Customizing Riva Speech Synthesis
In this tutorial, we will explore the customization techniques that can modify the characteristics of audio or improve the quality of voice synthesized by Riva, such as:
Controlling the pitch, rate, pronunciation and volume.
Replace the pronunciation of a specific word or phrase with a different word or phrase.
Add a new language
Various customization techniques can assist to modify the output from Riva models as per the use-case.
The Riva lab will use two important links from the left-hand navigation pane throughout the course of the lab.
Please use Chrome or Firefox when trying the customization techniques in this lab. The Web Audio APIs used to handle audio in the application works best with these browsers.
The Riva Quick Start scripts allow you to easily deploy preconfigured TTS pipelines that are very accurate for most applications. However, some of the techniques covered in this lab require configuring the Riva Speech Synthesis pipeline using Riva Servicemaker tools like riva-build and riva-deploy.
As a primer for the customization strategies we present in this lab, you will deploy a Riva Speech Synthesis pipeline using the Riva Quick Start Guide and models from NVIDIA NGC. This is a pre-requisite to follow the rest of the lab, and you will tinker with this pipeline as you go along.
Go to the Jupyter Notebook pane on the left-hand navigation pane, and follow the 1_deploy-speech-synthesis-pipeline.ipynb notebook.
The TTS service in Riva is based on a four-stage pipeline. These four stages are visually represented and explained below:
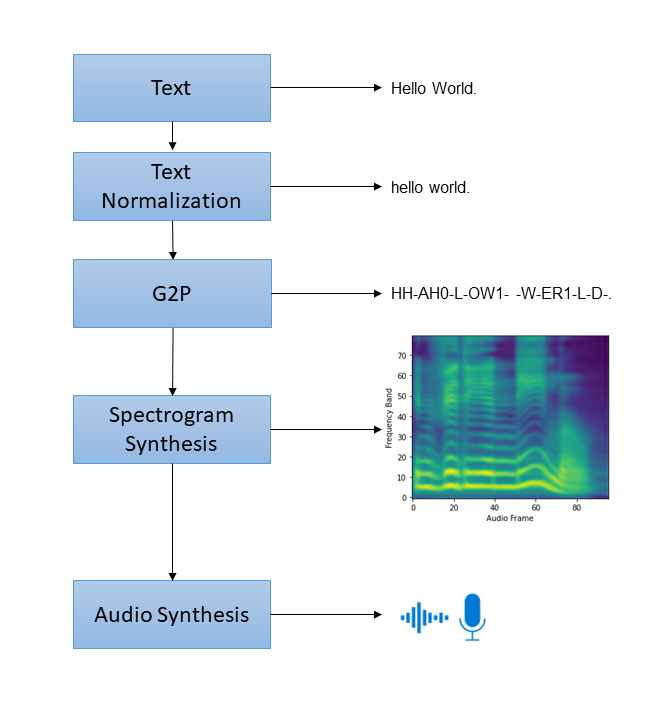
Text Normalization: Converting raw text to spoken text (eg. “Mr.” → “mister”).
Grapheme to Phoneme conversion (G2P): Convert basic units of text (ie. graphemes/characters) to basic units of spoken language (ie. phonemes).
Spectrogram Synthesis: Convert text/phonemes into a spectrogram.
Audio Synthesis: Convert spectrogram into audio. Also known as spectrogram inversion. Models which do this are called vocoders.
While this is the most common structure, there may be fewer or additional steps depending on the use case. For example, some languages do not require G2P and can instead rely on the model to convert raw text/graphemes to spectrogram.
This pipeline forms a text-to-speech system that enables us to synthesize natural sounding speech from raw transcripts without any additional information such as patterns or rhythms of speech.
The following flow diagram shows the Riva speech synthesis pipeline along with the possible customizations.

To control and improve the synthesized speech, use the following customizations. They are listed in increasing order of difficulty and effort:
Techniques |
Difficulty |
What It Does |
When To Use |
|---|---|---|---|
SSML tags |
Quick and easy |
Changes the pitch, rate, volume and pronunciation through phoneme. |
When you want to emphasize or want a particular pronunciation for certain words. |
Training FastPitch and HiFi-GAN |
Hard |
Train the FastPitch and HiFi-GAN models on custom data. |
When you want to add a new language. |
Speech Synthesis Markup Language (SSML) specification is a markup for directing the performance of the virtual speaker. Riva supports portions of SSML, allowing you to adjust pitch, rate, and pronunciation of the generated audio.
Riva TTS supports the following SSML tags:
The
prosodytag supports attributesrate,pitch, andvolume, through which we can control the rate, pitch, and volume of the generated audio.Pitch attribute - Riva supports an additive relative change to the pitch. The pitch attribute has a range of [-3, 3]. This value returns a pitch shift of the attribute value multiplied with the speaker’s pitch standard deviation when the FastPitch model is trained.
