NVIDIA® Nsight™ Development Platform, Visual Studio Edition 4.7 User Guide
Send Feedback
The Memory Transactions source-level experiment provides detailed statistics for each instruction that performs memory transactions. If a kernel is limited by memory bandwidth, fixing inefficient memory access can improve performance. This experiment makes it easy to find which instructions are making memory accesses that incur large numbers of transactions, and could potentially be improved. Patterns to start optimizing first are those which transfer more bytes than are requested, or incur more transactions than the ideal number.
When a warp executes an instruction that accesses memory, it is important to consider the access pattern created by the threads in that warp. For example, when loading data through the L1 cache, an entire 128-byte cache line is fetched, regardless of whether one thread is reading one value (the least efficient pattern), or if all 32 threads are reading consecutive 4-byte values (the most efficient pattern). A memory "request" is an instruction which accesses memory, and a "transaction" is the movement of a unit of data between two regions of memory. Efficient access patterns minimize the number of transactions incurred by a request. Inefficient patterns make large numbers of transactions, using only a small amount of data from each transaction, wasting bandwidth in the connections between regions of the Memory Hierarchy. See the Memory Statistics family of kernel-level experiments for more background.
Memory space that was accessed in this operation. Memory spaces are Global, Local, and Shared. If the instruction is a generic load or store, different threads may access different memory spaces, so lines marked Generic list all spaces accessed.
Type of memory operations executed (Load or Store).
Memory access size of a single access in bits.
Distribution of executed L1 memory transactions per instruction executed. Bins with a non-zero count have gray bars, and the highest bin has a red bar. A good histogram has only counts in the lower bins. The number of bins is selected to allow up to the worst case number of transactions, which varies depending on the memory type and access size. For global and shared memory accesses, there are always 32 bins, because each thread in a warp can read from a different location, incurring a separate transaction per thread. Local accesses of up to 4 bytes per thread have 32 bins for the same reason. Since local memory is strided in 4-byte segments, 8-byte local accesses require 2 transactions per thread and will have 64 histogram bins, and 16-byte local accesses require 4 transactions per thread and will have 128 histogram bins.
Number of executed 128-byte memory transactions between the SM and L1 due to Global memory accesses.
Number of executed 128-byte memory transactions between the SM and L1 due to Local memory accesses.
Number of executed transactions between the SM and shared memory. One or more transactions occur each time a warp executes a shared memory instruction. Multiple transactions can occur from a single executed instruction due to bank conflicts or writing values that are too wide to access via a single bank (64- and 128-bit). Note that the shared memory banking configuration (which is controllable on Kepler, but fixed on older and newer architectures) affects the number of transactions required for different shared memory access patterns involving 64- and 128-bit loads and stores.
If the value of Shared Transactions Executed is much higher than the number of shared memory instructions executed, consider reorganizing data in shared memory to avoid bank conflicts, or to allow using 32-bit accesses instead of 64- or 128-bit accesses.
Hypothetical number of 128-byte memory transactions between SM and L1 due to Global memory accesses for an ideal access pattern using the instruction’s data width. The calculation assumes the threads in a warp contiguously access a cache-line-aligned array of data elements having the specified width. The predication and active masks are taken into account, so having fewer enabled threads can reduce the ideal number of transactions (the Instruction Count experiment can show enabled threads). When threads access unaligned or sparse data, executed transactions will be greater than ideal transactions. When threads in a warp access the same data, executed transactions can be less than ideal transactions.
Hypothetical number of 128-byte memory transactions between SM and L1 due to Local memory accesses for an ideal access pattern using the instruction’s data width. The calculation assumes the threads in a warp access the same address, which (due to the 4-byte striping of local addresses to generic addresses) results in a cache-line-aligned array of data. The instruction’s data width directly affects the number of transactions: 32-bit or smaller accesses to the same local address occur within a single cache line, 64-bit accesses take two cache lines, and 128-bit accesses take four cache lines. The predication and active masks have no effect on this. When threads in a warp access different local addresses, executed transactions will be greater than ideal transactions. For local memory, executed transactions cannot be less than ideal transactions, because there is no way for local accesses to overlap in such a way as to require accessing fewer cache lines.
Number of shared memory transactions hypothetically necessary, if the instruction were using an access pattern with no bank conflicts. The calculation of ideal transactions is based on sequential data and takes the predication mask and the active mask into account. For data widths up to 32-bit, all 32 threads in a warp can access separate shared memory banks using a single transaction. For ideal 64- and 128-accesses, more transactions may be necessary (the exact value depends on the shared memory banking configuration).
