Open topic with navigation
Overview
The local memory space resides in device memory, so local memory accesses have the same high latency and low bandwidth as global memory accesses and are subject to the same requirements for memory coalescing as discussed in the context of the Memory Statistics - Global experiment. Local memory is however organized such that consecutive 32-bit words are accessed by consecutive thread IDs. Accesses are therefore fully coalesced as long as all threads in a warp access the same relative address (e.g., same index in an array variable, same member in a structure variable).
Local memory accesses only occur for some automatic variables as detailed further in the Variable Type Qualifiers section of the CUDA C Programming Guide. Automatic variables that the compiler is likely to place in local memory are:
-
Arrays for which it cannot determine that they are indexed with constant quantities,
-
Large structures or arrays that would consume too much register space,
-
Any variable if the kernel uses more registers than available (this is also known as register spilling).
In addition, some mathematical functions have implementation paths that might access local memory. Running the Memory Transactions experiment will tell which SASS instructions caused local memory transactions. Using the code correlation feature of the Source View on the results of the memory transactions experiment allows pinpointing if a variable has been placed in local memory during the kernel compilation. Also, the compiler reports total local memory usage per kernel (lmem) when compiling with the --ptxas-options=-v option.
On devices of compute capability 2.x and higher, all local memory accesses are always cached in L1 and L2. The output of this experiment shows all local memory traffic as generated during the execution of the kernel.
Chart
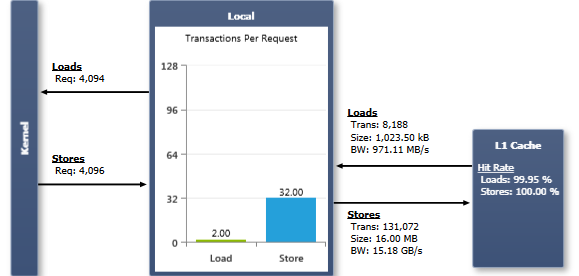
The number of Load/Store Requests equals the amount of local memory instructions executed. When a warp executes an instruction that accesses local memory, it coalesces the memory accesses of the threads within the warp into one or more of these Memory Transactions depending on the size of the word accessed by each thread and the distribution of the memory addresses across the threads. In general, the more transactions are necessary, the more unused words are transferred in addition to the words accessed by the threads, reducing the instruction throughput accordingly. In addition, each memory transaction requires the assembly instruction to be repeatedly issued again; causing instruction replays if more than one transaction is required to fulfill the request of a warp. More details on instruction replays and their performance implications are described in the context of the Instruction Statistics experiment.
The Transactions Per Request chart shows the average number of L1 transactions required per executed local memory instruction, separately for load and store operations. Lower numbers are better; the target for a single local memory operation on a full warp is 1 transaction for a 4byte access, 2 transactions for an 8byte access, and 4 transactions for a 16byte access. The Transaction Size for local memory traffic between the warp and the L1 cache is equal to a full L1 cache line size; a L1 cache line is 128 bytes in size. Note that a full cache line is communicated no matter if all of the included data is requested by the threads of the warp or only a subset is requested.
|
Analysis
-
If the number of Load/Store Requests is high …
-
… run the Memory Transactions experiment to locate the source code lines that trigger local memory operations. Try to investigate which of the previously discussed reasons caused the compiler to use local data accesses.
-
… go to the Occupancy experiment and check if this kernel is register limited and/or uses a very high number of registers. Compile the kernel with the
--ptxas-options=-v option and focus on how many registers needed to be spilled. Try to reduce the number of spilled registers to reduce the overall number of local memory operations.
-
… run the Issue Efficiency experiment and investigate if more eligible warps are available at runtime than necessary for hiding the kernel's instruction/data latencies. If so, consider trading active warps in favor of having more resources available per block - even if this might lower the kernel's occupancy.
-
If the number of Transactions Per Request is high …
-
… check the used memory access patterns and try to optimize the data accesses focusing on the coalescing rules of the target compute device (see the Global Memory sections of the CUDA C Programming Guide for more details). Keep in mind that local memory is organized such that consecutive 32-bit words are accessed by consecutive thread IDs. In other words: Ideal local memory accesses are using the very same offset into each thread's local memory window; that way, all threads of a warp access data that is stored consecutively in device memory. Using different offsets for the threads of a warp will always result in multiple transactions per request.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.