Multi-Token Prediction (MTP)#
Multi-Token Prediction (MTP) extends the prediction scope to several future tokens at each position. An MTP objective adds extra prediction targets, which can improve data efficiency. It may also encourage representations that anticipate later tokens. This implementation predicts additional tokens in sequence and preserves the causal dependency chain at each depth. The following figure illustrates MTP as used in DeepSeek-V3.
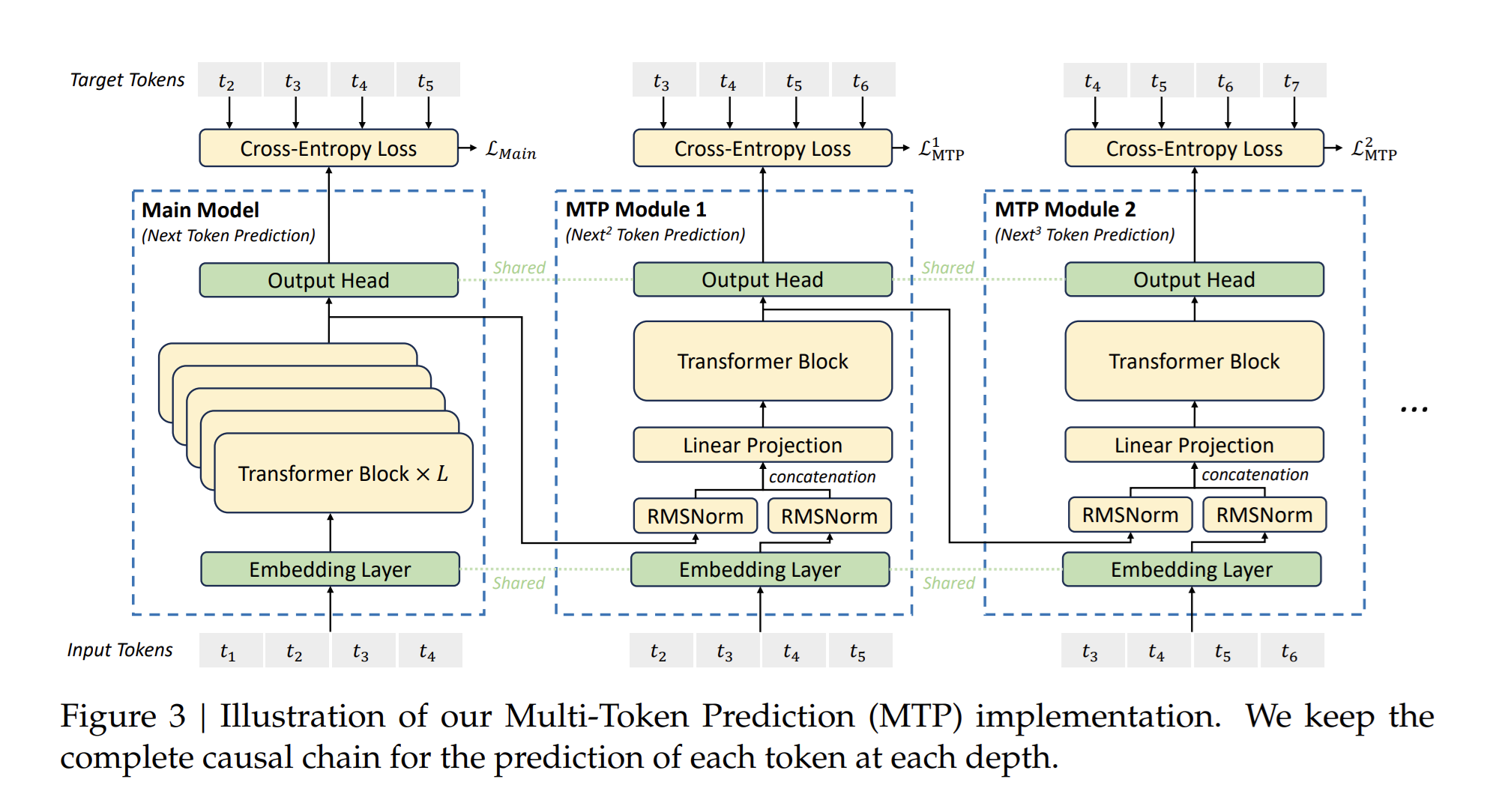
The k-th MTP module includes a shared embedding layer, a projection matrix, a Transformer block, and a shared output head. For the i-th input token at depth k - 1, the implementation combines the representation of the i-th token and the embedding of the (i + K)-th token with a linear projection. That combined representation is the input to the Transformer block at depth k, which produces the output representation.
For more detail, refer to the DeepSeek-V3 technical report.
Pipeline Parallel Layout for MTP#
MTP supports user-defined placement of MTP layers across pipeline stages through pipeline_model_parallel_layout. By default, all MTP layers sit on the last pipeline stage; you can override placement in the layout string.
MTP Standalone Mode#
When MTP layers are placed in a separate virtual pipeline (VPP) stage that is not on the last pipeline rank, the mtp_standalone flag is automatically set to True. MTP then runs in its own pipeline stage.
Layout Format#
Use m for MTP layers in the pipeline layout string. For example:
"E|t*3|(t|)*5mL"- MTP in the last stage"E|t*3|(t|)*4tm|L"- MTP in the second-to-last stage with a decoder layer"E|t*3|(t|)*3tt|m|L"- MTP in a standalone stage (second-to-last) with no other layers
Constraints#
Place all MTP layers in the same virtual pipeline stage.
Do not place MTP layers on the first pipeline rank.
Implementation Notes#
For models with MTP layers, the final LayerNorm sits in the stage that contains the last decoder layer, not in the post-process stage. That can change gradient norm reduction slightly in deterministic mode when LayerNorm would otherwise live in another stage. For bitwise alignment, disable gradient norm clipping.
MTP loss is computed in the post-processing stage.
Unsupported Combinations#
Context Parallel (CP), arbitrary AttnMaskType, and learned absolute position embeddings are not supported with MTP.