Real-time Speech AI APIs
NVIDIA Riva is a GPU-accelerated SDK (software development kit) for building Speech AI applications that can be customized for your use case and can deliver real-time performance.
Giving voice commands to an interactive virtual assistant, converting audio to subtitles on a video online, and transcribing customer interactions into text for archiving at a call center are all use cases for Automatic Speech Recognition (ASR) systems.
With deep learning, the latest speech-to-text models are capable of recognition and translation of audio into text in real time! Good models can perform well in noisy environments, are robust to accents and have low word error rates (WER).
How does ASR work?
There are three primary components of an ASR pipeline:
- Feature Extraction
Audio is resampled to convert it to a discrete format. Traditional signal preprocessing techniques are applied, such as standardization, windowing, and conversion to a machine-understandable form by spectrogram transformation.
- Acoustic Modeling
Acoustic models can be of various types and with different loss functions, but some of the most commonly used in research literature and production are Connectionist Temporal Classification (CTC) based models. Examples of CTC models include Conformer-CTC, NVIDIA’s Citrinet, and QuartzNet. These consider the spectrogram as input and produce the log probability scores of all different vocabulary tokens for each time step.
- Decoder with Language Modeling
After the accoustic model assigns a probability to each token, a decoding algorithm takes these probabilities and post-processes them to select the best token fit for that time step. Greedy decoding and beam-search have been the popular algorithms used for this up until language model based decoding got introduced. Language models are used to add contextual representation about the language, and finally correct the acoustic model’s mistakes. It tries to determine the context of speech by combining the knowledge from acoustic model (what it understands) with calculating the probability distribution over sequence for next possible word.
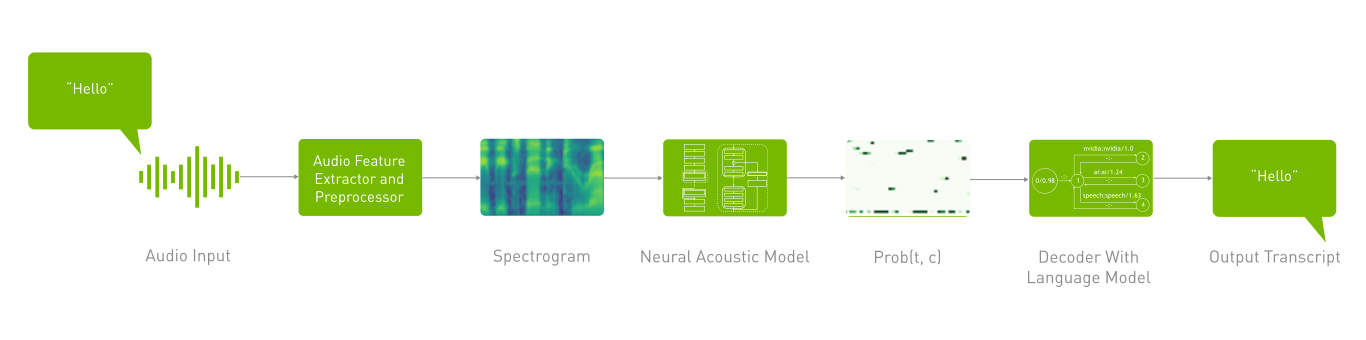
Riva ASR
NVIDIA Riva offers out-of-the-box world-class ASR that can be customized for any domain or deployment platform. The service handles hundreds to thousands of audio streams as input and returns streaming transcripts with minimal latency.