Total executed memory instructions (per thread), regardless predicate or condition code.
Total executed memory instructions (any semantics per warp) regardless predicate or condition code.
Amount of data requested in bytes; summed across the active threads that are not predicated off.
Amount of data transferred between the SM and L1 in bytes.
Amount of data transferred between L1 and L2 in bytes.
Number of executed 32-byte transactions between L1 and L2 due to Global memory accesses.
Number of executed 32-byte transactions between L1 and L2 due to Local memory accesses.
Number of 128-byte transactions required between the SM and L1 per request made. Lower is better.
Number of 32-byte transactions required between L1 and L2 per request made. Lower is better.
Number of transactions between the SM and L1 that exceeded the hypothetical ideal number of transactions. When threads access unaligned or sparse data, this will be greater than zero. When threads in a warp access the same global data, this value can be negative. The value is derived from other columns:
(L1 Global Transactions Executed + L1 Local Transactions Executed) — (L1 Global Transactions Ideal + L1 Local Transactions Ideal)
See the descriptions of those columns for more information.
The ratio of bytes transferred between the SM and L1 to bytes requested. L1 transfers occur only in cache-line-sized 128-byte transactions, so this value is derived from other columns:
128 * (L1 Global Transactions Executed + L1 Local Transactions Executed) / (Bytes Requested)
If access patterns do not request all the bytes in the cache lines accessed (due to unaligned or sparse data), this value will be greater than 1.0. When threads in a warp access the same global data, this value can be less than 1.0, because Bytes Requested (the product of instruction data width and number of enabled threads) assumes all threads are requesting different data.
Number of bytes actually transferred between L1 and L2 for each requested byte in L1. Lower is better.
Many of the metrics provided by this experiment can imply a general problem: If the amount of data transferred between any two memory regions exceeds the amount of data requested, the access pattern is not optimal. This may appear as L1/L2 Transfer Overhead, or a high value of Transactions Per Request. See the Memory Statistics family of kernel-level experiments for analysis guidance.
Shown below is an example CUDA program which can be pasted into a .cu file, compiled for Release, and profiled in NVIDIA Nsight with the Memory Transactions experiment on a Kepler GPU to produce the results in the screenshots. The three kernel launches in the example each have 32 threads in a single block, which is exactly one warp. All three perform the same simple pattern: Perform a 128-bit (i.e. 16-byte, or 4-float) store to the elements of an array in global memory, first with one thread, then with two threads, etc., up to all 32 threads of the warp. This makes it easy to see the consequences of having fewer enabled threads on the number of transactions.
Since each store instruction is executed one time on one warp, the relationships between the columns are clear:
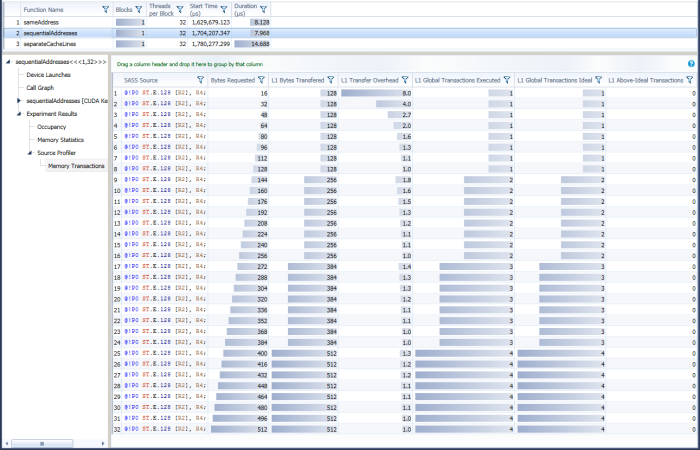
In this code example, the access pattern is controlled by the index parameter to the store function. For sequentialAddresses, the thread index is directly used as the array index, so all threads store to adjacent elements in an array of 128-bit values. Note that L1 Global Transactions Executed always matches L1 Global Transactions Ideal for this kernel, and that for 8/16/24/32 threads the overhead is 1.0 because all the bytes in every cache line were accessed.
