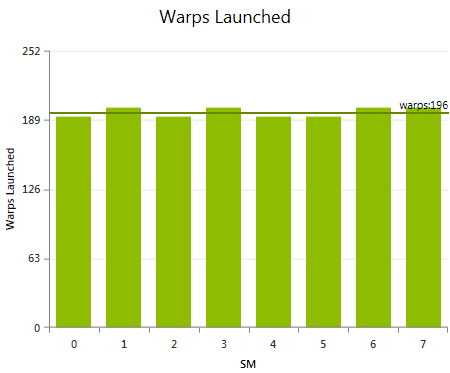
Shows the total number of warps launched per multiprocessor for the executed kernel grid. Large differences in the number of warps launched per SM are most commonly the result of providing an insufficient amount of parallelism with the kernel grid. More specifically, the number of kernel blocks is too low to make good use of all available compute resources. A high variation in the number of warps launched is only a concern if the SM Activity is low on one or more SMs. In this case, consider a different way to partitioning your workload that either result in less variance in execution duration per warp or in the execution of more thread blocks. Both cases will help the work distributor in dispatching the given work more evenly.
|
Analysis
-
If the average SM Activity for the kernel launch is low and …
-
… there is little variation across the multiprocessors, the kernel grid is not able to utilize all compute resources. If possible, increase your problem size or investigate the host application's ability to apply Concurrent Kernel Execution for utilizing otherwise idle compute resources.
-
… there is a high variation across the multiprocessors, check the Instructions per Warp chart and the Warps Launched chart to understand what causes the imbalance. Likely optimization strategies include adjusting the partitioning scheme of the kernel grid to expose more thread blocks or reducing the differences in workloads across the blocks of the grid.
-
If the average executed Instructions per Clock is low …
-
… run the memory experiments and investigate from there if the kernel has poor memory access patterns or many bank conflicts. Both force the instructions to be replayed multiple times, causing resources to be spent on those replayed operations, rather than make further progress executing the kernel.
-
… double check if mix of executed instructions includes many high latency instructions, which offer a lower IPC than the device’s theoretical maximum. Those instructions typically include double-precision floating point operations and transcendental functions. The Achieved FLOPS experiment, the Achieved IOPS experiment, and the Disassembly Regex experiment may help in identifying the instruction mix.
-
… run the Issue Efficiency experiment and check of the kernel has many dependencies between subsequent instructions, and the available parallelism is not sufficient to hide those dependencies.
-
… run the Achieved Occupancy experiment to verify that the overall parallelism of the kernel grid is sufficient to efficiently hide latency.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.