Creating an Experiment Spec File
This chapter describes how to create a specification file for model training, inference and evaluation.
Here is an example of a specification file for model classification:
model_config {
# Model architecture can be chosen from:
# ['resnet', 'vgg', 'googlenet', 'alexnet', 'mobilenet_v1', 'mobilenet_v2', 'squeezenet', 'darknet', 'googlenet']
arch: "resnet"
# for resnet --> n_layers can be [10, 18, 34, 50, 101]
# for vgg --> n_layers can be [16, 19]
# for darknet --> n_layers can be [19, 53]
n_layers: 18
use_bias: True
use_batch_norm: True
all_projections: True
use_pooling: False
freeze_bn: False
freeze_blocks: 0
freeze_blocks: 1
# image size should be "3, X, Y", where X,Y >= 16
input_image_size: "3,224,224"
}
eval_config {
eval_dataset_path: "/path/to/your/eval/data"
model_path: "/path/to/your/model"
top_k: 3
batch_size: 256
n_workers: 8
}
train_config {
train_dataset_path: "/path/to/your/train/data"
val_dataset_path: "/path/to/your/val/data"
pretrained_model_path: "/path/to/your/pretrained/model"
# optimizer can be chosen from ['adam', 'sgd']
optimizer: "sgd"
batch_size_per_gpu: 256
n_epochs: 80
n_workers: 16
# regularizer
reg_config {
type: "L2"
scope: "Conv2D,Dense"
weight_decay: 0.00005
}
# learning_rate
lr_config {
# "step" and "soft_anneal" are supported.
scheduler: "soft_anneal"
# "soft_anneal" stands for soft annealing learning rate scheduler.
# the following 4 parameters should be specified if "soft_anneal" is used.
learning_rate: 0.005
soft_start: 0.056
annealing_points: "0.3, 0.6, 0.8"
annealing_divider: 10
# "step" stands for step learning rate scheduler.
# the following 3 parameters should be specified if "step" is used.
# learning_rate: 0.006
# step_size: 10
# gamma: 0.1
# "cosine" stands for soft start cosine learning rate scheduler.
# the following 2 parameters should be specified if "cosine" is used.
# learning_rate: 0.05
# soft_start: 0.01
}
}
The classification experiment specification can be used with the tlt-train and
tlt-evaluate commands. It consists of three main components:
model_configeval_configtrain_config
Model Config
The table below describes the configurable parameters in the model_config.
Parameter |
Datatype |
Default |
Description |
Supported Values |
all_projections |
bool |
False |
For templates with shortcut connections, this parameter defines whether or not all shortcuts should be instantiated with 1x1 projection layers irrespective of whether there is a change in stride across the input and output. |
True/False (only to be used in resnet templates) |
arch |
string |
resnet |
This defines the architecture of the back bone feature extractor to be used to train. |
|
num_layers |
int |
18 |
Depth of the feature extractor for scalable templates. |
|
use_pooling |
Boolean |
False |
Choose between using strided convolutions or MaxPooling while downsampling. When true, MaxPooling is used to down sample, however for the object detection network, NVIDIA recommends setting this to False and using strided convolutions. |
False/True |
use_batch_norm |
Boolean |
False |
Boolean variable to use batch normalization layers or not. |
True/False |
freeze_blocks |
float (repeated) |
This parameter defines which blocks may be frozen from the instantiated feature extractor template, and is different for different feature extractor templates. |
|
|
freeze_bn |
Boolean |
False |
You can choose to freeze the Batch Normalizationlayers in the model during training. |
True/False |
freeze_bn |
Boolean |
False |
You can choose to freeze the Batch Normalizationlayers in the model during training. |
True/False |
input_image_size |
String |
“3,224,224” |
The dimension of the input layer of the model. Images in the dataset will be resized to this shape by the dataloader, when fed to the model for training. |
“C,X,Y”, where C=1 or C=3 and X,Y >=16 and X,Y are integers. |
Eval Config
The table below defines the configurable parameters for evaluating a classification model.
Parameter |
Datatype |
Default |
Description |
Supported Values |
eval_dataset_path |
string |
UNIX format path to the root directory of the evaluation dataset. |
UNIX format path. |
|
model_path |
string |
UNIX format path to the root directory of the model file you would like to evaluate. |
UNIX format path. |
|
top_k |
int |
5 |
The number elements to look at when calculating the top-K classification categorical accuracy metric. |
1, 3, 5 |
conf_threshold |
float |
0.5 |
The confidence threshold of the argmax of the classifier output to be considered as a true positive. |
>0.0 |
batch_size |
int |
256 |
Number of images per batch when evaluating the model. |
>1 (bound by the number of images that can be fit in the GPU memory) |
n_workers |
int |
8 |
Number of workers fetching batches of images in the evaluation dataloader. |
>1 |
Training Config
This section defines the configurable parameters for the classification model trainer.
Parameter |
Datatype |
Default |
Description |
Supported Values |
val_dataset_path |
string |
UNIX format path to the root directory of the evaluation dataset. |
UNIX format path. |
|
train_dataset_path |
string |
UNIX format path to the root directory of the evaluation dataset. |
UNIX format path. |
|
pretrained_model_path |
string |
UNIX format path to the model file containing the pretrained weights to initialize the model from. |
UNIX format path. |
|
batch_size_per_gpu |
int |
32 |
This parameter defines the number of images per batch per gpu. |
>1 |
num_epochs |
int |
120 |
This parameter defines the total number of epochs to run the experiment. |
|
n_workers |
int |
False |
Number of workers fetching batches of images in the evaluation dataloader. |
>1 |
learning rate |
learning rate scheduler proto |
This nested protobuf txt parameter defines the learning rate schedule to be used with the trainer, when training a classification model. The following parameters are required to configure a valid learning rate scheduler.
|
0.0 - 1.0 > 1.0 0.0 - 1.0 0.0 - 1.0 |
|
regularizer |
regularizer proto config |
This parameter configures the type and the weight of the regularizer to be used during training. The three parameters include:
|
The supported values for type are:
|
|
optimizer |
string |
sgd |
This parameter defines which optimizer to use for training_config |
[adam, sgd] |
To do training, evaluation and inference for DetectNet_v2, several components need to be configured, each with their own parameters. The tlt-train and tlt-evaluate commands for a DetectNet_v2 experiment share the same configuration file. The tlt-infer command uses a separate configuration file.
The training and inference tools use a specification file for object detection. The specification file for detection training configures these components of the training pipe:
Model
BBox ground truth generation
Post processing module
Cost function configuration
Trainer
Augmentation model
Evaluator
Dataloader
Model Config
Core object detection can be configured using the model_config option in the spec file.
Here’s a sample model config to instantiate a resnet18 model with pretrained weights and freeze blocks 0 and 1, with all shortcuts being set to projection layers.
