Advanced Features
RPC log history is a debug feature (enabled by default) which records all the RPC requests (from snap_rpc.py and spdk_rpc.py) sent to the SNAP application and the RPC response for each RPC requests in a dedicated log file, /var/log/snap-log/rpc-log. This file is visible outside the container (i.e., the log file's path on the DPU is /var/log/snap-log/rpc-log as well).
The SNAP_RPC_LOG_ENABLE env can be used to enable (1) or disable (0) this feature.
RPC log history is supported with SPDK version spdk23.01.2-12 and above.
When RPC log history is enabled, the SNAP application writes (in append mode) RPC request and response message to /var/log/snap-log/rpc-log constantly. Pay attention to the size of this file. If it gets too large, delete the file on the DPU before launching the SNAP pod.
SR-IOV configuration depends on the kernel version:
Optimal configuration may be achieved with a new kernel in which the sriov_drivers_autoprobe sysfs entry exists in /sys/bus/pci/devices/<BDF>/
Otherwise, the minimal requirement may be met if the sriov_totalvfs sysfs entry exists in /sys/bus/pci/devices/<BDF>/
After configuration is finished, no disk is expected to be exposed in the hypervisor. The disk only appears in the VM after the PCIe VF is assigned to it using the virtualization manager. If users want to use the device from the hypervisor, they must bind the PCIe VF manually.
Hot-plug PFs do not support SR-IOV.
It is recommended to add pci=assign-busses to the boot command line when creating more than 127 VFs.
Without this option, the following errors may appear from host and the virtio driver will not probe these devices.
pci 0000:84:00.0: [1af4:1041] type 7f class 0xffffff
pci 0000:84:00.0: unknown header type 7f, ignoring device
Zero-copy is supported on SPDK 21.07 and higher.
SNAP-direct allows SNAP applications to transfer data directly from the host memory to remote storage without using any staging buffer inside the DPU.
SNAP enables the feature according to the SPDK BDEV configuration only when working against an SPDK NVMe-oF RDMA block device.
To enable zero copy, set the environment variable (as it is enabled by default):
SNAP_RDMA_ZCOPY_ENABLE=1
For more info refer to the section SNAP Environment Variables.
NVMe/TCP Zero Copy is implemented as a custom NVDA_TCP transport in SPDK NVMe initiator and it is based on a new XLIO socket layer implementation.
The implementation is different for Tx and Rx:
The NVMe/TCP Tx Zero Copy is similar between RDMA and TCP in that the data is sent from the host memory directly to the wire without an intermediate copy to Arm memory
The NVMe/TCP Rx Zero Copy allows achieving partial zero copy on the Rx flow by eliminating copy from socket buffers (XLIO) to application buffers (SNAP). But data still must be DMA'ed from Arm to host memory.
To enable NVMe/TCP Zero Copy, use SPDK v22.05.nvda --with-xlio (v22.05.nvda or higher).
For more information about XLIO including limitations and bug fixes, refer to the NVIDIA Accelerated IO (XLIO) Documentation.
To enable the SNAP TCP XLIO Zero Copy, set the environment variables and resources in the YAML file:
resources:
requests:
memory: "4Gi"
cpu: "8"
limits:
hugepages-2Mi: "4Gi"
memory: "6Gi"
cpu: "16"
## Set according to the local setup
env:
- name: APP_ARGS
value: "--wait-for-rpc"
- name: SPDK_XLIO_PATH
value: "/usr/lib/libxlio.so"
NVMe/TCP XLIO requires DPU OS hugepage size of 4G (i.e., 2G more hugepages than non-XLIO). For information on configuring the hugepages, refer to sections "Step 1: Allocate Hugepages" and "Adjusting YAML Configuration".
At high scale, it is required to use the global variable XLIO_RX_BUFS=4096 even though it leads to high memory consumption. Using XLIO_RX_BUFS=1024 requires lower memory consumption but limits the ability to scale the workload.
For more info refer to the section "SNAP Environment Variables".
It is recommended to configure NVMe/TCP XLIO with the transport ack timeout option increased to 12.
[dpu] spdk_rpc.py bdev_nvme_set_options --transport-ack-timeout 12
Other bdev_nvme options may be adjusted according to requirements.
Expose an NVMe-oF subsystem with one namespace by using a TCP transport type on the remote SPDK target.
