NVIDIA® Nsight™ Development Platform, Visual Studio Edition 4.7 User Guide
Send Feedback
The Issue Efficiency experiment provides information about the device's ability to issue the instructions. The key takeaway is the answer to the question if the device was able to issue instructions every cycle. Not being able to do so inevitably lowers the potential peak performance of the kernel. Understanding the root cause of not being able to issue instructions back-to-back is a good high-level triage for analyzing a kernel's performance.
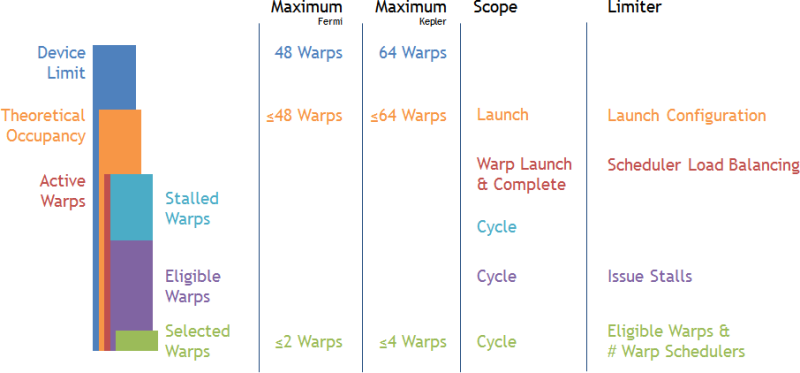
For devices of compute capability 2.0 and higher the Streaming Multiprocessors (SM) feature multiple warp schedulers. Each warp scheduler manages a fixed, hardware-given maximum number of warps. This defines the Device Limit of warps per SM - the upper bound of how many warps can be resident at once on each SM. The execution configuration of a kernel launch can further limit the number of warps that can be resident due to resource constraints (see ... for more details). Theoretical Occupancy defines the uppermost limit of warp parallelism on an SM. So far all discussed information is statically defined by the target device, the kernel's source code, and the launch parameters. At runtime, the number of warps allocated to a multiprocessor at once for every cycle is referred to as Active Warp. In best case the average active warps across the kernel execution is equal or very close to the theoretical occupancy. However if the scheduler fails to balance the workload evenly across the warp schedulers or simply no remaining work is left to issue to fill up the machine, the actual number of active warps can be significantly lower than the theoretical occupancy. The discussed metrics relate to each other by:
Device Limit >= Theoretical Occupancy >= Active Warps
The set of active warps can be thought of as the pool of candidates for making forward progress at runtime at a given moment in time. However not all active warps might necessarily be able to issue their next instruction. For example a warp may be sitting at a barrier waiting for other warps to catch up, it might not have fetched its next instruction yet, or it waits for results from previous instructions to become available. Separating active warps by their ability to issue their next instruction leads to the sub-set of Stalled Warps not able to make forward progress and the sub-set of Eligible Warps that are ready to issue their next instruction. In more detail, an active warp is considered eligible if the instruction has been fetched, the execution unit required by the instruction is available, and the instruction has no dependencies that have not been met. By definition we can state the relation between those metrics as:
Active Warps == Stalled Warps + Eligible Warps
At every cycle each warp scheduler will pick an eligible warp and issue one or more instructions. If no eligible warp is available for a cycle the scheduler the opportunity of making forward progress is lost and processing units might become unutilized. As each scheduler picks either no or exactly one warp, the Selected Warps per multiprocessor per cycle is bound to the range of [0 .. # Warp Schedulers per SM]. To guarantee that each scheduler can issue an instruction every cycle, there needs to be at least a single eligible warp available per warp scheduler per cycle. Consequently, the target value of eligible warps per scheduler is to have at least one or more warps available per cycle. In the context of the SM this is having at least as many eligible warps as warp schedulers.
