DeepStream Technology
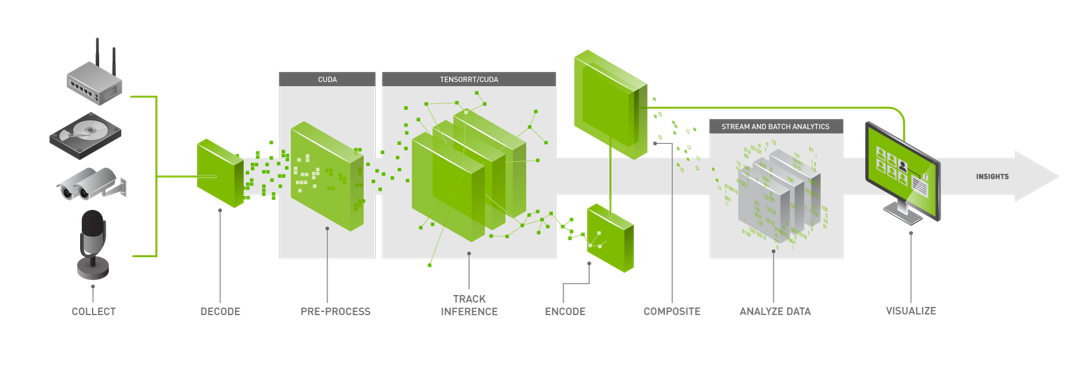
The above figure shows the DeepStream workflow based on a source, infer, and sink model. The streaming data is collected from various sources which are then decoded and preprocessed before sending it to an inference engine. The inference results are post-processed, analytics are run on the results, and are finally sent to various sinks (RTSP, UDP, files, etc).
DeepStream is an optimized graph architecture built using the open source GStreamer framework. The graph below shows a typical video analytic application starting from input video to outputting insights. All the individual blocks are various plugins that are used. At the bottom are the different hardware engines that are utilized throughout the application. Optimum memory management with zero-memory copy between plugins and the use of various accelerators ensure the highest performance.
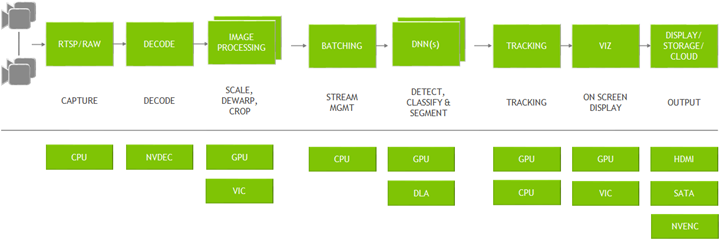
DeepStream provides building blocks in the form of GStreamer plugins that can be used to construct an efficient video analytic pipeline. There are more than 20 plugins that are hardware accelerated for various tasks. For example:
Streaming data can come over the network through RTSP or from a local file system or from a camera directly. The streams are captured using the CPU. Once the frames are in the memory, they are sent for decoding using the NVDEC accelerator. The plugin for decode is called gst-nvvideo4linux2.
After decoding, there is an optional image pre-processing step where the input image can be pre-processed before inference. The pre-processing can be image dewarping or color space conversion. gst-nvdewarper plugin can dewarp the image from a fisheye or 360 degree camera. gst-nvvideoconvert plugin can perform color format conversion on the frame. These plugins use GPU or VIC (vision image compositor).
The next step is to batch the frames for optimal inference performance. Batching is done using the gst-nvstreammux plugin.
Once frames are batched, it is sent for inference. The inference can be done using TensorRT, NVIDIA’s inference accelerator runtime or can be done in the native framework such as TensorFlow or PyTorch using Triton inference server. Native TensorRT inference is performed using gst-nvinfer plugin and inference using Triton is done using gst-nvinferserver plugin. The inference can use the GPU or DLA (Deep Learning accelerator) for Jetson AGX Xavier, Xavier NX, AGX Orin, and Orin NX.