# Sample model config for to instantiate a resnet18 model with pretrained weights and freeze blocks 0, 1
# with all shortcuts having projection layers.
model_config {
arch: "resnet"
pretrained_model_file: <path_to_model_file>
freeze_blocks: 0
freeze_blocks: 1
all_projections: True
num_layers: 18
use_pooling: False
use_batch_norm: True
dropout_rate: 0.0
training_precision: {
backend_floatx: FLOAT32
}
objective_set: {
cov {}
bbox {
scale: 35.0
offset: 0.5
}
}
}
The following table describes the model_config parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
all_projections |
bool |
False |
For templates with shortcut connections, this parameter defines whether or not all shortcuts should be instantiated with 1x1 projection layers irrespective of whether there is a change in stride across the input and output. |
True/False (only to be used in resnet templates) |
arch |
string |
resnet |
This defines the architecture of the back bone feature extractor to be used to train. |
resnet vgg mobilenet _v1 mobilenet _v2 googlenet |
num_layers |
int |
18 |
Depth of the feature extractor for scalable templates. |
resnets: 10, 18, 34, 50, 101 vgg: 16, 19 |
pretrained model file |
string |
This parameter defines the path to a pretrained tlt model file. If the |
Unix path |
|
use_pooling |
Boolean |
False |
Choose between using strided convolutions or MaxPooling while downsampling. When true, MaxPooling is used to down sample, however for the object detection network, NVIDIA recommends setting this to False and using strided convolutions. |
False/True |
use_batch_norm |
Boolean |
False |
Boolean variable to use batch normalization layers or not. |
True/False |
objective_set |
Proto Dictionary |
This defines what objectives is this network being trained for. For object detection networks, set it to learn cov and bbox. These parameters should not be altered for the current training pipeline. |
cov {} bbox { scale: 35.0 offset: 0.5 } |
|
dropout_rate |
Float |
0.0 |
Probability for drop out |
0.0-0.1 |
training precision |
Proto Dictionary |
Contains a nested parameter that sets the precision of the back-end training framework. |
backend_floatx: FLOAT32 |
|
load_graph |
Boolean |
False |
Flag to define whether or not to load the graph from the pretrained model file, or just the weights. For a pruned, please remember to set this parameter as True. Pruning modifies the original graph, hence the pruned model graph and the weights need to be imported. |
True/False |
freeze_blocks |
float (repeated) |
This parameter defines which blocks may be frozen from the instantiated feature extractor template, and is different for different feature extractor templates. |
|
|
freeze_bn |
Boolean |
False |
You can choose to freeze the Batch Normalizationlayers in the model during training. |
True/False |
BBox Ground Truth Generator
DetectNet_v2 generates 2 tensors, cov and bbox. The image is divided into 16x16 grid cells. The cov tensor(short for coverage tensor) defines the number of gridcells that are covered by an object. The bbox tensor defines the normalized image coordinates of the object (x1, y1) top_left and (x2, y2) bottom right with respect to the grid cell. For best results, you can assume the coverage area to be an ellipse within the bbox label, with the maximum confidence being assigned to the cells in the center and reducing coverage outwards. Each class has its own coverage and bbox tensor, thus the shape of the tensors are:
cov: Batch_size, Num_classes, image_height/16, image_width/16
bbox: Batch_size, Num_classes * 4, image_height/16, image_width/16 (where 4 is the number of coordinates per cell)
Here is a sample rasterizer config for a 3 class detector:
# Sample rasterizer configs to instantiate a 3 class bbox rasterizer
bbox_rasterizer_config {
target_class_config {
key: "car"
value: {
cov_center_x: 0.5
cov_center_y: 0.5
cov_radius_x: 0.4
cov_radius_y: 0.4
bbox_min_radius: 1.0
}
}
target_class_config {
key: "cyclist"
value: {
cov_center_x: 0.5
cov_center_y: 0.5
cov_radius_x: 0.4
cov_radius_y: 0.4
bbox_min_radius: 1.0
}
}
target_class_config {
key: "pedestrian"
value: {
cov_center_x: 0.5
cov_center_y: 0.5
cov_radius_x: 0.4
cov_radius_y: 0.4
bbox_min_radius: 1.0
}
}
deadzone_radius: 0.67
}
The bbox_rasterizer has the following parameters that are configurable:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
deadzone radius |
float |
0.67 |
The area to be considered as dormant (or area of no bboxes) around the ellipse of an object. This is particularly useful in cases of overlapping objects, so that foreground objects and background objects are not confused. |
0-1.0 |
target_class_config |
proto dictionary |
This is a nested configuration field that defines the coverage region for an object of a given class. For each class, this field is repeated. The configurable parameters of the target_class_config include:
|
|
Post processor
The post processor module generates renderable bounding boxes from the raw detection output. The process includes:
Filtering out valid detections by thresholding objects using the confidence value in the coverage tensor
Clustering the raw filtered predictions using DBSCAN to produce the final rendered bounding boxes
Filtering out weaker clusters based on the final confidence threshold derived from the candidate boxes that get grouped into a cluster
Here is an example of the definition of the postprocessor for a 3 class network learning for car, cyclist, and pedestrian:
postprocessing_config {
target_class_config {
key: "car"
value: {
clustering_config {
coverage_threshold: 0.005
dbscan_eps: 0.15
dbscan_min_samples: 0.05
minimum_bounding_box_height: 20
}
}
}
target_class_config {
key: "cyclist"
value: {
clustering_config {
coverage_threshold: 0.005
dbscan_eps: 0.15
dbscan_min_samples: 0.05
minimum_bounding_box_height: 20
}
}
}
target_class_config {
key: "pedestrian"
value: {
clustering_config {
coverage_threshold: 0.005
dbscan_eps: 0.15
dbscan_min_samples: 0.05
minimum_bounding_box_height: 20
}
}
}
}
This section defines parameters that configure the post processor. For each class you can train
for, the postprocessing_config has a target_class_config element, which defines
the clustering parameters for this class. The parameters for each target class include:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
key |
string |
The names of the class for which the post processor module is being configured. |
The network object class name, which are mentioned in the cost_function_config. |
|
value |
clustering _config proto |
The nested clustering config proto parameter that configures the postprocessor module. The parameters for this module are defined in the next table. |
Encapsulated object with parameters defined below. |
The clustering_config element configures the clustering block for this class. Here are the
parameters for this element:
Parameter |
Datatype |
Default |
Description |
Supported Values |
coverate_threshold |
float |
The minimum threshold of the coverage tensor output to be considered as a valid candidate box for clustering. The 4 coordinates from the bbox tensor at the corresponding indices are passed for clustering. |
0.0 - 1.0 |
|
dbscan_eps |
float |
The maximum distance between two samples for one to be considered as in the neighborhood of the other. This is not a maximum bound on the distances of points within a cluster. The greater the eps, more boxes are grouped together. |
0.0 - 1.0 |
|
dbscan_min_samples |
float |
The total weight in a neighborhood for a point to be considered as a core point. This includes the point itself. |
0.0 - 1.0 |
|
minimum_bounding_box_height |
int |
Minimum height in pixels to consider as a valid detection post clustering. |
0 - input image height |
Cost Function
This section helps you configure the cost function to include the classes that you are training for. For each class you want to train, add a new entry of the target classes to the spec file. NVIDIA recommends not changing the parameters within the spec file for best performance with these classes. The other parameters remain unchanged here.
cost_function_config {
target_classes {
name: "car"
class_weight: 1.0
coverage_foreground_weight: 0.05
objectives {
name: "cov"
initial_weight: 1.0
weight_target: 1.0
}
objectives {
name: "bbox"
initial_weight: 10.0
weight_target: 10.0
}
}
target_classes {
name: "cyclist"
class_weight: 1.0
coverage_foreground_weight: 0.05
objectives {
name: "cov"
initial_weight: 1.0
weight_target: 1.0
}
objectives {
name: "bbox"
initial_weight: 10.0
weight_target: 1.0
}
}
target_classes {
name: "pedestrian"
class_weight: 1.0
coverage_foreground_weight: 0.05
objectives {
name: "cov"
initial_weight: 1.0
weight_target: 1.0
}
objectives {
name: "bbox"
initial_weight: 10.0
weight_target: 10.0
}
}
enable_autoweighting: True
max_objective_weight: 0.9999
min_objective_weight: 0.0001
}
Trainer
Here’s a sample training_config block to configure a detectnet_v2 trainer:
training_config {
batch_size_per_gpu: 16
num_epochs: 80
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 5e-6
max_learning_rate: 5e-4
soft_start: 0.1
annealing: 0.7
}
}
regularizer {
type: L1
weight: 3e-9
}
optimizer {
adam {
epsilon: 1e-08
beta1: 0.9
beta2: 0.999
}
}
cost_scaling {
enabled: False
initial_exponent: 20.0
increment: 0.005
decrement: 1.0
}
}
The following table describes the parameters used to configure the trainer:
Parameter |
Datatype |
Default |
Description |
Supported Values |
batch_size_per _gpu |
int |
32 |
This parameter defines the number of images per batch per gpu. |
>1 |
num_epochs |
int |
120 |
This parameter defines the total number of epochs to run the experiment. |
|
enable_qat |
bool |
False |
This parameter enables training a model using Quantization Aware Training (QAT). For more information about QAT see Quantization Aware Training. |
True, False |
learning rate |
learning rate scheduler proto |
soft_start _annealing _schedule |
This parameter configures the learning rate schedule for the trainer. Currently detectnet_v2 only supports softstart annealing learning rate schedule, and maybe configured using the following parameters:
|
annealing: 0.0-1.0 and greater than soft_start Soft_start: 0.0 - 1.0 A sample lr plot for a soft start of 0.3 and annealing of 0.1 is shown in the figure below. |
regularizer |
regularizer proto config |
This parameter configures the type and the weight of the regularizer to be used during training. The two parameters include:
|
The supported values for type are:
|
|
optimizer |
optimizer proto config |
This parameter defines which optimizer to use for training, and the parameters to configure it, namely:
|
||
cost_scaling |
costscaling _config |
This parameter enables cost scaling during training. Please leave this parameter untouched currently for the detectnet_v2 training pipe. |
cost_scaling { enabled: False initial_exponent: 20.0 increment: 0.005 decrement: 1.0 } |
|
checkpoint interval |
float |
0/10 |
The interval (in epochs) at which tlt-train saves intermediate models. |
0 to num_epochs |
Detectnet_v2 currently supports the soft-start annealing learning rate schedule. The learning rate when plotted as a function of the training progress (0.0, 1.0) results in the following curve.
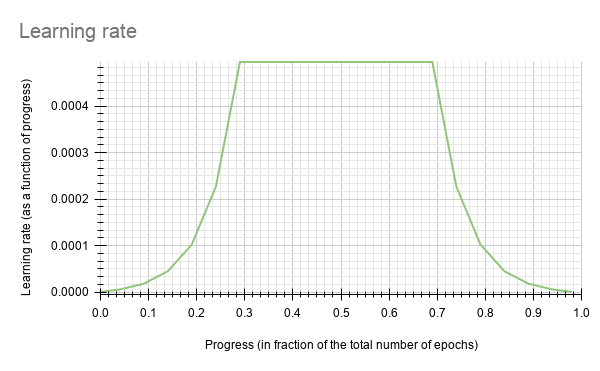
In this experiment, the soft start was set as 0.3 and annealing as 0.7, with minimum learning rate as 5e-6 and a maximum learning rate or base_lr as 5e-4.
