Pipe Utilization
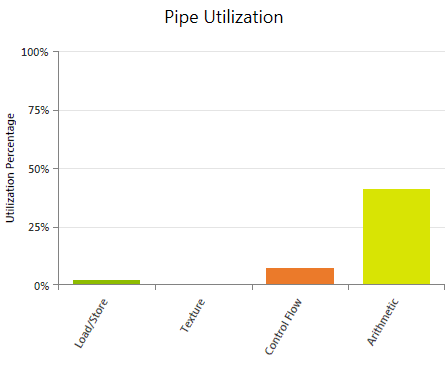
Shows the average utilization of the four major logical pipelines of the SMs during the execution of the kernel. Useful for investigating if a pipeline is oversubscribed and therefore is limiting the kernel's performance. Also helpful to estimate if adding more work will scale well or if a pipeline limit will be hit. In this context adding more work may refer to adding more arithmetic workload (for example by increasing the accuracy of some calculations), increasing the number of memory operations (including introducing register spilling), or increasing the number of Active Warps per SM with the goal of improving instruction latency hiding.
The reported values are averages across the duration of the kernel execution. A low utilization percentage does not guarantee that the pipeline was never oversubscribed at some point during the kernel execution.
Metrics
Load / Store
Covers all issued instructions that trigger a request to the memory system of the target device - excluding texture operations. Accounts for load and store operations to global, local, shared memory as well as any atomic operation. Also includes register spills. Devices of compute capability 3.5 and higher support loading global memory through the Read-Only Data Cache (LDG); those operations do not contribute to the load/store group, but are accounted for in the texture pipeline utilization instead. In cases of high load/store utilization, collect the Memory Experiments to gain more information about the type, count, and efficiency of the executed memory operations.
Texture
Covers all issued instructions that perform a texture fetch and, for devices of compute capability 3.5 and higher, global memory loads via the Read-Only Data Cache (LDG). If this metric is high, run the Memory - Texture experiment to evaluate the executed texture requests in more detail.
Control Flow
Covers all issued instructions that can have an effect on the control flow, such as branch instructions (BRA,BRX), jump instructions (JMP,JMX), function calls (CAL,JCAL), loop control instructions (BRK,CONT), return instructions (RET), program termination (EXIT), and barrier synchronization (BAR). See the Instruction Set Reference for more details on these individual instructions. If the control flow utilization is high, run the Branch Statistics experiment; this can help understanding the effects of control flow on the overall kernel execution performance.
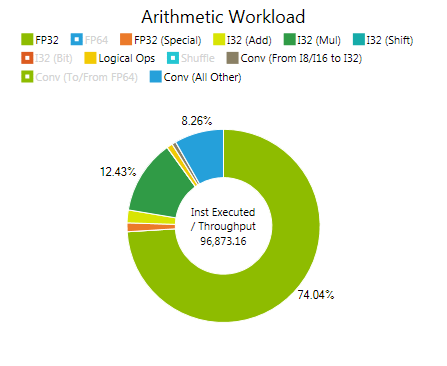
Arithmetic Covers all issued floating point instructions, integer instructions, conversion operations, and movement instructions. See the Instruction Set Reference for a detailed list of assembly instructions for each of these groups. If the arithmetic pipeline utilization is high, check the Arithmetic Workload chart to identify the type of instruction with the highest costs.