Customizing Riva Speech Recognition
In this lab, we will explore customization techniques that can improve the recognition of specific words in Riva, such as:
Proper names: people’s names, product and brand names, street names in addresses…
Narrow domain terminologies
Abbreviations
Various customization techniques can assist when out-of-the-box Riva models fall short of dealing with challenging scenarios not likely seen in their training data.
The Riva lab will use two important links from the left-hand navigation pane throughout the course of the lab.
Please use Chrome or Firefox when trying the customization techniques in this lab. The Web Audio APIs used to handle audio in the application works best with these browsers.
The Riva Quick Start scripts allow you to easily deploy preconfigured ASR pipelines that are very accurate for most applications. However, some of the techniques covered in this lab require configuring the Riva Speech Recognition pipeline using tools like Riva Servicemaker tools like riva-build and riva-deploy.
As a primer for the customization strategies we present in this lab, you will deploy a Riva Speech Recognition pipeline using the Riva Quick Start Guide and models from NVIDIA NGC. This is a pre-requisite to follow the rest of the lab, and you will tinker with this pipeline as you go along.
Go to the Jupyter Notebook pane on the left-hand navigation pane, and follow the 1_deploy_speech_recognition_pipeline.ipynb notebook.
The following flow diagram shows the Riva speech recognition pipeline along with the possible customizations.
Raw temporal audio signals first pass through a feature extraction block, which segments the data into blocks (say, of 80 ms each), then converts the blocks from temporal domain to frequency domain. This data is then fed into an acoustic model, which outputs probabilities over text tokens at each time step. A decoder converts this matrix of probabilities into a sequence of text tokens, which is then detokenized into an actual sentence (or character sequence). An advanced decoder can also do beam search and score multiple possible hypotheses (i.e. sentences) in conjunction with a language model. The decoder output comes without punctuation and capitalization, which is the job of the Punctuation and Capitalization model. Finally, Inverse Text Normalization (ITN) rules are applied to transform the text in verbal format into a desired written format.
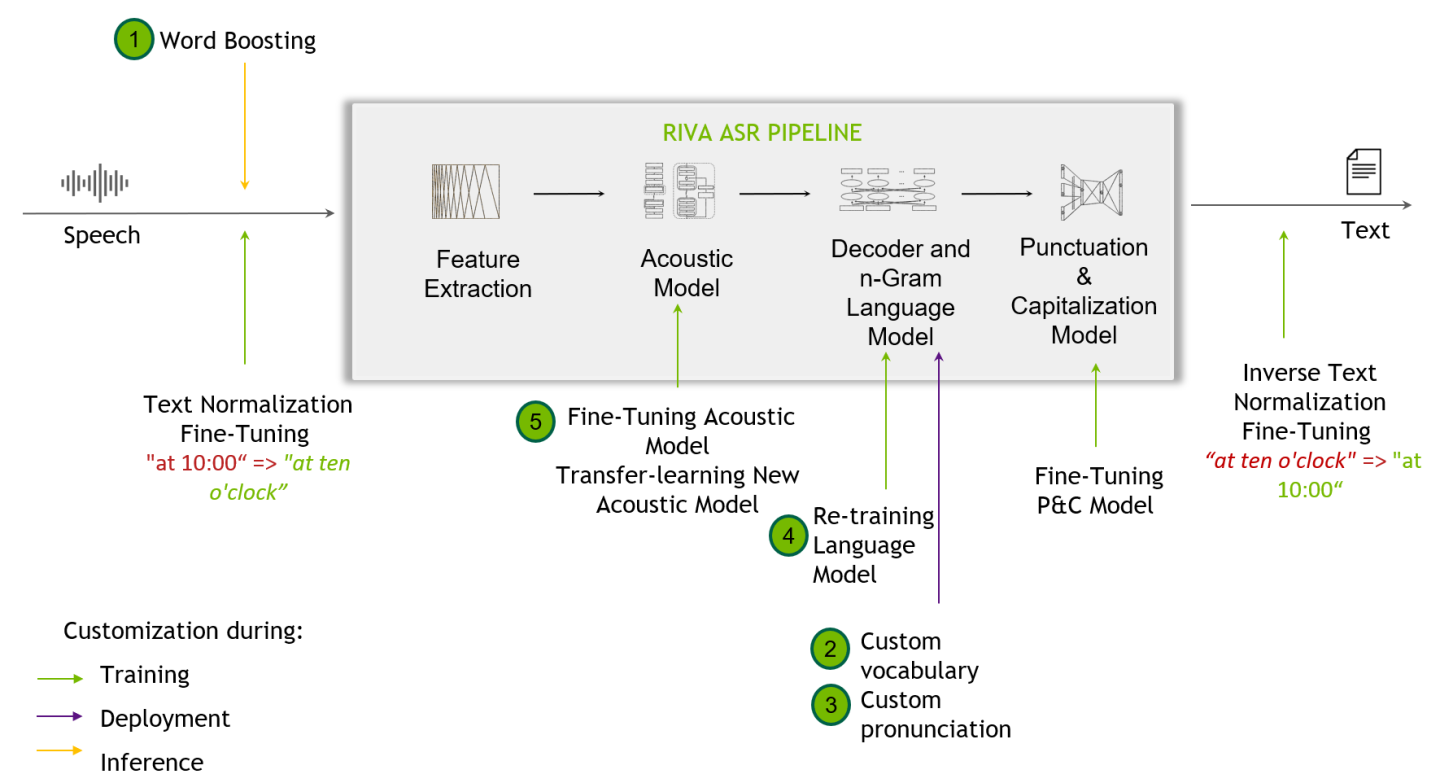
To improve the recognition of specific words, use the following customizations. They are listed in increasing order of difficulty and effort:
Techniques |
Dificulty |
What it does |
When to use |
|---|---|---|---|
Word boosting |
Quick and Easy |
Temporarily extend the vocabulary while increasing the chance of recognition for a provided list of words. |
When you know that certain words or phrases are important. |
Custom vocabulary |
Easy |
Permanently extend the default vocabulary to cover novel words of interest. |
When the default model vocabulary does not sufficiently cover the domain of interest. |
Custom pronunciation (Lexicon mapping) |
Easy |
Explicitly guide the decoder to map one or more pronunciations (sequences of tokens) to a specific word |