NVIDIA suggests using L1 regularizer when training a network before pruning as L1
regularization helps making the network weights more easily pruned. After pruning,
when retraining the networks, NVIDIA recommends turning regularization off by setting
the regularization type to NO_REG.
Augmentation Module
The augmentation module provides some basic pre-processing and augmentation when training. Here
is a sample augmentation_config element:
# Sample augementation config for
augmentation_config {
preprocessing {
output_image_width: 960
output_image_height: 544
output_image_channel: 3
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 1.0
zoom_max: 1.0
translate_max_x: 8.0
translate_max_y: 8.0
}
color_augmentation {
color_shift_stddev: 0.0
hue_rotation_max: 25.0
saturation_shift_max: 0.2
contrast_scale_max: 0.1
contrast_center: 0.5
}
}
If the output image height and the output image width of the preprocessing block doesn’t match with the dimensions of the input image, the dataloader either pads with zeros, or crops to fit to the output resolution. It does not resize the input images and labels to fit.
The augmentation_config contains three elements:
preprocessing: This nested field configures the input image and ground truth label
pre-processing module. It sets the shape of the input tensor to the network. The ground truth
labels are pre-processed to meet the dimensions of the input image tensors.
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
output _image _width |
int |
– |
The width of the augmentation output. This is the same as the width of the network input and must be a multiple of 16. |
>480 |
output _image _height |
int |
– |
The height of the augmentation output. This is the same as the height of the network input and must be a multiple of 16. |
>272 |
output _image _channel |
int |
1, 3 |
The channel depth of the augmentation output. This is the same as the channel depth of the network input. Currently 1-channel input is not recommended for datasets with jpg images. For png images, both 3 channel RGB and 1 channel monochrome images are supported. |
1,3 |
Min_bbox _height |
float |
The minimum height of the object labels to be considered for training. |
0 - output_image_height |
|
Min_bbox _width |
float |
The minimum width of the object labels to be considered for training. |
0 - output_image_width |
|
crop_right |
int |
The right boundary of the crop to be extracted from the original image. |
0 - input image width |
|
crop_left |
int |
The left boundary of the crop to be extracted from the original image. |
0 - input image width |
|
crop_top |
int |
The top boundary of the crop to be extracted from the original image. |
0 - input image height |
|
crop_bottom |
int |
The bottom boundary of the crop to be extracted from the original image. |
0 - input image height |
|
scale_height |
float |
The floating point factor to scale the height of the cropped images. |
> 0.0 |
|
scale_width |
float |
The floating point factor to scale the width of the cropped images. |
> 0.0 |
spatial_augmentation: This module supports basic spatial augmentation such as flip, zoom
and translate which may be configured.
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
hflip_probability |
float |
0.5 |
The probability to flip an input image horizontally. |
0.0-1.0 |
vflip_probability |
float |
0.0 |
The probability to flip an input image vertically. |
0.0-1.0 |
zoom_min |
float |
1.0 |
The minimum zoom scale of the input image. |
> 0.0 |
zoom_max |
float |
1.0 |
The maximum zoom scale of the input image. |
> 0.0 |
translate_max_x |
int |
8.0 |
The maximum translation to be added across the x axis. |
0.0 - output_image_width |
translate_max_y |
int |
8.0 |
The maximum translation to be added across the y axis |
0.0 - output_image_height |
rotate_rad_max |
float |
0.69 |
The angle of rotation to be applied to the images and the training labels. The range is defined between [-rotate_rad_max, rotate_rad_max] |
> 0.0 (modulo 2*pi |
color_augmentation: This module configures the color space transformations, such as color
shift, hue_rotation, saturation shift, and contrast adjustment.
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
color_shift_stddev |
float |
0.0 |
The standard devidation value for the color shift. |
0.0-1.0 |
hue_rotation_max |
float |
25.0 |
The maximum rotation angle for the hue rotation matrix. |
0.0-360.0 |
saturation_shift_max |
float |
0.2 |
The maximum shift that changes the saturation. A value of 1.0 means no change in saturation shift. |
0.0 - 1.0 |
contrast_scale_max |
float |
0.1 |
The slope of the contrast as rotated around the provided center. A value of 0.0 leaves the contrast unchanged. |
0.0 - 1.0 |
contrast_center |
float |
0.5 |
The center around which the contrast is rotated. Ideally this is set to half of the maximum pixel value. (Since our input images are scaled between 0 and 1.0, you can set this value to 0.5). |
0.5 |
The dataloader online augmentation pipeline applies spatial and color-space augmentation transformations in the following order:
The dataloader first performs the pre-processing operations on the input data (image and labels) read from the tfrecords files. Here the images and labels cropped and scaled based on the parameters mentioned in the
preprocessingconfig. The boundaries of generating the cropped image and labels from the original image is defined by thecrop_left,crop_right,crop_topandcrop_bottomparameters. This cropped data is then scaled by the scale factors defined byscale_heightandscale_width. These transformation matrices for these operations are computed globally and do not change per image.The net tensors generated from the pre-processing blocks are then passed through a pipeline of random augmentations in spatial and color domain. The spatial augmentations are applied to both images and the label coordinates, while the color augmentations are applied only to the images. In order to apply color augmentations, the
output_image_channelparameter must be set to 3. For monochrome tensors color augmentations are not applied. The spatial and color transformation matrices are computed per image based on a uniform distribution along the max and min ranges defined by thespatial_augmentationandcolor_augmentationconfig parameters.Once the spatial and color augmented net input tensors are generated, the output is then padded with zeros or clipped along the right and bottom edge of the image to fit the output dimensions defined in the
preprocessingconfig.
Configuring the Evaluator
The evaluator in the detection training pipeline can be configured using the
evaluation_config parameters. The following is an example evaluation_config element:
# Sample evaluation config to run evaluation in integrate mode for the given 3 class model,
# at every 10th epoch starting from the epoch 1.
evaluation_config {
average_precision_mode: INTEGRATE
validation_period_during_training: 10
first_validation_epoch: 1
minimum_detection_ground_truth_overlap {
key: "car"
value: 0.7
}
minimum_detection_ground_truth_overlap {
key: "person"
value: 0.5
}
minimum_detection_ground_truth_overlap {
key: "bicycle"
value: 0.5
}
evaluation_box_config {
key: "car"
value {
minimum_height: 4
maximum_height: 9999
minimum_width: 4
maximum_width: 9999
}
}
evaluation_box_config {
key: "person"
value {
minimum_height: 4
maximum_height: 9999
minimum_width: 4
maximum_width: 9999
}
}
evaluation_box_config {
key: "bicycle"
value {
minimum_height: 4
maximum_height: 9999
minimum_width: 4
maximum_width: 9999
}
}
}
The following tables describe the parameters used to configure evaluation:
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
average_precision _mode |
Sample |
The mode in which the average precision for each class is calculated. |
|
|
validation_period _during_training |
int |
10 |
The interval at which evaluation is run during training. The evaluation is run at this interval starting from the value of the first validation epoch parameter as specified below. |
1 - total number of epochs |
first_validation _epoch |
int |
30 |
The first epoch to start running validation. Ideally it is preferred to wait for atleast 20-30% of the total number of epochs before starting evaluation, since the predictions in the initial epochs would be fairly inaccurate. Too many candidate boxes may be sent to clustering and this can cause the evaluation to slow down. |
1 - total number of epochs |
minimum_detection _ground_truth_overlap |
proto dictionary |
Minimum IOU between ground truth and predicted box after clustering to call a valid detection. This parameter is a repeatable dictionary, and a separate one must be defined for every class. The members include:
|
||
evaluation_box_config |
proto dictionary |
This nested configuration field configures the min and max box dimensions to be considered as a valid ground truth and prediction for AP calculation. |
The evaluation_box_config field has these configurable inputs.
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
minimum_height |
float |
10 |
Minimum height in pixels for a valid ground truth and prediction bbox. |
|
minimum_width |
float |
10 |
Minimum width in pixels for a valid ground truth and prediction bbox. |
|
maximum_height |
float |
9999 |
Maximum height in pixels for a valid ground truth and prediction bbox. |
minimum_height - model image height |
maximum_width |
float |
9999 |
Maximum width in pixels for a valid ground truth and prediction bbox. |
minimum _width - model image width |
Dataloader
The dataloader defines the path to the data you want to train on and the class mapping for classes in the dataset that the network is to be trained for.
The following is an example dataset_config element:
dataset_config {
data_sources: {
tfrecords_path: "<path to the training tfrecords root/tfrecords train pattern>"
image_directory_path: "<path to the training data source>"
}
image_extension: "jpg"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "automobile"
value: "car"
}
target_class_mapping {
key: "heavy_truck"
value: "car"
}
target_class_mapping {
key: "person"
value: "pedestrian"
}
target_class_mapping {
key: "rider"
value: "cyclist"
}
validation_fold: 0
}
In this example the tfrecords is assumed to be multi-fold, and the fold number to validate on is
defined. However, evaluation doesn’t necessarily have to be run on a split of the training set.
