Collective Operations¶
NVSHMEM4Py provides collective communication operations that allow for efficient data exchange patterns across all processing elements (PEs). These operations include broadcasts, reductions, and synchronization primitives.
Collective operations in NVSHMEM4Py follow the same semantics as their C/C++ counterparts but with a Pythonic interface. They operate on symmetric memory allocated through NVSHMEM.
Collective operations have to be called for each PE (which is associated with a specific CUDA device), using the same count and the same datatype, to form a complete collective operation. Failure to do so will result in undefined behavior, including hangs, crashes, or data corruption.
Supported Collective Operations¶
Reduce:¶
NVSHMEM’s reduce operation is similar to the AllReduce operation in other libraries. It performs a reduction operation (sum, min, or max) across all PEs and distributes the result to all PEs.
In a sum allreduce operation between k PEs, each PE will provide an array in of N values, and receive identical results in array out of N values, where out[i] = in0[i]+in1[i]+…+in(k-1)[i].
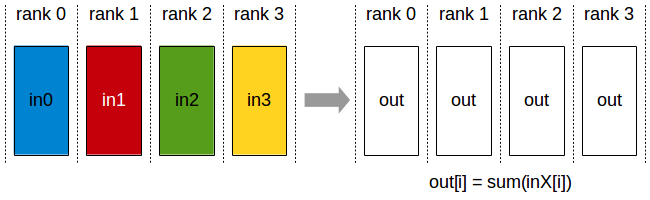
Reduce operation: each PE receives the reduction of input values across PEs.
Broadcast:¶
The Broadcast operation copies an N-element buffer from the root PE to all the PEs.
Important note: The root argument is one of the PEs, not a device number, and is therefore impacted by a different PE to device mapping.
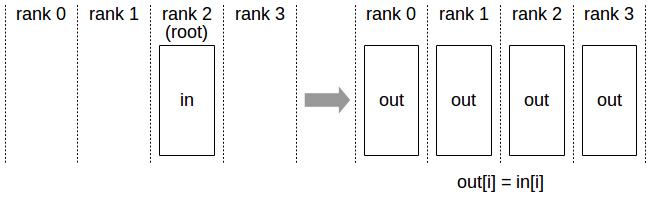
Broadcast operation: all PEs receive data from a “root” PE.
ReduceScatter:¶
The ReduceScatter operation performs the same operation as Reduce, except that the result is scattered in equal-sized blocks between PEs, each PE getting a chunk of data based on its PE index rather than the whole result.
The ReduceScatter operation is impacted by a different PE to device mapping since the PEs determine the data layout.
Note: Executing ReduceScatter, followed by Fcollect is equivalent to the Reduce operation.
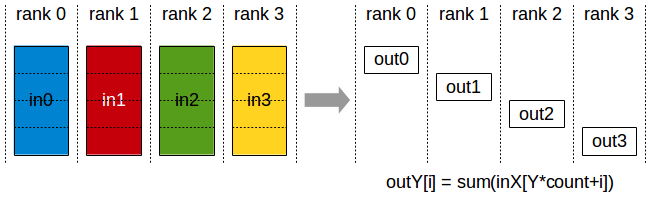
Reduce operation: each PE receives the reduction of input values across PEs.
FCollect:¶
The FCollect operation is similar to the AllGather operation in other libraries. It gathers data from all PEs to all PEs.
It gathers N values from k PEs into an output buffer of size k*N, and distributes that result to all PEs.
The output is ordered by the PE index. The AllGather operation is therefore impacted by a different PE to device mapping.
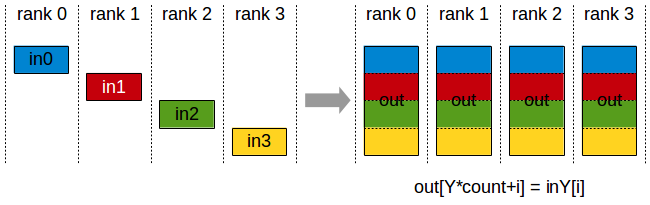
AllGather operation: each PE receives the aggregation of data from all PEs in the order of the PEs.
AlltoAll:¶
The AlltoAll operation is a collective communication operation where each PE sends distinct data to every other PE, and simultaneously receives distinct data from every other PE.
