Open topic with navigation
Overview
Knowing the number of executed integer operations and the mix of instructions is a useful input for come up with sound estimates of performance expectations for a kernel. And it also serves as basis for better understanding many other metrics and experiments. Similar to the Achieved FLOPS experiment, its primary benefit is tracking and evaluating differences in performance for the code changes made; rather than deriving the actual cause of a performance limitation.
Background
On devices of compute capability 1.x, 32-bit integer multiplication is implemented using multiple instructions as it is not natively supported. 24-bit integer multiplication is natively supported however via the __[u]mul24 intrinsic. Using __[u]mul24 instead of the 32-bit multiplication operator whenever possible usually improves performance for instruction bound kernels. It can have the opposite effect however in cases where the use of __[u]mul24 inhibits compiler optimizations.
On devices of compute capability 2.x and beyond, 32-bit integer multiplication is natively supported, but 24-bit integer multiplication is not. __[u]mul24 is therefore implemented using multiple instructions and should not be used.
Integer division and modulo operation are costly: tens of instructions on devices of compute capability 1.x, below 20 instructions on devices of compute capability 2.x and higher. They can be replaced with bitwise operations in some cases: If n is a power of 2, (i/n) is equivalent to (i>>log2(n)) and (i%n) is equivalent to (i&(n-1)); the compiler will perform these conversions if n is literal.
References to specific assembly instructions in this document are made in regard to the actual instruction set architecture (ISA) of the hardware, called SASS. For a description and a full list of SASS assembly instructions for the different CUDA compute architectures see the documentation of the NVIDIA CUDA tool cuobjdump.
Charts
Integer Operations
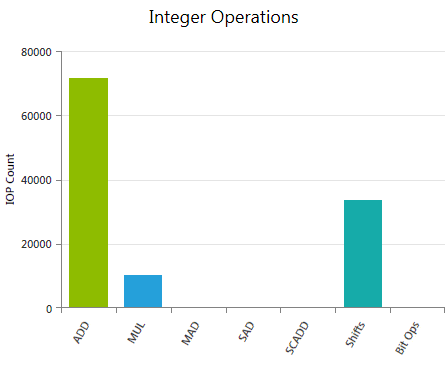
Reports the weighted sum of hit counts for executed integer instructions grouped by instruction class. The applied weights can be customized prior to data collection using the Experiment Configuration on the Activity Page.
Depending on the actual operation and the used compiler flags, a single integer instruction written in CUDA C may result in multiple instructions in assembly code. The reported values refer to the executed assembly instructions; therefore the numbers may differ from expectations derived exclusively from the CUDA C code. Use the Source View page to investigate the mapping between high-level code and assembly code.
Metrics
ADD
Weighted sum of all executed integer additions (IADD). The default weight is 1.
MUL
Weighted sum of all executed integer multiplications (IMUL). The default weight is 1.
MAD
Weighted sum of all executed integer multiply-add (IMAD) instructions. The default weight is 2.
SAD
Weighted sum of all executed sum-of-absolute-differences (ISAD) instructions. The default weight is 1.
SCADD
Weighted sum of all executed shift-and-add (ISCADD) instructions. The default weight is 2.
Shifts
Weighted sum of all executed shift instructions, covering shift-right (SHR), shift-left (SHL), and funnel-shift (SHF) operations. The default weight is 1.
Bit Ops
Weighted sum of all executed integer bit operations. Specifically accouning for bit-field-extract (BFE), bit-field-insert (BFI), and find-leading-one (FLO) operations. The default weight is 1.
|
Integer Operations per Second
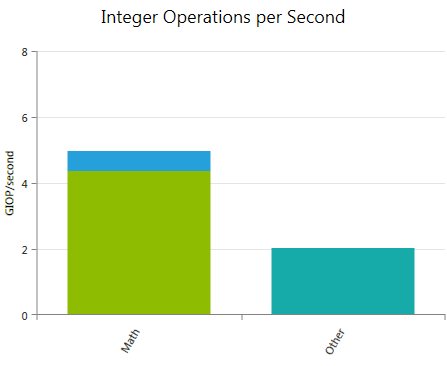
Reports the weighted sum of hit counts for executed integer instructions per second. The chart is a stacked bar graph using the very same instruction classes as the Integer Operations chart.
Metrics
Math
Weighted sum of all executed integer arithmetic instructions per second. Combines the individual contributions of ADD, MUL, MAD, SAD, and SCADD as reported in the Integer Operations chart.
Other
Weighted sum of shift instructions and bit operations per second.
|
Analysis
General hints for optimizing integer Arithmetic Instructions are given in the CUDA C Best Practices Guide:
Also try mimimizing the number of executed arithmetic instructions with low throughput. The CUDA C Programming Guide provides a list of the expected throughputs for all native Arithmetic Instructions per compute capability.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.