Many ML engineers choose to evaluate the model on a well chosen evaluation dataset that is
exclusive of the training dataset. If you prefer to run evaluation on a different validation
dataset as opposed to a split from the training dataset, then please convert this dataset into
tfrecords as well using the tlt-dataset-convert tool as mentioned here, and use the
validation_data_source field in the dataset_config to define this. In this case,
please do not forget to remove the validation_fold field from the spec. When generating
the TFRecords for evaluation by using the validation_data_source field, please review the
notes here.
validation_data_source: {
tfrecords_path: " <path to tfrecords to validate on>/tfrecords validation pattern>"
image_directory_path: " <path to validation data source>"
}
The parameters in dataset_config are defined as follows:
data_sources: Captures the path to TFrecords to train on. This field contains 2 parameters:tfrecords_path: Path to the individual TFrecords files. This path follows the UNIX style pathname pattern extension, so a common pathname pattern that captures all the tfrecords files in that directory can be used.image_directory_path: Path to the training data root from which the tfrecords was generated.
image_extension: Extension of the images to be used.target_class_mapping: This parameter maps the class names in the tfrecords to the target class to be trained in the network. An element is defined for every source class to target class mapping. This field was included with the intention of grouping similar class objects under one umbrella. For eg: car, van, heavy_truck etc may be grouped under automobile. The “key” field is the value of the class name in the tfrecords file, and “value” field corresponds to the value that the network is expected to learn.validation_fold: In case of an n fold tfrecords, you define the index of the fold to use for validation. For sequencewise validation please choose the validation fold in the range [0, N-1]. For random split partitioning, please force the validation fold index to 0 as the tfrecord is just 2-fold.
The class names key in the target_class_mapping must be identical to the one shown in the dataset converter log, so that the correct classes are picked up for training.
Specification File for Inference
This spec file configures the tlt-infer tool of detectnet to generate valid bbox predictions. The inference tool consists of 2 blocks, namely the inferencer and the bbox handler. The inferencer instantiates the model object and preprocessing pipe, which the bbox handler handles the post processing, rendering of bounding boxes and the serialization to KITTI format output labels.
Inferencer
The inferencer instantiates a model object that generates the raw predictions from the trained model. The model may be defined to run inference in the TLT backend or the TensorRT backend.
A sample inferencer_config element for the inferencer spec is defined here:
inferencer_config{
# defining target class names for the experiment.
# Note: This must be mentioned in order of the networks classes.
target_classes: "car"
target_classes: "cyclist"
target_classes: "pedestrian"
# Inference dimensions.
image_width: 1248
image_height: 384
# Must match what the model was trained for.
image_channels: 3
batch_size: 16
gpu_index: 0
# model handler config
tensorrt_config{
parser: ETLT
etlt_model: "/path/to/model.etlt"
backend_data_type: INT8
save_engine: true
trt_engine: "/path/to/trt/engine/file"
calibrator_config{
calibration_cache: "/path/to/calibration/cache"
n_batches: 10
batch_size: 16
}
}
}
The inferencer_config parameters are explained in the table below.
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
target_classes |
String (repeated) |
None |
The names of the target classes the model should output. For a multi-class model this parameter is repeated N times. The number of classes must be equal to the number of classes and the order must be the same as the classes in costfunction_config of the training config file. |
For example, for the 3 class kitti model it will be:
|
batch_size |
int |
1 |
The number of images per batch of inference |
Max number of images that can be fit in 1 GPU |
image_height |
int |
384 |
The height of the image in pixels at which the model will be inferred. |
>16 |
image_width |
int |
1248 |
The width of the image in pixels at which the model will be inferred. |
>16 |
image_channels |
int |
3 |
The number of channels per image. |
1,3 |
gpu_index |
int |
0 |
The index of the GPU to run inference on. This is useful only in TLT inference. For tensorRT inference, by default, the GPU of choice in ‘0’. |
|
tensorrt_config |
TensorRTConfig |
None |
Proto config to instantiate a TensorRT object |
|
tlt_config |
TLTConfig |
None |
Proto config to instantiate a TLT model object. |
As mentioned earlier, the tlt-infer tool is capable of running inference using the native TLT backend and the TensorRT backend. They can be configured by using the tensorrt_config proto element, or the tlt_config proto element respectively. You may use only one of the two in a single spec file. The definitions of the two model objects are:
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
parser |
enum |
ETLT |
The tensorrt parser to be invoked. Only ETLT parser is supported. |
ETLT |
etlt_model |
string |
None |
Path to the exported etlt model file. |
Any existing etlt file path. |
backend_data _type |
enum |
FP32 |
The data type of the backend TensorRT inference engine. For int8 mode, please be sure to mention the calibration_cache. |
FP32 FP16 INT8 |
save_engine |
bool |
False |
Flag to save a TensorRT engine from the input etlt file. This will save initialization time if inference needs to be run on the same etlt file and there are no changes needed to be made to the inferencer object. |
True, False |
trt_engine |
string |
None |
Path to the TensorRT engine file. This acts an I/O parameter. If the path defined here is not an engine file, then the tlt-infer tool creates a new TensorRT engine from the etlt file. If there exists an engine already, the tool, re-instantiates the inferencer from the engine defined here. |
UNIX path string |
calibration _config |
CalibratorConfig Proto |
None |
This is a required parameter when running in the int8 inference mode. This proto object contains parameters used to define a calibrator object. Namely: calibration_cache: path to the calibration cache file generated using tlt-export |
TLT_Config
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
model |
string |
None |
The path to the .tlt model file. |
Since detectnet is a full convolutional neural net, the model can be inferred at a different inference resolution than the resolution at which it was trained. The input dims of the network will be overridden to run inference at this resolution, if they are different from the training resolution. There may be some regression in accuracy when running inference at a different resolution since the convolutional kernels don’t see the object features at this shape.
Bbox Handler
The bbox handler takes care of the post processing the raw outputs from the inferencer. It performs the following steps:
Thresholding the raw outputs to defines grid-cells where the detections may be present per class.
Reconstructing the image space coordinates from the raw coordinates of the inferencer.
Clustering the raw thresholded predictions.
Filtering the clustered predictions per class.
Rendering the final bounding boxes on the image in its input dimensions and serializing them to KITTI format metadata.
A sample bbox_handler_config element is defined below.
bbox_handler_config{
kitti_dump: true
disable_overlay: false
overlay_linewidth: 2
classwise_bbox_handler_config{
key:"car"
value: {
confidence_model: "aggregate_cov"
output_map: "car"
confidence_threshold: 0.9
bbox_color{
R: 0
G: 255
B: 0
}
clustering_config{
coverage_threshold: 0.00
dbscan_eps: 0.3
dbscan_min_samples: 0.05
minimum_bounding_box_height: 4
}
}
}
classwise_bbox_handler_config{
key:"default"
value: {
confidence_model: "aggregate_cov"
confidence_threshold: 0.9
bbox_color{
R: 255
G: 0
B: 0
}
clustering_config{
coverage_threshold: 0.00
dbscan_eps: 0.3
dbscan_min_samples: 0.05
minimum_bounding_box_height: 4
}
}
}
}
The parameters to configure the bbox handler are defined below.
Parameter |
Datatype |
Default/Suggested value |
Description |
Supported Values |
kitti_dump |
bool |
false |
Flag to enable saving the final output predictions per image in KITTI format. |
true, false |
disable_overlay |
bool |
true |
Flag to disable bbox rendering per image. |
true, false |
overlay _linewidth |
int |
1 |
Thickness in pixels of the bbox boundaries. |
>1 |
classwise_bbox _handler_config |
ClasswiseCluster Config (repeated) |
None |
This is a repeated class-wise dictionary of post-processing parameters. DetectNet_v2 uses dbscan clustering to group raw bboxes to final predictions. For models with several output classes, it may be cumbersome to define a separate dictionary for each class. In such a situation, a default class may be used for all classes in the network. |
The classwise_bbox_handler_config is a Proto object containing several parameters to
configure the clustering algorithm as well as the bbox renderer.
Parameter |
Datatype |
Default / Suggested value |
Description |
Supported Values |
confidence _model |
string |
aggregate_cov |
Algorithm to compute the final confidence of the clustered bboxes. In the aggregate_cov mode, the final confidence of a detection is the sum of the confidences of all the candidate bboxes in a cluster. In mean_cov mode, the final confidence is the mean confidence of all the bboxes in the cluster. |
aggregate_cov, mean_cov |
confidence _threshold |
float |
0.9 in aggregate_cov mode 0.1 in mean_cov_mode |
The threshold applied to the final aggregate confidence values to render the bboxes. |
In aggregate_cov: Maybe tuned to any float value > 0.0 In mean_cov: 0.0 - 1.0 |
bbox_color |
BBoxColor Proto Object |
None |
RGB channel wise color intensity per box. |
R: 0 - 255 G: 0 - 255 B: 0 - 255 |
clustering_config |
ClusteringConfig |
None |
Proto object to configure the DBSCAN clustering algorithm. Contains the following sub parameters. coverage_threshold: The threshold applied to the raw network confidence predictions as a first stage filtering technique. dbscan_eps: (float) The search distance to group together boxes into a single cluster. The lesser the number, the more boxes are detected. Eps of 1.0 groups all boxes into a single cluster. dbscan_min_samples: (float) The weight of the boxes in a cluster. min_bbox_height: (int) The minimum height of the bbox to be clustered. |
coverage _threshold: 0.005 dbscan_eps: 0.3 dbscan_min _samples: 0.05 minimum_bounding _box_height: 4 |
Below is a sample of the FasterRCNN spec file. It has two major components: network_config
and training_config, explained below in detail. The format of the spec file is a protobuf
text(prototxt) message and each of its fields can be either a basic data type or a nested message.