It takes an input buffer of size k*N on each of the k PEs, where each segment of N elements is intended for a specific PE. The operation redistributes these segments such that each PE ends up with one N-sized segment from every other PE, resulting in an output buffer also of size k*N.
The output is ordered by the source PE index. This means that for a given PE, the received data from PE i will be stored in the i-th segment of its output buffer.
This operation is sensitive to the PE-to-device mapping, as the communication pattern depends on every PE talking to every other PE.
For a more detailed explanation of the AlltoAll operation, see this page.
Stream Requirement for Collectives¶
All collective operations in NVSHMEM4Py require a CUDA stream to be provided. The stream can be created using the current CUDA device’s create_stream() method. This is necessary for proper synchronization of GPU operations.
More information on the CUDA-Python Stream interface is avialable in the CUDA.Core Stream docs.
Collective Examples¶
Broadcast Example:
import nvshmem.core as nvshmem
import cupy as cp
from cuda.core.experimental import Device
# Initialize NVSHMEM (initialization code not shown)
# Get current device and create a stream
device = Device()
stream = device.create_stream()
# Allocate symmetric memory using nvshmem.core.array
size = 10
src_array = nvshmem.array((size,), dtype=cp.float32)
# Set values on PE 0
my_pe = nvshmem.my_pe()
if my_pe == 0:
src_array[:] = cp.arange(size, dtype=cp.float32)
# Broadcast from PE 0 to all PEs
nvshmem.broadcast(src_array, src_array, size, 0, stream=stream)
# Now all PEs have the same data
# Clean up
nvshmem.free(src_array)
Reduce Example:
import nvshmem.core as nvshmem
import cupy as cp
from cuda.core.experimental import Device
# Initialize NVSHMEM (initialization code not shown)
# Get current device and create a stream
device = Device()
stream = device.create_stream()
# Allocate symmetric memory using nvshmem.core.array
size = 10
src_array = nvshmem.array((size,), dtype=cp.float32)
dest_array = nvshmem.array((size,), dtype=cp.float32)
# Set values on each PE
my_pe = nvshmem.my_pe()
n_pes = nvshmem.n_pes()
# Fill source array with PE ID
src_array[:] = cp.ones(size, dtype=cp.float32) * my_pe
# Perform sum reduce (distributes result to all PEs)
nvshmem.reduce(dest_array, src_array, size, 0, nvshmem.ReduceOp.SUM, stream=stream)
# All PEs now have the result in dest_array
# Each element should equal sum(range(n_pes))
expected_sum = (n_pes * (n_pes - 1)) / 2
print(f"PE {my_pe} - Sum result: {dest_array[0]}, Expected: {expected_sum}")
# Clean up
nvshmem.free(src_array)
nvshmem.free(dest_array)
Fcollect Example:
import nvshmem.core as nvshmem
import cupy as cp
from cuda.core.experimental import Device
# Initialize NVSHMEM (initialization code not shown)
# Get current device and create a stream
device = Device()
stream = device.create_stream()
# Allocate symmetric memory using nvshmem.core.array
my_pe = nvshmem.my_pe()
n_pes = nvshmem.n_pes()
# Each PE has one element
src_array = nvshmem.array((1,), dtype=cp.float32)
# Destination needs to hold data from all PEs
dest_array = nvshmem.array((n_pes,), dtype=cp.float32)
# Set my value to my PE number
src_array[0] = float(my_pe)
# Gather data from all PEs to all PEs
nvshmem.fcollect(dest_array, src_array, 1, stream=stream)
# Now all PEs have all values
print(f"PE {my_pe} received: {dest_array}") # Should show [0, 1, 2, ..., n_pes-1]
# Clean up
nvshmem.free(src_array)
nvshmem.free(dest_array)
Barrier Example:
import nvshmem.core as nvshmem
import time
from cuda.core.experimental import Device
# Initialize NVSHMEM (initialization code not shown)
# Get current device and create a stream
device = Device()
stream = device.create_stream()
my_pe = nvshmem.my_pe()
# Simulate work with different durations
time.sleep(0.1 * my_pe)
print(f"PE {my_pe} reached barrier")
# Wait for all PEs to reach this point
nvshmem.barrier(stream=stream)
print(f"PE {my_pe} passed barrier")
# All PEs continue execution after this point
API Reference¶
The following are NVSHMEM4Py APIs that expose host-initiated collective communication
-
nvshmem.core.collective.reduce(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, dst_array: object, src_array: object, op: str, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None)¶ Performs a reduction from src_array to dst_array on a CUDA stream.
