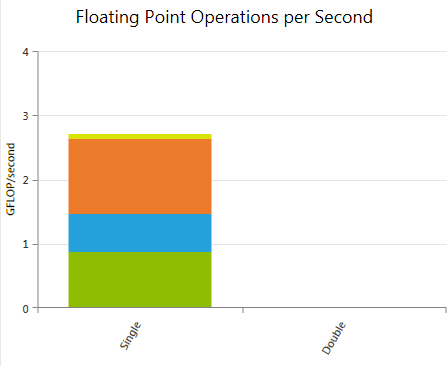
Floating Point Operations
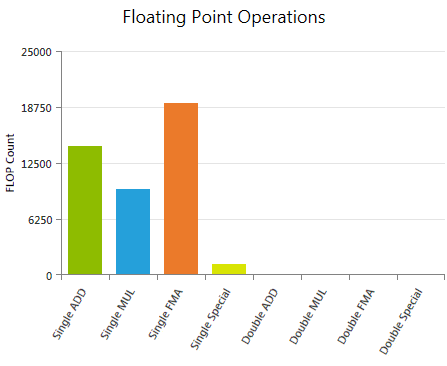
Reports the weighted sum of hit counts for executed floating point instructions grouped by instruction class. The applied weights can be customized prior to data collection using the Experiment Configuration on the Activity Page.
Depending on the actual operation and the used compiler flags, a single floating point instruction written in CUDA C may result in multiple instructions in assembly code. The reported values refer to the executed assembly instructions; therefore the numbers may differ from expectations derived exclusively from the CUDA C code. Use the Source View page to investigate the mapping between high-level code and assembly code.
Metrics
Single ADD
Weighted sum of all executed single precision floating point additions (FADD). The default weight is 1.
Single MUL
Weighted sum of all executed single precision floating point multiplications (FMUL). The default weight is 1.
Single FMA
Weighted sum of all executed single precision floating point fused multiply-add (FFMA) instructions. The contraction of floating-point multiplies and adds/subtracts into floating-point multiply-add operations can be controlled by the --fmad compiler flag. The default weight is 2.
Single Special
Weighted sum of all executed single precision special operations, including the reciprocal (RCP), reciprocal of the square root (RSQ), sine or cosine (SIN/COS), base-2 exponential (EX2), and base-2 logarithm (LG2). Each special function can be assigned a separate weight. The default weight is 1; except of RSQ which is multiplied with a default value of 2.
Double ADD
Weighted sum of all executed double precision floating point additions (DADD). The default weight is 1.
Double MUL
Weighted sum of all executed double precision floating point multiplications (DMUL). The default weight is 1.
Double FMA
Weighted sum of all executed double precision fused multiply-add (DFMA) instructions. The contraction of floating-point multiplies and adds/subtracts into floating-point multiply-add operations can be controlled by the --fmad compiler flag. The default weight is 2.
Double Special
Weighted sum of all executed double precision special operations, including the reciprocal (RCP) and reciprocal of the square root (RSQ). The two special functions can be assigned a separate weight. The default weight for RCP is 1; RSQ is multiplied by a default value of 2.