Step #2: Deploy Triton Inference Server Health
You will now need to start the Triton Inference Server on the VM.
Using the VM Console link on the left-hand navigation pane, open the console.
On your SSH web console using the script below start Triton Inference Server.
sh ~/triton-startup.sh
You will need to keep this window open for the remainder of the lab. If the window is closed, the Triton Server will shut down.
Below are the credentials for the VM in case sudo access is required.
Username: temp
Password: launchpad!
Open the terminal on the Jupyter notebook by clicking the File button in the right hand corner. Click Terminal in the dropdown menu.
Triton HTTP and gRPC service is running on your LaunchPad VM. To check the server’s health, run the curl command from your jupyter lab terminal.
result=$(curl -m 1 -L -s -o /dev/null -w %{http_code} http://localhost:8000/v2/health/ready)
echo $result
It should output 200, which is a code that means OK HTTP.
Using Triton gRPC client to run Inference
Your Jupyter notebook container has the Triton server client libraries, so we will use the container to send inference request to the Trition Inference Server container.
Still from the Jupyter lab terminal:
python /workspace/bert/triton/run_squad_triton_client.py --triton_model_name=bert --triton_model_version=1 --vocab_file=/workspace/bert/data/download/finetuned_large_model_SQUAD1.1/vocab.txt --predict_batch_size=1 --max_seq_length=384 --doc_stride=128 --triton_server_url=localhost:8001 --context="A Complex password should atleast be 20 characters long" --question="How long should a good password generally be?"
The script points to a Triton Server running on localhost on port 8001 (the triton gRPC server). We specify context, i.e., a paragraph which the BERT will use to answer the question (in this case, It is a paragraph from IT help desk about the best practices to use while picking a password. Then you can ask a question to the BERT model in this case it is: What are the common substitutions for letters in password?”)
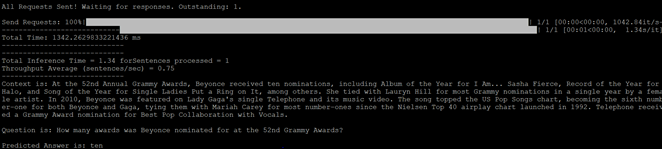
The console output shows that the predicted answer is 20 characters.
If you want to modify the chatbot script, change the –context parameter and –question parameter to your needs. The Question Answering model running on Triton Inference Server should answer your questions accordingly.