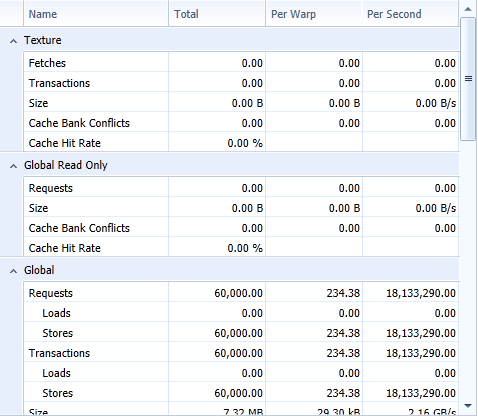
Chart
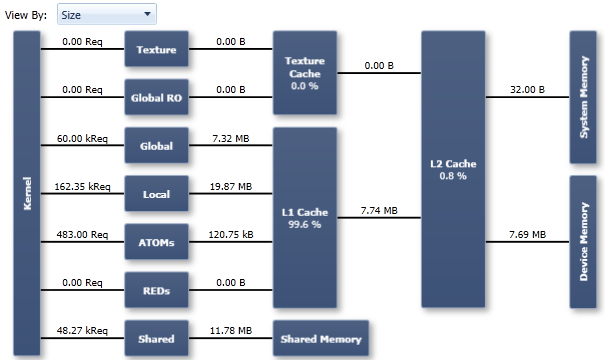
Shows a summary view of the memory hierarchy of the CUDA programming model. Key metrics are reported for the areas that were covered by memory experiments during the data collection; if an area was not covered or the target device does not support a memory data path, the corresponding areas in the chart are greyed out. Useful to get a quick overview of the utilization of the memory sub-system and guide further analysis using the other memory tabs.
The nodes in the diagram depict either a logical memory space (global, local, shared, ...) or an actual hardware unit on the chip (caches, shared memory, device memory). For the various caches the reported percentage number states the cache hit rate; that is the ratio of requests that could be served with data locally available to the cache over all requests made. Requests that hit data in the cache are served much faster than requests that miss the cache; missed data needs to be fetched from another layer of the memory hierarchy.
Links between the nodes in the diagram depict the data paths between the SMs to the memory spaces into the memory system. Depending on the configuration, different metrics are shown per data path; including the amount of memory transferred or the achieved memory throughput.
Options
View By Enables switching the reported metrics per data path. The available options include:
- Size: Reported metrics cover both, read and write operations. The data paths from the SMs to the memory spaces report the total amount of memory requests made; this equals the number of executed memory instructions that triggered a transfer to the corresponding memory space. All other data paths report the total amount of transferred memory in bytes. Note that some caches may only cover read operations; therefore, dividing the combined read/write traffic from before and after a cache does not necessarily match the actual cache hit rate.
- Bandwidth: Reported metrics cover both, read and write operations. Puts the metrics described in the previous section in relation to the kernel execution time. The reported throughput numbers are useful to compare to the architectural peak values.
- Load Size: Reports the same metrics as the first option, but for load operations only. Data paths that by definition do not allow for load traffic do not report a value.
- Store Size: Reports the same metrics as the first option, but for store operations only. Data paths that by definition do not allow for store traffic do not report a value.