Step #5: Evaluate the BigNLP Model
The BigNLP scripts include an evaluation harness. It is a simple tool to help evaluate the trained checkpoints. One can evaluate the capabilities of the GPT-3 model on the following ZeroShot downstream evaluation tasks: boolq, hellaswag, lambada, race, piqa, winogrande, wikitext103, and wikitext2.
Use the NGC batch command below to evaluate the data.
ngc batch run \ --name "bignlp_eval_all_126m_bf16" \ --org nv-launchpad-bc \ --team no-team \ --ace nv-launchpad-bc-iad1 \ --instance dgxa100.80g.8.norm \ --replicas 2 \ --array-type PYTORCH \ --image "nvcr.io/nv-launchpad-bc/bignlp-training:22.02-py3" \ --result /results \ --workspace jdoe_workspace:/mount_workspace:RW \ --total-runtime 1h \ --commandline "\ set -x && \ python3 /opt/bignlp/bignlp-scripts/main.py \ run_data_preparation=False \ run_training=False \ run_conversion=False \ run_evaluation=True \ cluster_type=bcp \ bignlp_path=/opt/bignlp/bignlp-scripts \ base_results_dir=/mount_workspace/results \ evaluation.model.vocab_file=/mount_workspace/data/bpe/vocab.json \ evaluation.model.merge_file=/mount_workspace/data/bpe/merges.txt \ evaluation.run.results_dir=/mount_workspace/results/gpt3_126m/eval_all \ evaluation.run.train_dir=/mount_workspace/results/gpt3_126m \ evaluation.model.eval_batch_size=16 \ evaluation.model.checkpoint_name=megatron_gpt*last.ckpt \ evaluation.model.tensor_model_parallel_size=1 \ > >(tee -a /results/eval_bf16_log.txt) 2>&1 && \ find /mount_workspace/results/gpt3_126m/eval_all -name metrics.json -exec cp {} /results/metrics.json \\;"
Locate the results file from NGC batch command.
The results will be saved in a metrics
metrics.jsonfile. The file is copied to the workspace, so either download it from the workspace or from the/resultsdirectory of the job.The ngc batch command produced the following
metrics.json.{ "boolq": { "acc": 0.6048929663608563, "acc_stderr": 0.008550454248280895 }, "hellaswag": { "acc": 0.28211511651065524, "acc_stderr": 0.004491093528113424, "acc_norm": 0.2969527982473611, "acc_norm_stderr": 0.004559817589182073 }, "lambada": { "ppl": 23.718865098431262, "ppl_stderr": 0.8686846521536599, "acc": 0.4075295944110227, "acc_stderr": 0.0068458121817245796 }, "piqa": { "acc": 0.6115342763873776, "acc_stderr": 0.011371877593210252, "acc_norm": 0.6109902067464635, "acc_norm_stderr": 0.011374774974447464 }, "race": { "acc": 0.2727272727272727, "acc_stderr": 0.013783600792343722, "acc_norm": 0.35789473684210527, "acc_norm_stderr": 0.014836467904073716 }, "winogrande": { "acc": 0.5059194948697711, "acc_stderr": 0.014051500838485807 }, "wikitext103": { "word_perplexity": 31.284774148752945, "byte_perplexity": 1.903858863780367, "bits_per_byte": 0.64388280745592 }, "wikitext2": { "word_perplexity": 31.284772851165563, "byte_perplexity": 1.9038588490133912, "bits_per_byte": 0.6438827996995804 } }
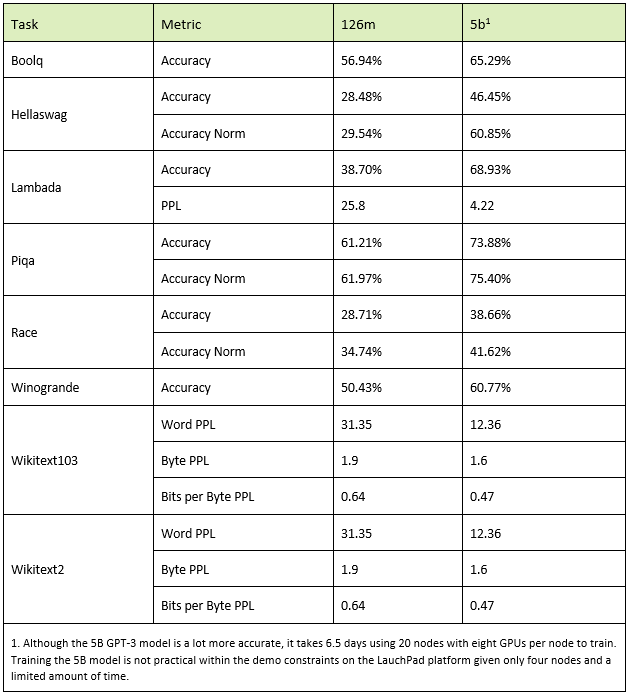
Compare the results in the
metrics.jsonfile to the values in the following table.The results should be within 2% of those in the table.