The top level structure of the spec file is summarized in the table below.
Here’s a sample of the FasterRCNN spec file:
random_seed: 42
enc_key: 'tlt'
verbose: True
network_config {
input_image_config {
image_type: RGB
image_channel_order: 'bgr'
size_height_width {
height: 384
width: 1248
}
image_channel_mean {
key: 'b'
value: 103.939
}
image_channel_mean {
key: 'g'
value: 116.779
}
image_channel_mean {
key: 'r'
value: 123.68
}
image_scaling_factor: 1.0
max_objects_num_per_image: 100
}
feature_extractor: "resnet:18"
anchor_box_config {
scale: 64.0
scale: 128.0
scale: 256.0
ratio: 1.0
ratio: 0.5
ratio: 2.0
}
freeze_bn: True
freeze_blocks: 0
freeze_blocks: 1
roi_mini_batch: 256
rpn_stride: 16
conv_bn_share_bias: False
roi_pooling_config {
pool_size: 7
pool_size_2x: False
}
all_projections: True
use_pooling:False
}
training_config {
kitti_data_config {
data_sources: {
tfrecords_path: "/workspace/tlt-experiments/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tlt-experiments/data/training"
}
image_extension: 'png'
target_class_mapping {
key: 'car'
value: 'car'
}
target_class_mapping {
key: 'van'
value: 'car'
}
target_class_mapping {
key: 'pedestrian'
value: 'person'
}
target_class_mapping {
key: 'person_sitting'
value: 'person'
}
target_class_mapping {
key: 'cyclist'
value: 'cyclist'
}
validation_fold: 0
}
data_augmentation {
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 1.0
zoom_max: 1.0
translate_max_x: 0
translate_max_y: 0
}
color_augmentation {
hue_rotation_max: 0.0
saturation_shift_max: 0.0
contrast_scale_max: 0.0
contrast_center: 0.5
}
}
enable_augmentation: True
batch_size_per_gpu: 16
num_epochs: 12
pretrained_weights: "/workspace/tlt-experiments/data/faster_rcnn/resnet18.h5"
#resume_from_model: "/workspace/tlt-experiments/data/faster_rcnn/resnet18.epoch2.tlt"
#retrain_pruned_model: "/workspace/tlt-experiments/data/faster_rcnn/model_1_pruned.tlt"
output_model: "/workspace/tlt-experiments/data/faster_rcnn/frcnn_kitti_resnet18.tlt"
rpn_min_overlap: 0.3
rpn_max_overlap: 0.7
classifier_min_overlap: 0.0
classifier_max_overlap: 0.5
gt_as_roi: False
std_scaling: 1.0
classifier_regr_std {
key: 'x'
value: 10.0
}
classifier_regr_std {
key: 'y'
value: 10.0
}
classifier_regr_std {
key: 'w'
value: 5.0
}
classifier_regr_std {
key: 'h'
value: 5.0
}
rpn_mini_batch: 256
rpn_pre_nms_top_N: 12000
rpn_nms_max_boxes: 2000
rpn_nms_overlap_threshold: 0.7
reg_config {
reg_type: 'L2'
weight_decay: 1e-4
}
optimizer {
adam {
lr: 0.00001
beta_1: 0.9
beta_2: 0.999
decay: 0.0
}
}
lr_scheduler {
step {
base_lr: 0.00016
gamma: 1.0
step_size: 30
}
}
lambda_rpn_regr: 1.0
lambda_rpn_class: 1.0
lambda_cls_regr: 1.0
lambda_cls_class: 1.0
inference_config {
images_dir: '/workspace/tlt-experiments/data/testing/image_2'
model: '/workspace/tlt-experiments/data/faster_rcnn/frcnn_kitti_resnet18.epoch12.tlt'
detection_image_output_dir: '/workspace/tlt-experiments/data/faster_rcnn/inference_results_imgs'
labels_dump_dir: '/workspace/tlt-experiments/data/faster_rcnn/inference_dump_labels'
rpn_pre_nms_top_N: 6000
rpn_nms_max_boxes: 300
rpn_nms_overlap_threshold: 0.7
bbox_visualize_threshold: 0.6
classifier_nms_max_boxes: 300
classifier_nms_overlap_threshold: 0.3
}
evaluation_config {
model: '/workspace/tlt-experiments/data/faster_rcnn/frcnn_kitti_resnet18.epoch12.tlt'
labels_dump_dir: '/workspace/tlt-experiments/data/faster_rcnn/test_dump_labels'
rpn_pre_nms_top_N: 6000
rpn_nms_max_boxes: 300
rpn_nms_overlap_threshold: 0.7
classifier_nms_max_boxes: 300
classifier_nms_overlap_threshold: 0.3
object_confidence_thres: 0.0001
use_voc07_11point_metric:False
}
}
Parameter |
Datatype |
Default Value |
Description |
Supported Values |
random_seed |
The random seed for the experiment. |
Unsigned int |
42 |
|
enc_key |
The encoding and decoding key for the TLT models, can be override by the command line arguments of tlt-train, tlt-evaluate and tlt-infer for FasterRCNN. |
Str, should not be empty |
||
verbose |
Controls the logging level during the experiments. Will print more logs if True. |
Boolean(True or False) |
False |
|
network_config |
The architecture of the model and its input format. |
message |
||
training_config |
The configurations for the training, evaluation and inference for this experiment. |
message |
Network Config
The network config(network_config) defines the model structure and the its input format. This model is used for training, evaluation and inference. Detailed description is summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
input_image_config |
Defines the input image format, including the image channel number, channel order, width and height, and the preprocessings (subtract per-channel mean and divided by a scaling factor) for it before feeding input the model. See below for details. |
message |
|
input_image _config. image_type |
The image type, can be either RGB or gray-scale image. |
enum type. Either RGB or GRAYSCALE |
RGB |
input_image _config. image_channel_order |
The image channel order. |
str type. If image_type is RGB, ‘rgb’ or ‘bgr’ is valid. If the image_type is GRAYSCALE, only ‘l’ is valid. |
‘bgr’ |
input_image_config. size_height_width |
The height and width as the input dimension of the model. |
message |
|
input_image _config. image_channel_mean |
Per-channel mean value to subtract by for the image preprocessing. |
map(dict) type from channel names to the corresponding mean values. Each of the mean values should be non-negative |
|
input_image _config. image _scaling_factor |
Scaling factor to divide by for the image preprocessing. |
float type, should be a positive scalar. |
1.0 |
input_image _config. max_objects _num_per_image |
The maximum number of objects in an image for the dataset. Usually, the number of objects in different images is different, but there is a maximum number. Setting this field to be no less than this maximum number. This field is used to pad the objects number to the same value so you can make multi-batch and multi-gpu training of FasterRCNN possible. |
unsigned int, should be positive. |
100 |
feature_extractor |
The feature extractor(backbone) for the FasterRCNN model. FasterRCNN supports 12 backbones. Note: FasterRCNN actually supports another backbone: vgg. This backbone is a VGG16 backbone exactly the same as in Keras applications. The layer names matter when loading a pretrained weights. If you want to load a pretrained weights that has the same names as VGG16 in the Keras applications, you should use this backbone. Since this is indeed duplicated with the vgg:16 backbone, you might consider using vgg:16 for production. The only use case for the vgg backbone is to reproduce the original Caffe implementation of VGG16 FasterRCNN that uses ImageNet weights as pretrained weights. |
str type. The architecture can be ResNet, VGG , GoogLeNet, MobileNet or DarkNet. For each specific architecture, it can have different layers or versions. Details listed below. ResNet series: resnet:10, resnet:18, resnet:34, resnet:50, resnet:101 VGG series: vgg:16, vgg:19 GoogLeNet: googlenet MobileNet series: mobilenet_v1, mobilenet_v2 DarkNet: darknet:19, darknet:53 Here a notational convention can be used, i.e., for models that can have different numbers of layers, use a colon followed by the layer number as the suffix of the model name. E.g., resnet:<layer_number> |
|
anchor_box_config |
The anchor box configuration defines the set of anchor box sizes and aspect ratios in a FasterRCNN model. |
Message type that contains two sub-fields: scale and ratio. Each of them is a list of floating point numbers. The scale field defines the absolute anchor sizes in pixels(at input image resolution). The ratio field defines the aspect ratios of each anchor. |
|
freeze_bn |
whether or not to freeze all the BatchNormalization layers in the model. You can choose to freeze the BatchNormalization layers in the model during training. This is a common trick when training a FasterRCNN model. Note: Freezing the BatchNormalization layer will only freeze the moving mean and moving variance in it, while the gamma and beta parameters are still trainable. |
Boolean (True or False) |
If you train with a small batch size, usually you need to set the field to be True and use good pretrained weights to make the training converge well. But if you train with a large batch size(e.g., >=16), you can set it to be False and let the BatchNormalization layer to calculate the moving mean and moving variance by itself. |
freeze_blocks |
The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. You can divide the whole model into several blocks and optionally freeze a subset of it. Note that for FasterRCNN you can only freeze the blocks that are before the ROI pooling layer. Any layer after the ROI pooling layer will not be frozen any way. For different backbones, the number of blocks and the block ID for each block are different. It deserves some detailed explanations on how to specify the block ID’s for each backbone. |
list(repeated integers) ResNet series - For the ResNet series, the block IDs valid for freezing is any subset of [0, 1, 2, 3](inclusive) VGG series - For the VGG series, the block IDs valid for freezing is any subset of[1, 2, 3, 4, 5](inclusive) GoogLeNet- For the GoogLeNet, the block IDs valid for freezing is any subset of[0, 1, 2, 3, 4, 5, 6, 7](inclusive) MobileNet V1- For the MobileNet V1, the block IDs valid for freezing is any subset of [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11](inclusive) MobileNet V2- For the MobileNet V2, the block IDs valid for freezing is any subset of [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13](inclusive) DarkNet - For the DarkNet 19 and DarkNet 53, the block IDs valid for freezing is any subset of [0, 1, 2, 3, 4,5](inclusive) |