Rate attribute - Riva supports a percentage relative change to the rate. The rate attribute has a range of [25%, 250%]. Riva also supports the prosody tags as per the SSML specs.
Volume attribute - Riva supports the volume attribute as described in the SSML specs. The volume attribute supports a range of [-13, 8]dB. Tags
silent,x-soft,soft,medium,loud,x-loud, anddefaultare supported.
Here’s an example of using the
prosodySSML tags during a Riva TTS service call:""" Raw text is "Today is a sunny day. But it might rain tomorrow." We are updating this raw text with SSML: 1. Envelope raw text in '<speak>' tags as is required for SSML 2. Add '<prosody>' tag with 'pitch' attribute set to '2.5' 3. Add '<prosody>' tag with 'rate' attribute set to 'high' 4. Add '<volume>' tag with 'volume' attribute set to '+1dB' """ raw_text = "Today is a sunny day. But it might rain tomorrow." ssml_text = """<speak><prosody pitch='2.5'>Today is a sunny day</prosody>. <prosody rate='high' volume='+1dB'>But it might rain tomorrow.</prosody></speak>""" request["text"] = ssml_text response = riva_tts.synthesize(**request)
The
phonemetag allows us to control the pronunciation of the generated audio.Phoneme attribute - We can use the phoneme attribute to override the pronunciation of words from the predicted pronunciation. For a given word or sequence of words, use the
phattribute to provide an explicit pronunciation, and the alphabet attribute to provide the phone set. In Riva 2.4.0 (the version used in this lab), onlyx-arpabetis supported for pronunciation dictionaries based on CMUdict. IPA support is added from Riva 2.8.0.
Here’s an example of using the
phonemeSSML tags during a Riva TTS service call:""" Raw text is "You say tomato, I say tomato." We are updating this raw text with SSML: 1. Envelope raw text in '<speak>' tags as is required for SSML 2. For a substring in the raw text, add '<phoneme>' tags with 'alphabet' attribute set to 'x-arpabet' and 'ph' attribute set to a custom pronunciation based on CMUdict and ARPABET """ raw_text = "You say tomato, I say tomato." ssml_text = '<speak>You say <phoneme alphabet="x-arpabet" ph="{@T}{@AH0}{@M}{@EY1}{@T}{@OW2}">tomato</phoneme>, I say <phoneme alphabet="x-arpabet" ph="{@T}{@AH0}{@M}{@AA1}{@T}{@OW2}">tomato</phoneme>.</speak>' request["text"] = ssml_text response = riva_tts.synthesize(**request)
The
subtag allows us to replace the pronounciation of the specified word or phrase with a different word or phrase.Here’s an example of using the
subSSML tags during a Riva TTS service call:""" Raw text is "WWW is know as the web" We are updating this raw text with SSML: 1. Envelope raw text in '<speak>' tags as is required for SSML 2. Add '<sub>' tag with 'alias' attribute set to replace www with `World Wide Web` """ raw_text = "WWW is know as the web." ssml_text = '<speak><sub alias="World Wide Web">WWW</sub> is known as the web.</speak>' request["text"] = ssml_text response = riva_tts.synthesize(**request)
To learn about customizing synthesised voice using SSML, go to the Jupyter Notebook pane on the left-hand navigation pane, and go through the 2_customize-ssml.ipynb notebook.
End-to-end training of TTS models requires large datasets and heavy compute resources.
For this reason, we only recommend training models from scratch where tens or hundreds of hours of transcribed speech data is available and especially in cases when you’re building a TTS system for a different/new language.
While you collect the text dataset for TTS, you need to remember that TTS models learn to map n-grams to sounds. Thus, you should ensure that the text data isn’t archaic and it should have sufficient phoneme coverage.
Go through the notebooks 3_spectrogen-vocoder-tao-training.ipynb and 4_spectrogen-vocoder-tao-deployment.ipynb to learn how to train and deploy FastPitch and HiFiGAN models with Riva tools.
Fine-tuning TTS models is a recent advancement in the field of speech synthesis and is commonly used to adapt the pre-trained TTS models for a different accent or adding a new speaker’s voice.
NVIDIA offers pre-trained FastPitch and HiFiGAN models, trained on 25+ hours of LJSpeech dataset, which can be used for finetuning. The steps for adapting the pre-trained model for a new voice are mentioned in Riva’s Custom Voice documentation . Though finetuning is out of scope for this lab, we would be covering it in the next release. Stay tuned!
Riva offers a rich set of customization techniques that you can use to adapt the synthesized speech according to your needs and improve the quality of voice synthesized.