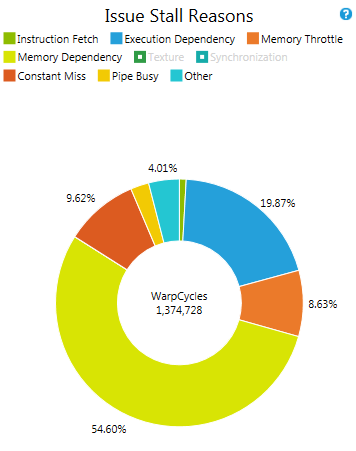
Warps Per SM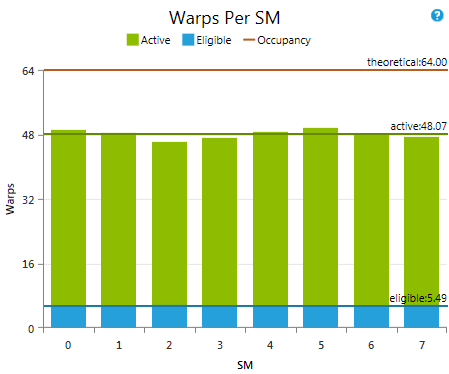
Provides an overview of the various warps per SM metrics discussed in the background section of this document. The metrics are reported as average values across the complete kernel execution for each individual SM of the target device. The y-Axis is scaled to the device limit. Even if on average a sufficient amount of eligible warps is reported, this does not necessarily guarantee that there was never a cycle that missed to issue one instruction per warp scheduler. MetricsActive Warps A warp is active from the time it is scheduled on a multiprocessor until it completes the last instruction. Each warp scheduler maintains its own list of assigned active warps. This assignment of warps to the schedulers is done once at the time a warp becomes active and is valid for the lifetime of the warp. As a rough guideline you want to have at least a minimum of eight active warps per warp scheduler. More active warps might allow hiding warp latencies more efficiently. Eligible Warps An active warp is considered eligible if it is able to issue the next instruction. Each warp scheduler will select the next warp to issue an instruction from the pool of eligible warps. Warps that are not eligible will report an Issue Stall Reason. The target is to have at least one eligible warp per scheduler per cycle. Theoretical Occupancy The theoretical occupancy acts as upper limit to active warps and consequently also eligible warps per SM. It is defined by the execution configuration of the kernel launch. More detailed information is discussed in the context of the Achieved Occupancy experiment. |
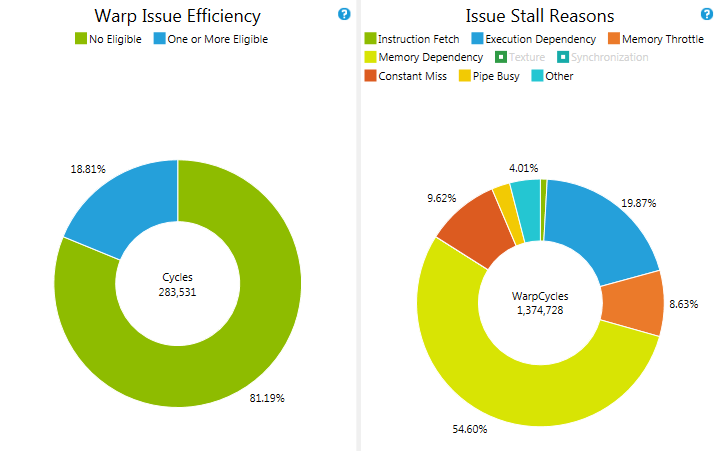
Warp Issue Efficiency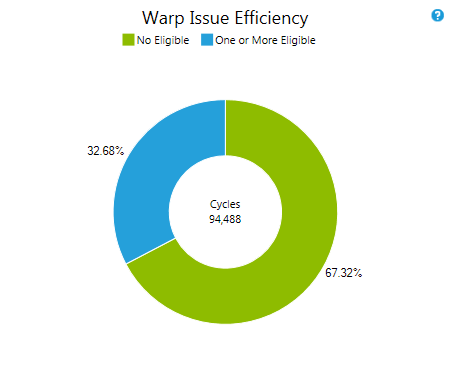
Distribution of the availability of eligible warps per cycle across the GPU. The values are reported as sum across all warp schedulers for the duration of the kernel execution. On devices with compute capability 2.x the chart exposes three metrics. No eligible warps means both warp schedulers failed to issue. One eligible denotes only one warp scheduler has an eligible warp available. Two or more guarantees that both warp schedulers issue an instruction. MetricsNo Eligible The number of cycles that a warp scheduler had no eligible warps to select from and therefore did not issue an instruction. The lower the percentage of cycles with no eligible warp the more efficient the code runs on the target device. Investigate the Issue Stall Reason to understand what keeps warps from becoming eligible, if this value is high. One or More Eligible The number of cycles that a warp scheduler had at least one eligible warps to select from. This metric is equal to total number of cycles an instruction was issued summed across all warp schedulers. Better if the value is higher with a target of getting close to 100%. |
--use_fast_math to quickly check the potential effects of this optimization approaches.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.