Leave it empty([]) |
roi_mini_batch |
The batch size used to train the RCNN after ROI pooling. |
A positive integer, usually uses 128, 256, etc. |
256 |
RPN_stride |
The cumulative stride from the model input to the RPN. This value is fixed(16) for current implementation. |
positive integer |
16 |
conv_bn_share_bias |
A Boolean value to indicate whether or not to share the bias of the convolution layer and the BatchNormalization (BN) layer immediately after it. Usually you share the bias between them to reduce the model size and avoid redundancy of parameters. When using the pretrained weights, make sure the value of this parameter aligns with the actual configuration in the pretrained weights otherwise error will be raised when loading the pretrained weights. |
Boolean (True or False) |
True |
roi_pooling_config |
The configuration for the ROI pooling layer. |
Message type that contains two sub-fields: pool_size and pool_size_2x. See below for details. |
|
roi_pooling_config. pool_size |
The output spatial size(height and width) of ROIs. Only square spatial size is supported currently, i.e. height=width. |
unsigned int, should be positive. |
7 |
roi_pooling_config. pool _size_2x |
A Boolean value to indicate whether to do the ROI pooling at 2*pool_size followed by a 2 x 2 pooling operation or do ROI pooling directly at pool_size without pooling operation. E.g. if pool_size = 7, and pool_size_2x=True, it means you do ROI pooling to get an output that has a spatial size of 14 x 14 followed by a 2 x 2 pooling operation to get the final output tensor. |
Boolean (True or False) |
|
all_projections |
This field is only useful for models that have shortcuts in it. These models include ResNet series and the MobileNet V2. If all_projections =True, all the pass-through shortcuts will be replaced by a projection layer that has the same number of output channels as it. |
Boolean (True or False) |
True |
use_pooling |
This parameter is only useful for VGG series and ResNet series. When use_pooling=True, you can use pooling in the model as the original implementation, otherwise use strided convolution to replace the pooling operations in the model. If you want to improve the inference FPS(Frame Per Second) performance, you can try to set use_pooling=False. |
Boolean (True or False) |
False |
Training Configuration
The training configuration(training_config) defines the parameters needed for the training, evaluation and inference. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
kitti_data_config |
The dataset used for training, evaluation and inference. |
Message type. It has the same structure as the dataset_config message in DetectNet_v2 spec file. Refer to the DetectNet_v2 dataset_config documentation for the details. |
|
data_augmentation |
Defines the data augmentation pipeline during training. |
Message type. It has the same structure as the data_augmentation message in the DetectNet_v2 spec file. Refer to the DetectNet_v2 data_augmentation documentation for the details. |
|
enable_augmentation |
Whether or not to enable the data augmentation during training. If this parameter is False, the training will not have any data augmentation operation even if you have already defined the data augmentation pipeline in the data_augmentation field in spec file. This feature is mostly used for debugging of the data augmentation pipeline. |
Boolean(True or False) |
True |
batch_size_pe_gpu |
The training batch size on each GPU device. The actual total batch size will be batch_size_per_gpu multiplied by the number of GPUs in a multi-gpu training scenario. |
unsigned int, positive. |
Change the batch_size_per _gpu to adapt the capability of your GPU device. |
num_epochs |
The number of epochs for the training. |
unsigned int, positive. |
20 |
pretrained_weights |
Absolute path to the pretrained weights file used to initialize the training model. The pretrained weights file can be either a Keras weights file (with .h5 suffix), a Keras model file (with .hdf5 suffix) or a TLT model (with .tlt suffix, trained by TLT). If the file is a model file (.tlt or .hdf5), TLT will extract the weights from it and then load the weights for initialization. Files with any other formats are not supported as pretrained weights. Note that the pretrained weights file is agnostic to the input dimensions of the FasterRCNN model so the model you are training can have different input dimensions from the input dimensions specified in the pretrained weights. Normally, the pretrained weights file is only useful during the initial training phase in a TLT workflow. |
Str type. Can be left empty. In that case, the FasterRCNN model will use random initialization for its weights. Usually, FasterRCNN model needs a pretrained weights for good convergence of training. |
|
resume_from_model |
Absolute path to the checkpoint .tlt model that you want to resume the training from. This is useful in some cases when the training process is interrupted for some reason and you don’t want to redo the training from epoch 0(or 1 in 1-based indexing). In that case, you can use the last checkpoint as the model you will resume from, to save the training time. |
Str type. Leave it empty when you are not resuming the training, i.e., train from epoch 0. |
|
retrain_pruned_model |
Path to the pruned model that you can load and do the retraining. This is used in the retraining phase in a TLT workflow. The model is the output model of the pruning phase. |
Str type. Leave it empty when you are not in the retraining phase. |
|
output_model |
Absolute path to the output .tlt model that the training/retraining will save. Note that this path is not the actual path of the .tlt models. For example, if the output_model is ‘/workspace/tlt_training/resnet18.tlt’, then the actual output model path will be ‘/workspace/tlt_training/resnet18 .epoch<k>.tlt’where <k> denotes the epoch number of during training. In this way, you can distinguish the output models for different epochs. Here, the epoch number <k> is a 1-based index. |
Str type. Cannot be empty. |
|
checkpoint_interval |
The epoch interval that controls how frequent TLT will save the checkpoint during training. TLT will save the checkpoint at every checkpoint _interval epoch(1 based index). For example, if the num_epochs is 12 and checkpoint _interval is 3, then TLT will save checkpoint at the end of epoch 3, 6, 9, and 12. If this parameter is not specified, then it defaults to checkpoint _interval=1. |
unsigned int, can be omitted(defaults to 1). |
|
rpn_min_overlap |
The lower IoU threshold used to map the anchor boxes to ground truth boxes. If the IoU of an anchor box and any ground truth box is below this threshold, you can treat this anchor box as a negative anchor box. |
Float type, scalar. Should be in the interval (0, 1). |
0.3 |
rpn_max_overlap |
The upper IoU threshold used to map the anchor boxes to ground truth boxes. If the IoU of an anchor box and at least one ground truth box is above this threshold, you can treat this anchor box as a positive anchor box. |
Float type, scalar. Should be in the interval (0, 1) and greater than rpn_min_overlap. |
0.7 |
classifier_min_overlap |
The lower IoU threshold to generate the proposal target. If the IoU of an ROI and a ground truth box is above the threshold and below the classifier_max _overlap, then this ROI is regarded as a negative ROI(background) when training the RCNN. |
floating-point number, scalar. Should be in the interval [0, 1). |
0.0 |
classifier_max_overlap |
Similar to the classifier_min _overlap. If the IoU of a ROI and a ground truth box is above this threshold, then this ROI is regarded as a positive ROI and this ground truth box is treated as the target(ground truth) of this ROI when training the RCNN. |
Float type, scalar. Should be in the interval (0, 1) and greater than classifier_min _overlap. |
0.5 |
gt_as_roi |
A Boolean value to specify whether or not to include the ground truth boxes into the positive ROI to train the RCNN. |
Boolean(True or False) |
False |
std_scaling |
The scaling factor to multiply by for the RPN regression loss when training the RPN. |
Float type, should be positive. |
1.0 |
classifier_regr_std |
The scaling factor to divide by for the RCNN regression loss when training the RCNN. |
map(dict) type. Map from ‘x’, ‘y’, ‘w’, ‘h’ to its corresponding scaling factor. Each of the scaling factors should be a positive float number. |
|
rpn_mini_batc h |
The anchor batch size used to train the RPN. |
unsigned int, positive. |
256 |
rpn_pre_nms_top_N |
The number of boxes to be retained before the NMS in Proposal layer. |
unsigned int, positive. |
|
rpn_nms_max_boxes |
The number of boxes to be retained after the NMS in Proposal layer. |
unsigned int, positive and should be no greater than the rpn_pre_nms_top_N |
|
rpn_nms_overlap_threshold |
The IoU threshold for the NMS in Proposal layer. |
Float type, should be in the interval (0, 1). |
0.7 |
reg_config |