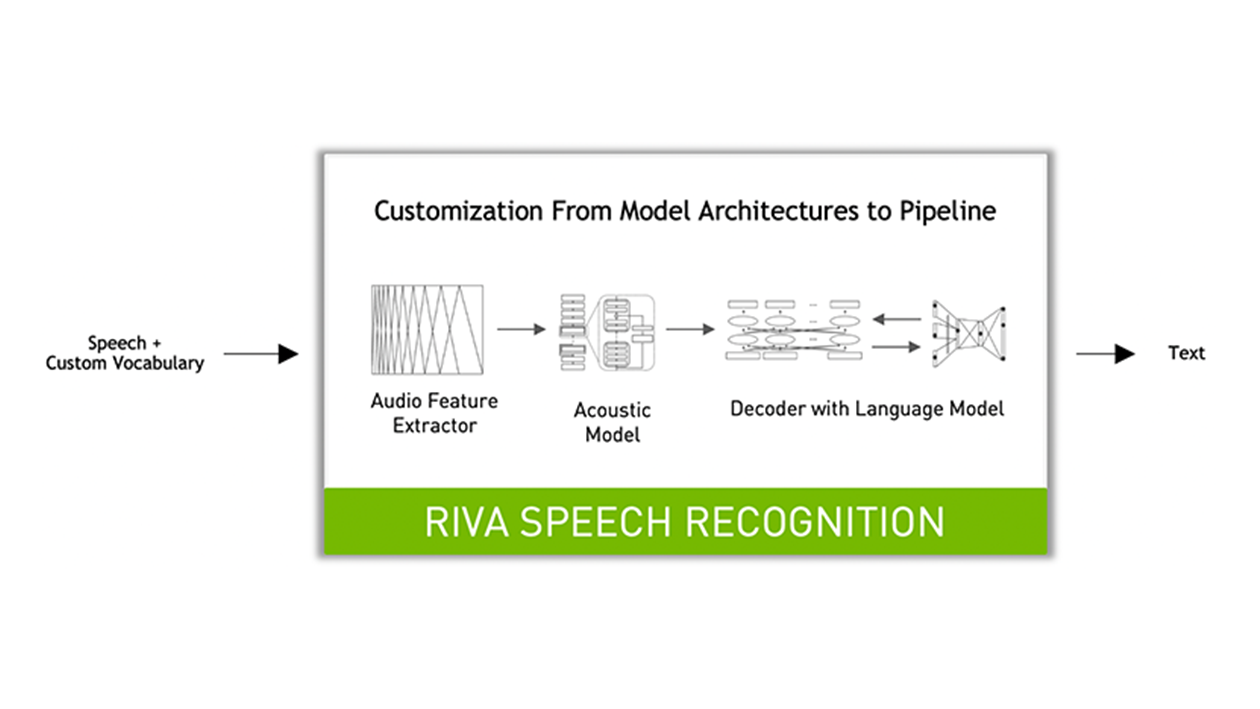
The key features include:
Support for multiple model architectures (QuartzNet, Conformer etc.) and for different deployment environments (on-prem, cloud, etc.).
Models trained for hundreds of thousands of hours on NVIDIA DGX.
Support for English, Spanish, German, and Russian as of August 2022. This list is expanding month by month.
Automatic punctuation.
Word-level timestamps.
Word boosting.
Inverse text normalization to improve readability of output (e.g., two hundred dollars transcribes to $200).
TensorRT optimizations to minimize latency and maximize throughput.
Text-to-Speech (TTS) or Speech Synthesis is the task of artificially producing human speech from a raw transcript. Combining TTS with deep learning provides synthesized waveforms that can sound very natural, almost undistinguishable from how a human would speak. These TTS models can be used in cases when an interactive virtual assistant responds, or when a mobile device converts text from a webpage to speech for accessibility reasons.
How does TTS work?
There are two primary components of a TTS pipeline:
- Text Normalization and Preprocessing
Which includes text normalization ( e.g., $200 to two hundred dollars) and other techniques such as parts of speech tagging.
- Spectrogram Generator
This model transforms the text into time-aligned features such as spectrogram, mel spectrogram, or F0 frequencies and other acoustic features. We use architectures like Tacotron and FastPitch in this step.
- Vocoder
This model converts the generated time aligned spectrogram representation into continuous human-like audio. Examples include WaveGlow and HiFiGAN.
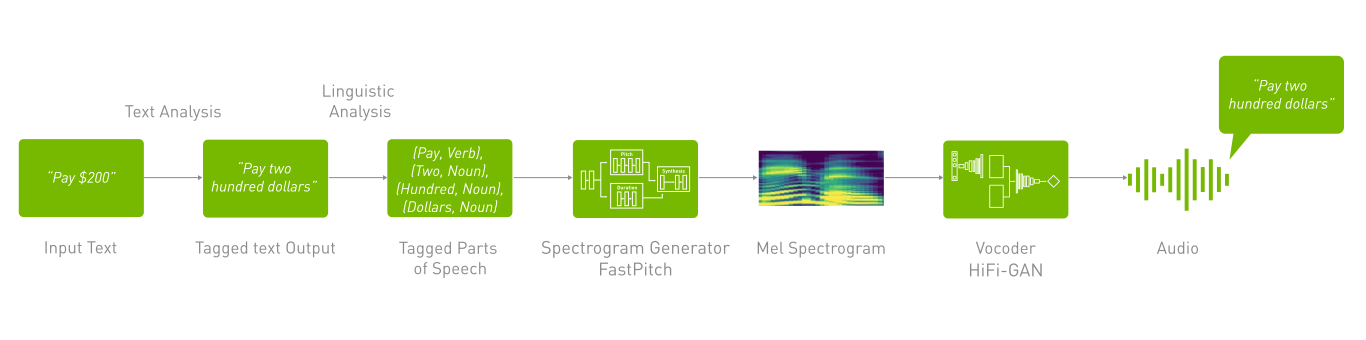
As shown in the above diagram, a mel spectrogram is generated using the FastPitch model and then speech is generated using the “Vocoder” HiFiGAN model. This pipeline forms a text-to-speech system that enables you to synthesize natural sounding speech from raw transcripts without any additional information such as patterns or rhythms of speech.