When you know a word can have one or several pronunciations. |
Retrain language model |
Moderate |
Train a new language model for the application domain to improve the recognition of domain specific terms. |
When domain text data is available. |
Fine tune an existing acoustic model |
Moderately hard |
Fine tune an existing acoustic model using a small amount of domain data to better suit the domain. |
When transcribed domain audio data is available (10h-100h), and other easier approaches fall short. |
Of all the adaptation techniques, word boosting is the easiest and quickest to implement. Word boosting allows you to bias the ASR engine to recognize particular words of interest at request time, by giving them a higher score when decoding the output of the acoustic model. All you need to do is to pass a list of words of importance to the model along with a weight as extra context to the API call, as per the below example.
# Word Boosting
boosted_lm_words = ["BMW", "Ashgard"]
boosted_lm_score = 20.0
# Adding the boosted word parameters to the riva client
riva.client.add_word_boosting_to_config(config, boosted_lm_words, boosted_lm_score)
Word boosting provides a quick and temporary, on-the-spot adaptation for the model to cope with new scenarios, such as recognizing proper names and products, or domain specific terminologies. Word boosting also supports out-of-vocabulary (OOV) words, in such cases, it temporarily extends the vocabulary and provide boosting for the new words.
You will have to explicitly specify the list of boosted words at every request. Other adaptation methods such as custom vocabulary and lexicon mapping provide a more permanent solution, which affects every subsequent request.
Pay attention to the followings while implementing word boosting:
Word boosting can improve the chance of recognition of the desired words, but at the same time can increase false positives. As such, start with a small positive weight and gradually increase till you see positive effects. As a general guide, start with a boosted score of 20 and increase up to 100 if needed.
Word boosting is most suitable as a temporary fix for a new situation. However, if you wish to use it as a permanent adaptation, you can attempt binary search for the boosted weights while monitoring the accuracy metrics on a test set. The accuracy metrics should include both the word error rate (WER) and/or a form of term error rate (TER) focusing on the terms of interest.
To learn about Word Boosting with Riva, go to the Jupyter Notebook pane on the left-hand navigation pane, and go through the 2_word_boosting.ipynb notebook.
There are two decoders supported in Riva.
The greedy decoder (available during the riva-build process under the flag
--decoder_type=greedy) is a simple decoder, that simply outputs the token with the largest probability at each time step. It is not vocabulary based and hence can produce any character sequence or word.The Flashlight decoder, deployed by default in Riva, is a more advanced decoder, that can perform beam search. It is a lexicon-based decoder and only emits words that are present in the provided vocabulary file. That means, domain specific words that are not present in the vocabulary file will have no chance of being generated.