Regularizer configuration of the model weights, including the regularizer type and weight decay. |
message that contains two sub-fields: reg_type and weight_decay. See below for details. |
|
reg_config.reg_type |
The regularizer type. Can be either ‘L1’(L1 regularizer), ‘L2’(L2 regularizer), or ‘none’(No regularizer). |
Str type. Should be one of the below: ‘L1’, ‘L2’, or ‘none’. |
|
reg_config.weight_decay |
The weight decay for the regularizer. |
Float type, should be a positive scalar. Usually this number should be smaller than 1.0 |
|
optimizer |
The Optimizer used for the training. Can be either SGD, RMSProp or Adam. |
oneof message type that can be one of sgd message, rmsprop message or adam message. See below for the details of each message type. |
|
adam |
Adam optimizer. |
message type that contains the 4 sub-fields: lr, beta_1, beta_2, and epsilon. See the Keras 2.2.4 documentation for the meaning of each field. Note: When the learning rate scheduler is enabled, the learning rate in the optimizer is overridden by the learning rate scheduler and the one specified in the optimizer(lr) is irrelevant. |
|
sgd |
SGD optimizer |
message type that contains the following fields: lr, momentum, decayand nesterov. See the Keras 2.2.4 documentation for the meaning of each field. Note: When the learning rate scheduler is enabled, the learning rate in the optimizer is overridden by the learning rate scheduler and the one specified in the optimizer(lr) is irrelevant. |
|
rmsprop |
RMSProp optimizer |
message type that contains only one field: lr(learning rate). Note: When learning rate scheduler is enabled, the learning rate in the optimizer is overridden by the learning rate scheduler and the one specified in the optimizer(lr) is irrelevant. |
|
lr_scheduler |
The learning rate scheduler. |
message type that can be stepor soft_start. stepscheduler is the same as stepscheduler in classification, while soft_startis the same as soft_annealin classification. Refer to the classification spec file documentation for details. |
|
lambda_rpn_regr |
The loss scaling factor for RPN deltas regression loss. |
Float typer. Should be a positive scalar. |
1.0 |
lambda_rpn_class |
The loss scaling factor for RPN classification loss. |
Float type. Should be a positive scalar. |
1.0 |
lambda_cls_regr |
The loss scaling factor for RCNN deltas regression loss. |
Float type. Should be a positive scalar. |
1.0 |
lambda_cls_class |
The loss scaling factor for RCNN classification loss. |
Float type. Should be a positive scalar. |
1.0 |
inference_config |
The inference configuration for tlt-infer. |
message type. See below for details. |
|
inference_config.images_dir |
The absolute path to the image directory that tlt-infer will do inference on. |
Str type. Should be a valid Unix path. |
|
inference_config.model |
The absolute path to the the .tlt model that tlt-infer will do inference for. |
Str type. Should be a valid Unix path. |
|
inference_config.detection _image_output_dir |
The absolute path to the output image directory for the detection result. If the path doesn’t exist tlt-infer will create it. If the directory already contains images tlt-inferwill overwrite them. |
Str type. Should be a valid Unix path. |
|
inference_config.labels _dump_dir |
The absolute path to the directory to save the detected labels in KITTI format. tlt-infer will create it if it doesn’t xist beforehand. If it already contains label files, tlt-infer will overwrite them. |
Str type. Should be a valid Unix path. |
|
inference_config.rpn _pre_nms_top_N |
The number of top ROI’s to be retained before the NMS in Proposal layer. |
unsigned int, positive. |
|
inference_config.rpn _nms_max_boxes |
The number of top ROI’s to be retained after the NMS in Proposal layer. |
unsigned int, positive. |
|
inference_config.rpn_nms _overlap_threshold |
The IoU threshold for the NMS in Proposal layer. |
Float type, should be in the interval (0, 1). |
0.7 |
inference_config.bbox _visualize_threshold |
The confidence threshold for the bounding boxes to be regarded as valid detected objects in the images. |
Float type, should be in the interval (0, 1). |
0.6 |
inference_config.classifier _nms_max_boxes |
The number of bounding boxes to be retained after the NMS in RCNN. |
unsigned int, positive. |
300 |
inference_config.classifier _nms_overlap _threshold |
The IoU threshold for the NMS in RCNN. |
Float type. Should be in the interval (0, 1). |
0.3 |
inference_config.bbox _caption_on |
Whether or not to show captions for each bounding box in the detected images. The captions include the class name and confidence probability value for each detected object. |
Boolean(True or False) |
False |
inference_config.trt _inference |
The TensorRT inference configuration for tlt-inferin TensorRT backend mode. |
Message type. This can be not present, and in this case, tlt-inferwill use TLT as a backend for inference. See below for details. |
|
inference_config.trt _inference.trt_infer_model |
The model configuration for the tlt-inferin TensorRT backend mode. It is a oneof wrapper of the two possible model configurations: trt_engine and etlt_model. Only one of them can be specified if run tlt-infer in TensorRT backend. If trt_engine is provided, tlt-infer will run TensorRT inference on the TensorRT engine file. If .etlt model is provided, tlt-infer will run TensorRT inference on the .etlt model. If in INT8 mode a calibration cache file should also be provided along with the .etlt model. |
message type, oneof wrapper of trt_engineand etlt_model. See below for details. |
|
inference_config.trt _inference.trt_engine |
The absolute path to the TensorRT engine file for tlt-infer in TensorRT backend mode. The engine should be generated via the tlt-exportor tlt-converter command line tools. |
Str type. |
|
inference_config.trt_inference .etlt_model |
The configuration for the .etlt model and the calibration cache(only needed in INT8 mode) for tlt-infer in TensorRT backend mode. The .etlt model(and calibration cache, if needed) should be generated via the tlt-export command line tool. |
message type that contains two string type sub-fields: model and calibration_cache. See below for details. |
|
inference _config.trt _inference.etlt_model.model |
The absolute path to the .etlt model that tlt-infer will use to run TensorRT based inference. |
Str type. |
|
inference_config.trt _inference.etlt _model.calibration _cache |
The path to the TensorRT INT8 calibration cache file in the case of tlt-infer run with.etlt model in INT8 mode. |
Str type. |
|
inference_config.trt _inference.trt_data_type |
The TensorRT inference data type if tlt-infer runs with TensorRT backend. The data type is only useful when running on a .etlt model. In that case, if the data type is ‘int8’, a calibration cache file should also be provided as mentioned above. If running on a TensorRT engine file directly, this field will be ignored since the engine file already contains the data type information. |
String type. Valid values are ‘fp32’, ‘fp16’ and’int8’. |
‘fp32’ |
evaluation_config |
The configuration for the tlt-evaluate in FasterRCNN. |
message type that contains the below fields. See below for details. |
|
evaluation_config.model |
The absolute path to the .tlt model that tlt-evaluate will do evaluation for. |
Str type. Should be a valid Unix path. |
|
evaluation_config.labels _dump_dir |
The absolute path to the directory of detected labels that tlt-evaluate will save. If it doesn’t exist, tlt-evaluate will create it. If it already contains label files, tlt-evaluate will overwrite them. |
Str type. Should be a valid Unix path. |
|
evaluation_config.rpn _pre_nms_top_N |
The number of top ROIs to be retained before the NMS in Proposal layer in tlt-evaluate. |
unsigned int, positive. |
|
evaluation _config.rpn _nms_max_boxes |
The number of top ROIs to be retained after the NMS in Proposal layer in tlt-evaluate. |
unsigned int, positive. Should be no greater than the evaluation_config.rpn _pre_nms_top_N. |
|
evaluation_config.rpn _nms_iou_threshold |
The IoU threshold for the NMS in Proposal layer in tlt-evaluate. |
Float type in the interval (0, 1). |
0.7 |
evaluation_config .classifier_nms_max _boxes |
The number of top bounding boxes to be retained after the NMS in RCNN in tlt-evaluate. |
Unsigned int, positive. |
|
evaluation_config.classifier _nms_overlap_threshold |
The IoU threshold for the NMS in RCNN in tlt-evaluate. |
Float typer in the interval (0, 1). |
0.3 |
evaluation_config.object _confidence_thres |
The confidence threshold above which a bounding box can be regarded as a valid object detected by FasterRCNN. Usually you can use a small threshold to improve the recall and mAP as in many object detection challenges. |
Float type in the interval (0, 1). |
0.0001 |
evaluation_config.use_voc07 _11point_metric |
Whether to use the VOC2007 mAP calculation method when computing the mAP of the FasterRCNN model on a specific dataset. If this is False, you can use VOC2012 metric instead. |
Boolean (True or False) |
False |
Here is a sample of the SSD spec file. It has 6 major components: ssd_config,
training_config, eval_config, nms_config, augmentation_config,
and dataset_config. The format of the spec file is a protobuf text(prototxt) message
and each of its fields can be either a basic data type or a nested message.
