Open topic with navigation
Overview
An atomic function performs a read-modify-write atomic operation on one 32-bit or 64-bit word residing in global or shared memory. For example, atomicAdd() reads a word at some address in global or shared memory, adds a number to it, and writes the result back to the same address. The operation is atomic in the sense that it is guaranteed to be performed without interference from other threads. In other words, no other thread can access this address until the operation is complete. If an atomic instruction executed by a warp reads, modifies, and writes to the same location in global memory for more than one of the threads of the warp, each read/modify/write to that location occurs and they are all serialized, but the order in which they occur is undefined.
Global memory atomic operations have dramatically higher throughput on devices of compute capability 3.x than on previous architectures. Algorithms requiring multiple threads to update the same location in memory concurrently have at times on earlier GPUs resorted to complex data rearrangements in order to minimize the number of atomics required. Given the improvements in global memory atomic performance, many atomics can be performed on devices of compute capability 3.x nearly as quickly as memory loads. This may simplify implementations requiring atomicity or enable algorithms previously deemed impractical.
Nsight distinguishes between two classes of operations for atomic functions: Standard atomic operations (ATOMs) return the data value before the atomic operation is applied back to the calling thread. Consequently data traffic is generated in two directions, to and from the L1 cache. In contrast, reductions (REDs) do not have a return value and data is only communicated from the warps to L1. The Source View page can be used to investigate which type of operation is used by the compiler.
Chart
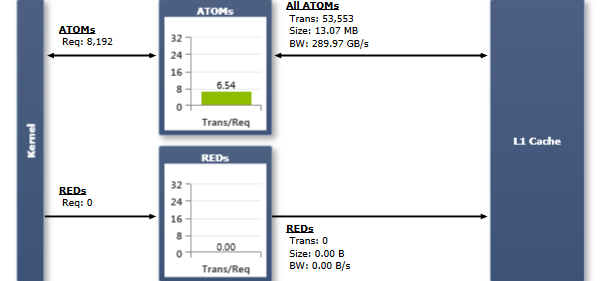
The number of Requests equals the amount of atomic instructions executed. Each request is served by one or more transactions. The actual number of transactions required is dependent on the width of the operation, the accesses memory space (global or shared), and the target compute capability. The applied coalescing rules match the behavior of a memory access to the corresponding memory space (for more details see the discussion of the Global Memory Experiment and the Shared Memory Experiment). In general, the more transactions are necessary, the more unused words are transferred in addition to the words accessed by the threads, reducing the instruction throughput accordingly. In addition, each transaction requires the assembly instruction to be issued again; causing instruction replays if more than one transaction is required to fulfill the request of a warp.
The Transactions Per Request chart shows the average number of L1 transactions required per executed atomic instruction. Lower numbers are better. The optimal target ranges between 1-2 transactions per request. The exact optimal target value is dependent on the mix of atomic instructions executed, i.e. the used memory space and the width of the operations. The Transaction Size for traffic between the warps and the L1 cache is equal to a full L1 cache line size; a L1 cache line is 128 bytes in size.
|
Analysis
-
If the number of Transactions Per Request is high …
-
… check the access pattern of the atomic operations and try to optimize the data accesses focusing on the coalescing rules of the target compute device (see the Global Memory sections or the Shared Memory sections of the CUDA C Programming Guide for more details).
-
If the number of Requests is high …
-
… verify that reductions are used wherever applicable. Reduction operations do not return any data back to the threads, which can save some memory traffic. The Source View page can tell which operations are executed.
NVIDIA GameWorks Documentation Rev. 1.0.150630 ©2015. NVIDIA Corporation. All Rights Reserved.