[dpu] spdk_rpc.py sock_set_default_impl -i xlio
[dpu] spdk_rpc.py framework_start_init
[dpu] spdk_rpc.py bdev_nvme_set_options --transport-ack-timeout 12
[dpu] spdk_rpc.py bdev_nvme_attach_controller -b nvme0 -t nvda_tcp -a 3.3.3.3 -f ipv4 -s 4420 -n nqn.2023-01.io.nvmet
[dpu] snap_rpc.py nvme_subsystem_create --nqn nqn.2023-01.com.nvda:nvme:0
[dpu] snap_rpc.py nvme_namespace_create -b nvme0n1 -n 1 --nqn nqn. 2023-01.com.nvda:nvme:0 --uuid 16dab065-ddc9-8a7a-108e-9a489254a839
[dpu] snap_rpc.py nvme_controller_create --nqn nqn.2023-01.com.nvda:nvme:0 --ctrl NVMeCtrl1 --pf_id 0 --suspended --num_queues 16
[dpu] snap_rpc.py nvme_controller_attach_ns -c NVMeCtrl1 -n 1
[dpu] snap_rpc.py nvme_controller_resume -c NVMeCtrl1 -n 1
[host] modprobe -v nvme
[host] fio --filename /dev/nvme0n1 --rw randrw --name=test-randrw --ioengine=libaio --iodepth=64 --bs=4k --direct=1 --numjobs=1 --runtime=63 --time_based --group_reporting --verify=md5
For more information on XLIO, please refer to XLIO documentation.
Live migration is a standard process supported by QEMU which allows system administrators to pass devices between virtual machines in a live running system. For more information, refer to QEMU VFIO Device Migration documentation.
Live migration is supported for SNAP virtio-blk devices. It can be activated using a driver with proper support (e.g., NVIDIA's proprietary vDPA-based Live Migration Solution).
snap_rpc.py virtio_blk_controller_create --dbg_admin_q …
Live upgrade allows upgrading the SNAP image a container is using without SNAP container downtime.
Live Upgrade Prerequisites
To enable live upgrade, perform the following modifications:
Allocate double hugepages for the destination and source containers.
Make sure the requested amount of CPU cores is available.
The default YAML configuration sets the container to request a CPU core range of 8-16. This means that the container is not deployed if there are fewer than 8 available cores, and if there are 16 free cores, the container utilizes all 16.
For instance, if a container is currently using all 16 cores and, during a live upgrade, an additional SNAP container is deployed. In this case, each container uses 8 cores during the upgrade process. Once the source container is terminated, the destination container starts utilizing all 16 cores.
WarningFor 8-core DPUs, the .yaml must be edited to the range of 4-8 CPU cores.
Change the name of the doca_snap.yaml file that describes the destination container (e.g., doca_snap_new.yaml ) so as to not overwrite the running container .yaml.
Change the name of the new .yaml pod in line 16 (e.g., snap-new).
Live Upgrade Flow
The way to live upgrade the SNAP image is to move the SNAP controllers and SPDK block devices between different containers while minimizing the duration of the host VMs impact.