For new users, it is recommended to start with a combination of FastPitch and HiFi-GAN models.
- FastPitch
FastPitch is the recommended fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference and generates speech that can be further controlled with predicted contours. FastPitch can therefore change the perceived emotional state of the speaker or put emphasis on certain lexical units.
- HiFi-GAN
HiFi-GAN achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, HiFi-GAN models periodic patterns of an audio for enhancing sample quality. It synthesises audio similar to human quality faster than real time.
Riva TTS
Riva offers human-like text-to-speech (TTS) neural voices that use state-of-the-art spectrogram generation and vocoder models. Riva pipelines are customizable and optimized to run efficiently in real-time on GPUs. Riva TTS takes raw text as input and can return audio chunks as output.
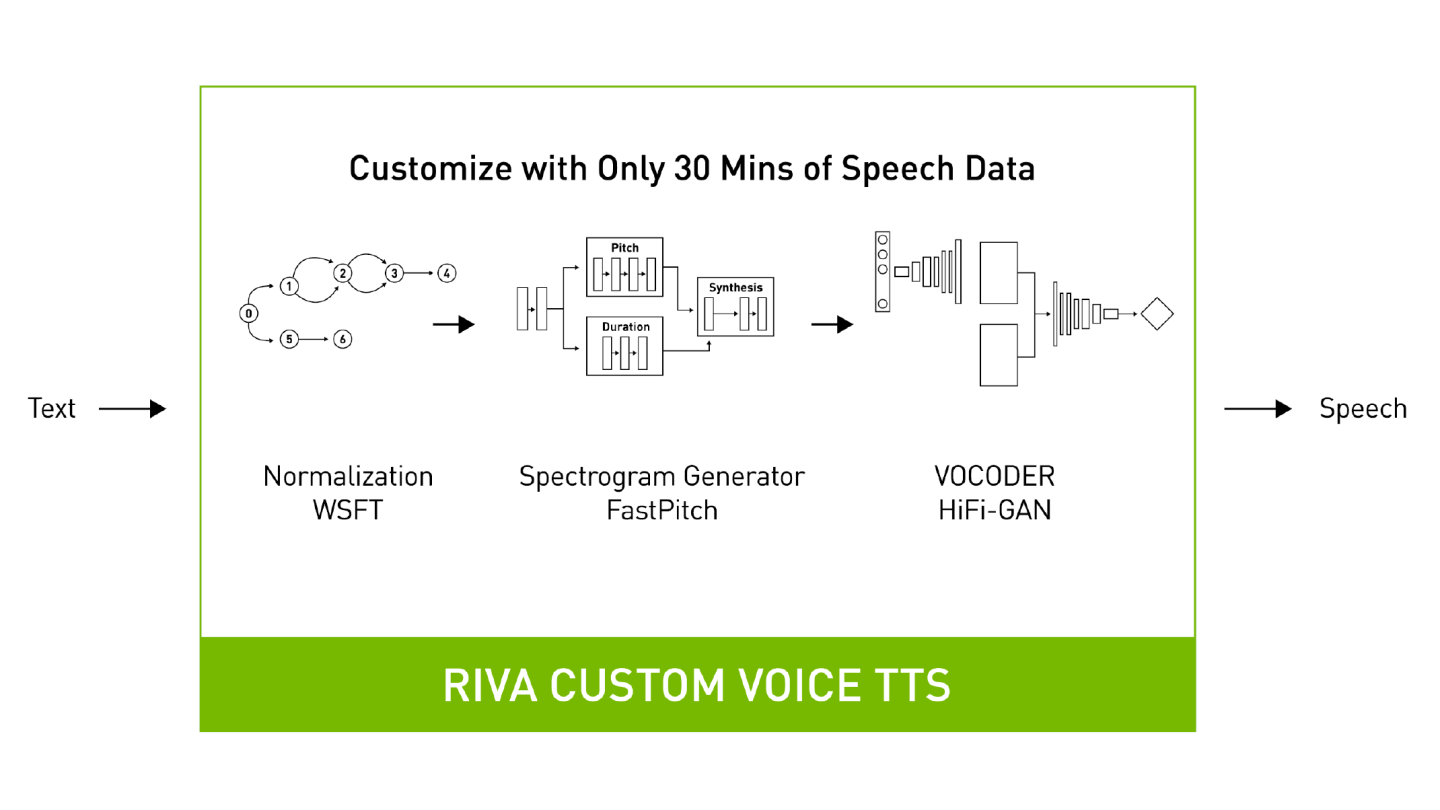
The key features include:
State-of-the-art models that generate expressive neural voices.
A robust pipeline that makes it possible to fine tune voice and accent easily.
Fine-grained control on voice pitch and duration for expressivity.
TensorRT optimizations to minimize latency and maximize throughput