For the default Flashlight decoder, there are two ways to expand the decoder vocabulary:
At Riva build time: When building a custom model. Passing the extended vocabulary file to the –decoding_vocab=<vocabulary_file> parameter of the riva-build command. Out of the box vocabulary files for Riva languages can be found on NGC, for example, for English, the vocabulary file named flashlight_decoder_vocab.txt can be found at this link .
After deployment: For a production Riva system, the lexicon file can be modified, extended and will take effect after a server restart. See the next section.
The exercise for this section is merged with the exercise on Lexicon mapping.
When using the Flashlight decoder, the lexicon file provides a mapping between vocabulary dictionary words and its pronunciation, which is sentence piece tokens for many Riva models.
Modifying the lexicon file serves two purposes:
Extend the vocabulary.
Provide one or more explicit custom pronunciations for a specific word.
Go to the Jupyter Notebook pane on the left-hand navigation pane, and follow the notebook on customizing vocabulary and lexicon mapping 3_customize_vocabulary_and_lexicon_mapping.ipynb for a step-by-step procedure.
A language model (LM) estimates the likelihood of observing a text sequence in the text corpus it is trained on. Introducing a new language model to an existing ASR pipeline is another approach to improve accuracy for niche settings. Riva supports n-gram language models trained and exported from either NVIDIA TAO Toolkit or KenLM.
An n-gram language model estimates the probability distribution over groups of n or less consecutive words. By altering or biasing the data on which a language model is trained on, and thus the distribution it is estimating, it can be used to predict different transcriptions as more likely, and thus alter the prediction without changing the acoustic model. A language model must be used in conjunction with an advanced decoder, like Flashlight, which inspects multiple hypotheses and use the language model score in conjunction with the acoustic model score to weight these hypotheses.
Note that currently TAO and Nemo only trains LM from scratch, as such, you should ensure a substantial amount of domain text is available for training. In addition, when the text belongs to a narrow, niche domain, there might be an impact to the overall ASR pipeline in recognizing general domain language, as a trade-off. Therefore, you should experiment with mixing domain text with general text for a more balanced representation.
You should limit vocabulary size if using scraped text. Many online sources contain typos or ancillary pronouns and uncommon words. Removing these can improve the language model.
Go through the notebooks 4_tao-ngram-pretrain.ipynb to learn how to pretrain and deploy an ngram language model with Tao and Riva tools.
You can refer to the Riva documentation for further details.
When other easier approaches have failed to address accuracy issues in challenging situations brought about by significant acoustic factors, such as different accents, noisy environments or audio quality, fine-tuning acoustic models should be attempted.
We recommend fine-tuning ASR models with sufficient data approximately on the order of 100 hours of speech or more, as shown in this research paper
Go through the notebooks 5_finetune-am-citrinet-tao-finetuning.ipynb and 6_finetune-am-citrinet-tao-deployment.ipynb to learn how to finetune and deploy a Citrinet acoustic model with Riva tools.
In case of smaller datasets, such as ~10 hours, appropriate precautions should be taken to avoid overfitting to the domain and hence sacrificing significant accuracy in the general domains, aka. “catastrophic forgetting”. In transfer learning, continual learning is a sub-problem wherein models that are trained with new domain data should still retain good performance on the original source domain.
If fine-tuning is completed on a small dataset, mix it with other larger datasets (“base”). For English for example, Nemo has a list of public datasets that it can be mixed with.
If using NeMo to fine-tune ASR models, you refer to this Nemo tutorial. This tutorial with NeMo is great for reference, but not required as part of this lab.
Use lossless audio formats if possible. The use of lossy codecs such as MP3 can reduce quality. As a common practice, use a minimum sampling rate of 16 kHz if possible.
Augment training data with noise can improve the model ability to cope with noisy environments. Adding background noise to audio training data can initially decrease accuracy, but increase robustness.
End-to-end training of ASR models requires large datasets and heavy compute resources. There are more than 5,000 languages around the world, but very few languages have datasets large enough to train high quality ASR models.
For this reason, we only recommend training models from scratch where several thousands of hours of transcribed speech data is available.
Riva offers a rich set of customization techniques that you can use to help improve out-of-the-box performance when faced with novel and challenging situations, not yet covered in the training data.