- Args:
- src_array: Source array (Torch or CuPy).
- dst_array: Destination array.
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream to perform the operation on.
- op (str): Reduction operator (e.g., “sum”).
-
nvshmem.core.collective.reducescatter(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, dst_array: object, src_array: object, op: str, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None)¶ Performs a reduce-scatter operation on a CUDA stream.
- Args:
- src_array: Source array (Torch or CuPy).
- dst_array: Destination array.
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream to perform the operation on.
- op (str): Reduction operator (e.g., “sum”).
-
nvshmem.core.collective.alltoall(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, dst_array: object, src_array: object, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None)¶ Performs an all-to-all communication on a CUDA stream.
- Args:
- src_array: Source array (Torch or CuPy).
- dst_array: Destination array.
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream to perform the operation on.
-
nvshmem.core.collective.fcollect(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, dst_array: object, src_array: object, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None)¶ Performs a full-collective operation on a CUDA stream.
- Args:
- src_array: Source array (Torch or CuPy).
- dst_array: Destination array.
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream to perform the operation on.
-
nvshmem.core.collective.broadcast(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, dst_array: object, src_array: object, root: int = 0, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None)¶ Broadcasts data from src_array to dst_array across the team on a CUDA stream.
- Args:
- src_array: Source array (Torch or CuPy).
- dst_array: Destination array.
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream to perform the operation on.
- root: Root PE
-
nvshmem.core.collective.barrier(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None) → None¶ Executes a team-wide barrier on a specified CUDA stream.
Does not support MPG use cases
- Args:
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream for synchronization.
-
nvshmem.core.collective.sync(team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None) → None¶ Executes a team-wide sync on a specified CUDA stream.
Does not support MPG use cases
- Args:
- team: NVSHMEM team handle.
- stream (Stream): CUDA stream for synchronization.
-
nvshmem.core.collective.barrier_all(stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None) → None¶ Executes a runtime-wide barrier on a specified CUDA stream.
Supports MPG use cases
- Args:
- stream (Stream): CUDA stream for synchronization.
-
nvshmem.core.collective.sync_all(stream: Union[None, nvshmem.core.nvshmem_types.NvshmemStream, cuda.core._stream.Stream] = None) → None¶ Executes a runtime-wide sync on a specified CUDA stream.
Supports MPG use cases
- Args:
- stream (Stream): CUDA stream for synchronization.
-
nvshmem.core.collective.collective_on_buffer(coll: str, team: <MutableEnum TEAM_INVALID=-1, TEAM_WORLD=0, TEAM_SHARED=1, TEAM_NODE=2, TEAM_SAME_MYPE_NODE=3, TEAM_SAME_GPU=4, TEAM_GPU_LEADERS=5, TEAMS_MIN=6, TEAM_INDEX_MAX=32767>, dest: cuda.core._memory._buffer.Buffer, src: cuda.core._memory._buffer.Buffer, dtype: str = None, op: str = None, root: int = 0, stream: cuda.core._stream.Stream = None, enable_timing=False) → float¶ This function allows host-initiated collectives over raw memory buffers. It is used by higher-level wrappers or when working with DLPack-converted memory directly.
- Args:
- team: The NVSHMEM team handle.
- src (Buffer): Source buffer.
- dest (Buffer): Destination buffer.
- Source and dest buffers MUST be allocated by nvshmem4py
- coll (str): Collective type (e.g., “reduce”, “fcollect”).
- dtype (str, optional): NVSHMEM dtype string for function resolution.
- op (str, optional): Reduction operator if required.
- stream (Stream, optional): CUDA stream to execute on.
- root (int): Root PE for collective. Only used for Broadcast today.
- enable_timing: If True, return the time (in ms) it took the collective to execute
- Raises:
NvshmemInvalid: If the Buffer or collective type is invalid.- Returns:
- float: time in ms that the collective took to execute if enable_timing is set, else 0
- NOTE:
- This API is considered experimental and should be used only by expert users