After inference, the next step could involve tracking the object. There are several built-in reference trackers in the SDK, ranging from high performance to high accuracy. Object tracking is performed using the gst-nvtracker plugin.
For creating visualization artifacts such as bounding boxes, segmentation masks, and labels, there is a visualization plugin called gst-nvdsosd.
Finally to output the results, DeepStream presents various options: render the output with the bounding boxes on the screen, save the output to the local disk, stream out over RTSP or just send the metadata to the cloud. For sending metadata to the cloud, DeepStream uses gst-nvmsgconv and gst-nvmsgbroker plugin. gst-nvmsgconv converts the metadata into schema payload and gst-nvmsgbroker establishes the connection to the cloud and sends the telemetry data. There are several built-in broker protocols such as Kafka, MQTT, AMQP and Azure IoT. Custom broker adapters can be created.
Python is easy to use and widely adopted by data scientists and deep learning experts when creating AI models. NVIDIA introduced Python bindings to help you build high-performance AI applications using Python. DeepStream pipelines can be constructed using Gst-Python, the GStreamer framework’s Python bindings.
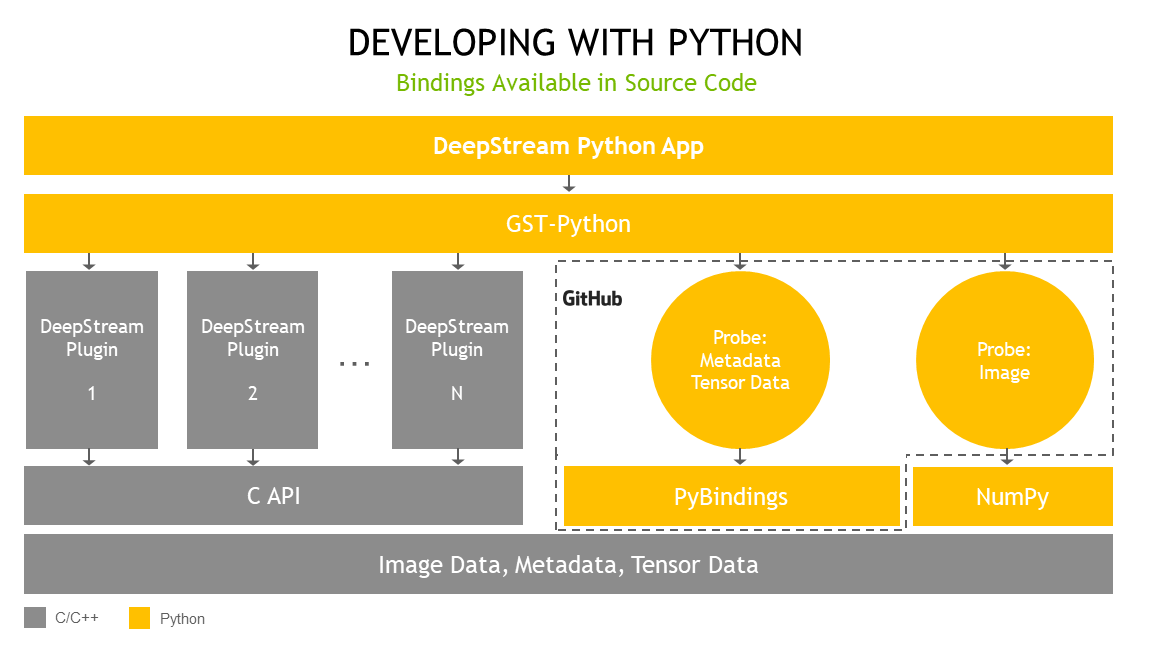
The DeepStream Python application uses the Gst-Python API action to construct the pipeline and use probe functions to access data at various points in the pipeline. The data types are all in native C and are exposed to the Python API through Python bindings. Python bindings are written using Pybind11 and are publicly available in the deepstream_python_apps repository.