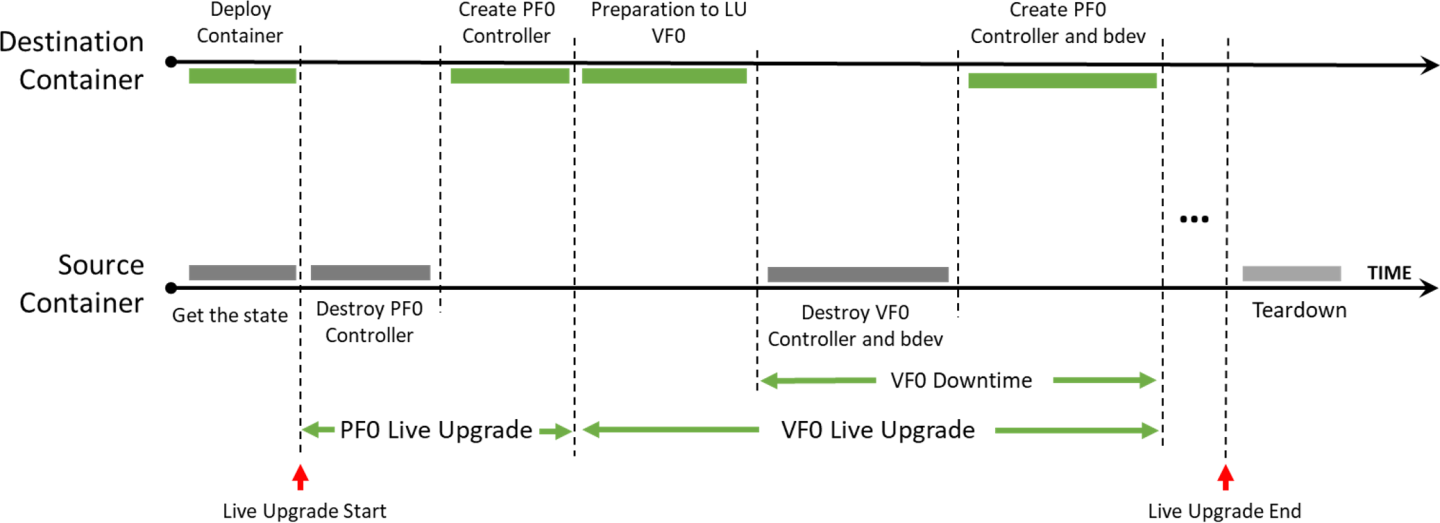
Source container – the running container before live upgrade
Destination container – the running container after live upgrade
SNAP Container Live Upgrade Procedure
Follow the steps in section "Live Upgrade Prerequisites" and deploy the destination SNAP container using the modified yaml file.
Query the source and destination containers:
crictl ps -r
Check for SNAP started successfully in the logs of the destination container, then copy the live update from the container to your environment.
[dpu] crictl logs -f <dest-container-id> [dpu] crictl exec <dest-container-id> cp /opt/nvidia/nvda_snap/bin/live_update.py /etc/nvda_snap/
Run the live_update.py script to move all active objects from the source container to the destination container:
[dpu] cd /etc/nvda_snap [dpu] ./live_update.py -s <source-container-id> -d <dest-container-id>
Delete the source container.
WarningTo post RPCs, use the crictl tool:
crictl exec -it <container-id X> snap_rpc.py <RPC-method> crictl exec -it <container-id Y> spdk_rpc.py <RPC-method>
WarningTo automate the SNAP configuration (e.g., following failure or reboot) as explained in section "Automate SNAP Configuration (Optional)", spdk_rpc_init.conf and snap_rpc_init.conf must not include any configs as part of the live upgrade. Then, once the transition to the new container is done, spdk_rpc_init.conf and snap_rpc_init.conf can be modified with the desired configuration.
Message Signaled Interrupts eXtended (MSIX) is an interrupt mechanism that allows devices to use multiple interrupt vectors, providing more efficient interrupt handling than traditional interrupt mechanisms such as shared interrupts. In Linux, MSIX is supported in the kernel and is commonly used for high-performance devices such as network adapters, storage controllers, and graphics cards. MSIX provides benefits such as reduced CPU utilization, improved device performance, and better scalability, making it a popular choice for modern hardware.
However, proper configuration and management of MSIX interrupts can be challenging and requires careful tuning to achieve optimal performance, especially in a multi-function environment as SR-IOV.
By default, BlueField distributes MSIX vectors evenly between all virtual PCIe functions (VFs). This approach is not optimal as users may choose to attach VFs to different VMs, each with a different number of resources. Dynamic MSIX management allows the user to manually control of the number of MSIX vectors provided per each VF independently.
Configuration and behavior are similar for all emulation types, and specifically NVMe and virtio-blk.
Dynamic MSIX management is built from several configuration steps:
PF controller must be opened with dynamic MSIX management enabled.
At this point, and in any other time in the future when no VF controllers are opened (sriov_numvfs=0), all PF-related MSIX vectors can be reclaimed from the VFs to the PF's free MSIX pool.
User must take some of the MSIX from the free pool and give them to a certain VF during VF controller creation.
When destroying a VF controller, the user may choose to release its MSIX back to the pool.
Once configured, the MSIX link to the VFs remains persistent and may change only in the following scenarios:
User explicitly requests to return VF MSIXs back to the pool during controller destruction.
PF explicitly reclaims all VF MSIXs back to the pool.
Arm reboot (FE reset/cold boot) has occurred.
To emphasize, the following scenarios do not change MSIX configuration:
Application restart/crash.
Closing and reopening PF/VFs without dynamic MSIX support.