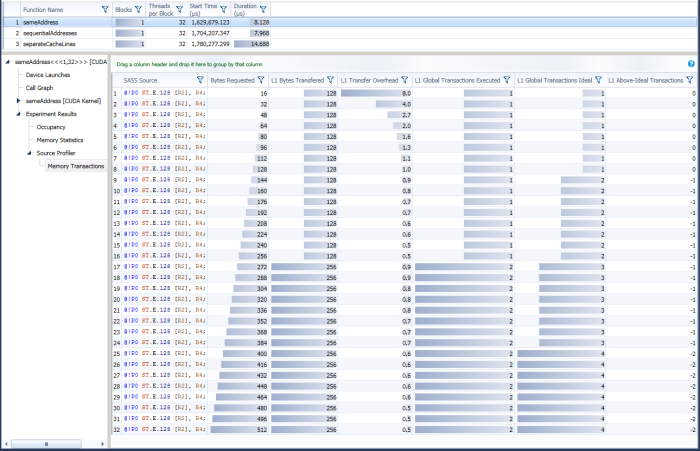
For sameAddress, index is 0 for all threads, so all threads store to the same address. Note that L1 Global Transactions Ideal is 1 for up to 16 threads, because (on Kepler) the maximum in a single transaction for 16-byte accesses is 16 threads. Thus, for a full warp doing 16-byte accesses, the fewest number of transactions is 2, and this is less than the "ideal" value of 4 because ideal assumes all threads are accessing different data while this kernel has the threads accessing the same data. Note that L1 Above-Ideal Transactions is negative in this case, and L1 Transfer Overhead is 0.5 because only 256 bytes (2 128-byte transactions) were needed to store 512 bytes (16 bytes from 32 threads).
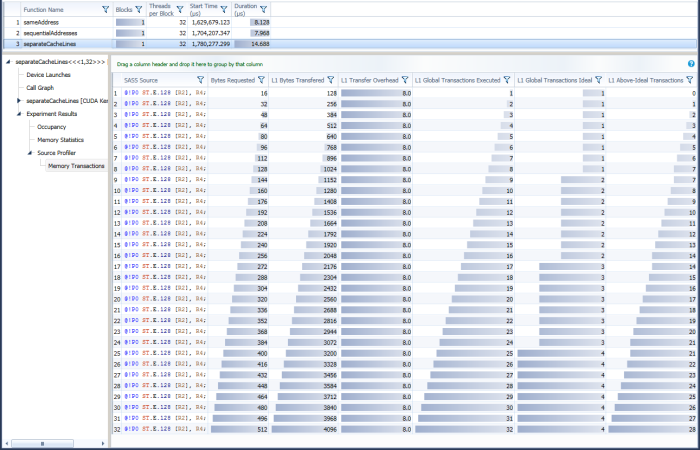
For separateCacheLines, index is computed by scaling up the thread index such that each thread stores to the first 16 bytes of a separate 128-byte cache line. This is an example of the least efficient way to access GPU memory, and should be avoided. Note that each thread doing a store incurs a full 128-byte transaction, despite only accessing 16 bytes, so L1 Transfer Overhead is always a factor of 8. Also note that for the full warp, L1 Above-Ideal Transactions is 28 because 32 transactions were executed where an ideal access pattern would only have executed 4 transactions.
__device__ void store(float4* values, int id, int index)
{
// Generate 32 different store instructions, the first done only on the first thread,
// the next done only on the first two threads, etc. and the last done on all threads.
#pragma unroll
for (int numThreads = 1; numThreads <= 32; ++numThreads)
if (id < numThreads)
values[index] = float4(); // Store a dummy value
}
__global__ void sameAddress (float4* values) { store(values, threadIdx.x, 0); }
__global__ void sequentialAddresses(float4* values) { store(values, threadIdx.x, threadIdx.x); }
__global__ void separateCacheLines (float4* values) { store(values, threadIdx.x, threadIdx.x * 128 / sizeof(float4)); }
int main()
{
// Allocate enough for worst case example: all 32 threads in the warp access a
// different 128-byte cache line.
float4* values = 0;
cudaMalloc((void**)&values, 32 * 128);
// Launch example kernels with one warp.
sameAddress <<<1,32>>>(values); // All threads access same element
sequentialAddresses<<<1,32>>>(values); // Threads access sequential elements ("ideal")
separateCacheLines <<<1,32>>>(values); // Each thread accesses a different 128-byte sector
cudaDeviceSynchronize();
return 0;
}
SameAddress
SequentialAddress
SeparateCacheLines
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.