NVIDIA NeMo™ Framework is a development platform for building custom generative AI models. The framework supports custom models for language (LLMs), multimodal, computer vision (CV), automatic speech recognition (ASR), natural language processing (NLP), and text to speech (TTS).
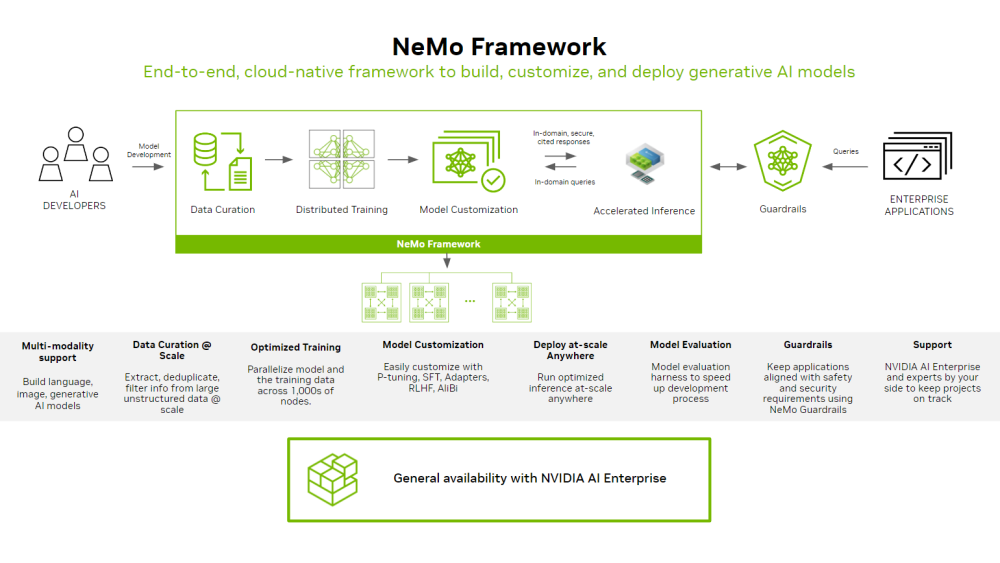
NVIDIA NeMo framework is a scalable and cloud-native generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (Automatic Speech Recognition and Text-to-Speech). It enables users to efficiently create, customize, and deploy new generative AI models by leveraging existing code and pretrained model checkpoints.
Documentation for using the current NVIDIA NeMo Framework release.
This guide is designed to help you understand some fundamental concepts related to the various components of the framework, and point you to some resources to kickstart your journey in using it to build generative AI applications.
A collection of tutorials for NeMo Framework.
Synthetic data generation (SDG) is a data augmentation technique necessary for increasing the robustness of models by supplying training data. With advancements in pre-trained Transformers, data scientists across all industries are learning to use them to generate synthetic training data for downstream predictive tasks. In this course, you’ll explore the use of Transformers for synthetic tabular data generation. We will use credit card transactions data and the Megatron framework for the course, but this technique is broadly applicable to tabular data in general.
Large Language Models (LLMs), or Transformers, have revolutionized the field of natural language processing (NLP). Driven by recent advancements, applications of NLP and generative AI have exploded in the past decade. With the proliferation of applications like chatbots and intelligent virtual assistants, organizations are infusing their businesses with more interactive human-machine experiences. Understanding how Transformer-based large language models (LLMs) can be used to manipulate, analyze, and generate text-based data is essential. Modern pre-trained LLMs can encapsulate the nuance, context, and sophistication of language, just as humans do. When fine-tuned and deployed correctly, developers can use these LLMs to build powerful NLP applications that provide natural and seamless human-computer interactions within chatbots, AI voice agents, and more. In this course, you’ll learn how Transformers are used as the building blocks of modern large language models (LLMs). You’ll then use these models for various NLP tasks, including text classification, named-entity recognition (NER), author attribution, and question answering.
Retrieval Augmented Generation (RAG) - Introduced by Facebook AI Research in 2020, is an architecture used to optimize the output of an LLM with dynamic, domain specific data without the need of retraining the model. RAG is an end-to-end architecture that combines an information retrieval component with a response generator. In this introduction we provide a starting point using components we at NVIDIA have used internally. This workflow will jumpstart you on your LLM and RAG journey.
Agents powered by large language models (LLMs) are quickly gaining popularity from both individuals and companies as people are finding new emerging capabilities and opportunities to greatly improve their productivity. An especially powerful recent development has been the popularization of retrieval-based LLM systems that can hold informed conversations by using tools, looking at documents, and planning their approaches. These systems are very fun to experiment with and offer unprecedented opportunities to make life easier, but also require many queries to large deep learning models and need to be implemented efficiently. This course will observe how you can deploy an agent system in practice and scale up your system to meet the demands of users and customers.