The following is an NVMe example of dynamic MSIX configuration steps (similar configuration also applies for virtio-blk):
Open controller on PF with dynamic MSIX capability:
snap_rpc.py nvme_controller_create_ --dynamic_msix …
Reclaim all MSIX from VFs to PF's free MSIX pool:
snap_rpc.py nvme_controller_vfs_msix_reclaim <CtrlName>
Query controllers list to get information about how many MSIX are returned to the pool:
# snap_rpc.py nvme_controller_list -c <CtrlName> … 'num_free_msix': N, …
Distribute MSIX between VFs during their creation process:
snap_rpc.py nvme_controller_create_ --vf_num_msix <n> …
Upon VF teardown, release MSIX back to the free pool:
snap_rpc.py nvme_controller_destroy_ --release_msix …
Set SR-IOV on the host driver:
echo <N> > /sys/bus/pci/devices/<BDF>/sriov_numvfs
WarningIt is highly advised to open all VF controllers in SNAP in advance before binding VFs to the host/guest driver. That way, for example in case of a configuration mistake which does not leave enough MSIX for all VFs, the configuration remains reversible as MSIX is still modifiable. Otherwise, the driver may try to use the already-configured VFs before all VF configuration has finished but will not be able to use all of them (due to lack of MSIX). The latter scenario may result in host deadlock which, at worst, can be recovered only with cold boot.
WarningThere are several ways to configure dynamic MSIX safely (without VF binding):
Disable kernel driver automatic VF binding to kernel driver:
# echo 0 > /sys/bus/pci/devices/sriov_driver_autoprobe
After finishing MSIX configuration for all VFs, they can then be bound to VMs, or even back to the hypervisor:
echo "0000:01:00.0" > /sys/bus/pci/drivers/nvme/bind
Use VFIO driver (instead of kernel driver) for SR-IOV configuration.
For example:
# echo 0000:af:00.2 > /sys/bus/pci/drivers/vfio-pci/bind # Bind PF to VFIO driver # echo 1 > /sys/module/vfio_pci/parameters/enable_sriov # echo <N> > /sys/bus/pci/drivers/vfio-pci/0000:af:00.2/sriov_numvfs # Create VFs device for it
NVMe Recovery
NVMe recovery allows the NVMe controller to be recovered after a SNAP application is closed whether gracefully or after a crash (e.g., kill -9).
To use NVMe recovery, the controller must be re-created in a suspended state with the same configuration as before the crash (i.e., the same bdevs, num queues, and namespaces with the same uuid, etc).
The controller must be resumed only after all NSs are attached.
NVMe recovery uses files on the BlueField under /dev/shm to recover the internal state of the controller. Shared memory files are deleted when the BlueField is reset. For this reason, recovery is not supported after BF reset.
Virtio-blk Crash Recovery
The following options are available to enable virtio-blk crash recovery.
Virtio-blk Crash Recovery with --force_in_order
For virtio-blk crash recovery with --force_in_order, disable the VBLK_RECOVERY_SHM environment variable and create a controller with the --force_in_order argument.
In virtio-blk SNAP, the application is not guaranteed to recover correctly after a sudden crash (e.g., kill -9).
To enable the virtio-blk crash recovery, set the following:
snap_rpc.py virtio_blk_controller_create --force_in_order …
Setting force_in_order to 1 may impact virtio-blk performance as it will serve the command in-order.
If --force_in_order is not used, any failure or unexpected teardown in SNAP or the driver may result in anomalous behavior because of limited support in the Linux kernel virtio-blk driver.
Virtio-blk Crash Recovery without --force_in_order
For virtio-blk crash recovery without --force_in_order, enable the VBLK_RECOVERY_SHM environment variable and create a controller without the --force_in_order argument.
Virtio-blk recovery allows the virtio-blk controller to be recovered after a SNAP application is closed whether gracefully or after a crash (e.g., kill -9).
To use virtio-blk recovery without --force_in_order flag. VBLK_RECOVERY_SHM must be enabled, the controller must be recreated with the same configuration as before the crash (i.e., same bdevs, num queues, etc).
When VBLK_RECOVERY_SHM is enabled, virtio-blk recovery uses files on the BlueField under /dev/shm to recover the internal state of the controller. Shared memory files are deleted when the BlueField is reset. For this reason, recovery is not supported after BlueField reset.