random_seed: 42
ssd_config {
aspect_ratios_global: "[1.0, 2.0, 0.5, 3.0, 1.0/3.0]"
scales: "[0.05, 0.1, 0.25, 0.4, 0.55, 0.7, 0.85]"
two_boxes_for_ar1: true
clip_boxes: false
loss_loc_weight: 0.8
focal_loss_alpha: 0.25
focal_loss_gamma: 2.0
variances: "[0.1, 0.1, 0.2, 0.2]"
arch: "resnet"
nlayers: 18
freeze_bn: false
freeze_blocks: 0
}
training_config {
batch_size_per_gpu: 16
num_epochs: 80
enable_qat: false
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 5e-5
max_learning_rate: 2e-2
soft_start: 0.15
annealing: 0.8
}
}
regularizer {
type: L1
weight: 3e-5
}
}
eval_config {
validation_period_during_training: 10
average_precision_mode: SAMPLE
batch_size: 16
matching_iou_threshold: 0.5
}
nms_config {
confidence_threshold: 0.01
clustering_iou_threshold: 0.6
top_k: 200
}
augmentation_config {
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
crop_right: 1248
crop_bottom: 384
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 0.7
zoom_max: 1.8
translate_max_x: 8.0
translate_max_y: 8.0
}
color_augmentation {
hue_rotation_max: 25.0
saturation_shift_max: 0.20000000298
contrast_scale_max: 0.10000000149
contrast_center: 0.5
}
}
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tlt-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tlt-experiments/data/training"
}
image_extension: "png"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}
The top level structure of the spec file is summarized in the table below.
Training Config
The training configuration(training_config) defines the parameters needed for the training,
evaluation and inference. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
batch_size_per_gpu |
The batch size for each GPU, so the effective batch size is batch_size_per_gpu * num_gpus |
Unsigned int, positive |
|
num_epochs |
The anchor batch size used to train the RPN. |
Unsigned int, positive |
|
enable_qat |
Whether to use quantization aware training |
Boolean |
|
learning_rate |
Only soft_start_annealing_schedule with these nested parameters is supported.
|
Message type |
|
regularizer |
This parameter configures the regularizer to be used while training and contains the following nested parameters.
|
Message type |
L1 Note: NVIDIA suggests using L1 regularizer when training a network before pruning as L1 regularization helps making the network weights more prunable. |
Evaluation Config
The evaluation configuration (eval_config) defines the parameters needed for the evaluation
either during training or standalone. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
validation_period_during_training |
The number of training epochs per which one validation should run. |
Unsigned int, positive |
10 |
average_precision_mode |
Average Precision (AP) calculation mode can be either SAMPLE or INTEGRATE. SAMPLE is used as VOC metrics for VOC 2009 or before. INTEGRATE is used for VOC 2010 or after that. |
ENUM type ( SAMPLE or INTEGRATE) |
SAMPLE |
matching_iou_threshold |
The lowest iou of predicted box and ground truth box that can be considered a match. |
Boolean |
0.5 |
NMS Config
The NMS configuration (nms_config) defines the parameters needed for the NMS postprocessing. NMS config applies to the NMS layer of the model in training, validation, evaluation, inference and export. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
confidence_threshold |
Boxes with a confidence score less than confidence_threshold are discarded before applying NMS |
float |
0.01 |
cluster_iou_threshold |
IOU threshold below which boxes will go through NMS process |
float |
0.6 |
top_k |
top_k boxes will be outputted after the NMS keras layer. If the number of valid boxes is less than k, the returned array will be padded with boxes whose confidence score is 0. |
Unsigned int |
200 |
Augmentation Config
The augmentation configuration (augmentation_config) defines the parameters needed
for data augmentation. The configuration is shared with DetectNet_v2. See
Augmentation Module for more information.
Dataset Config
The dataset configuration (dataset_config) defines the parameters needed for the data
loader. The configuration is shared with DetectNet_v2. See Dataloader for
more information.
SSD config
The SSD configuration (ssd_config) defines the parameters needed for building the SSD model.
Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
aspect_ratios_global |
Anchor boxes of aspect ratios defined in aspect_ratios_global will be generated for each feature layer used for prediction. Note: Only one of aspect_ratios_global or aspect_ratios is required. |
string |
“[1.0, 2.0, 0.5, 3.0, 0.33]” |
aspect_ratios |
The length of the outer list must be equivalent to the number of feature layers used for anchor box generation. And the i-th layer will have anchor boxes with aspect ratios defined in aspect_ratios[i]. Note: Only one of aspect_ratios_global or aspect_ratios is required. |
string |
“[[1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0, 2.0, 0.5, 3.0, 0.33]]” |
two_boxes_for_ar1 |
This setting is only relevant for layers that have 1.0 as the aspect ratio. If two_boxes_for_ar1 is true, two boxes will be generated with an aspect ratio of 1. One whose scale is the scale for this layer and the other one whose scale is the geometric mean of the scale for this layer and the scale for the next layer. |
Boolean |
True |
clip_boxes |
If true, all corner anchor boxes will be truncated so they are fully inside the feature images. |
Boolean |
False |
scales |
scales is a list of positive floats containing scaling factors per convolutional predictor layer. This list must be one element longer than the number of predictor layers, so if two_boxes_for_ar1 is true, the second aspect ratio 1.0 box for the last layer can have a proper scale. Except for the last element in this list, each positive float is the scaling factor for boxes in that layer. For example, if for one layer the scale is 0.1, then the generated anchor box with aspect ratio 1 for that layer (the first aspect ratio 1 box if two_boxes_for_ar1 is true) will have its height and width as 0.1*min(img_h, img_w). min_scale and max_scale are two positive floats. If both of them appear in the config, the program can automatically generate the scales by evenly splitting the space between min_scale and max_scale. |
string |
“[0.05, 0.1, 0.25, 0.4, 0.55, 0.7, 0.85]” |
min_scale/max_scale |
If both appear in the config, scales will be generated evenly by splitting the space between min_scale and max_scale. |
float |
|
loss_loc_weight |
This is a positive float controlling how much location regression loss should contribute to the final loss. The final loss is calculated as classification_loss + loss_loc_weight * loc_loss |
float |
1.0 |
focal_loss_alpha |
Alpha is the focal loss equation. |
float |
0.25 |
focal_loss_gamma |
Gamma is the focal loss equation. |
float |
2.0 |
variances |
Variances should be a list of 4 positive floats. The four floats, in order, represent variances for box center x, box center y, log box height, log box width. The box offset for box center (cx, cy) and log box size (height/width) w.r.t. anchor will be divided by their respective variance value. Therefore, larger variances result in less significant differences between two different boxes on encoded offsets. |
||
steps |
An optional list inside quotation marks whose length is the number of feature layers for prediction. The elements should be floats or tuples/lists of two floats. Steps define how many pixels apart the anchor box center points should be. If the element is a float, both vertical and horizontal margin is the same. Otherwise, the first value is step_vertical and the second value is step_horizontal. If steps are not provided, anchor boxes will be distributed uniformly inside the image. |
string |
|
offsets |
An optional list of floats inside quotation marks whose length is the number of feature layers for prediction. The first anchor box will have offsets[i]*steps[i] pixels margin from the left and top borders. If offsets are not provided, 0.5 will be used as default value. |
string |
|
arch |
Backbone for feature extraction. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet” are supported. |
string |
resnet |
nlayers |
Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. |
Unsigned int |
|
freeze_bn |
Whether to freeze all batch normalization layers during training. |
boolean |
False |
freeze_blocks |
The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. You can divide the whole model into several blocks and optionally freeze a subset of it. Note that for FasterRCNN you can only freeze the blocks that are before the ROI pooling layer. Any layer after the ROI pooling layer will not be frozen any way. For different backbones, the number of blocks and the block ID for each block are different. It deserves some detailed explanations on how to specify the block ID’s for each backbone. |
list(repeated integers)
|
Below is a sample for the DSSD spec file. It has 6 major components: dssd_config,
training_config, eval_config, nms_config, augmentation_config,
and dataset_config. The format of the spec file is a protobuf text (prototxt) message and
each of its fields can be either a basic data type or a nested message. The top level structure
of the spec file is summarized in the table below.
random_seed: 42
dssd_config {
aspect_ratios_global: "[1.0, 2.0, 0.5, 3.0, 1.0/3.0]"
scales: "[0.05, 0.1, 0.25, 0.4, 0.55, 0.7, 0.85]"
two_boxes_for_ar1: true
clip_boxes: false
loss_loc_weight: 0.8
focal_loss_alpha: 0.25
focal_loss_gamma: 2.0
variances: "[0.1, 0.1, 0.2, 0.2]"
arch: "resnet"
nlayers: 18
pred_num_channels: 512
freeze_bn: false
freeze_blocks: 0
}
training_config {
batch_size_per_gpu: 16
num_epochs: 80
enable_qat: false
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 5e-5
max_learning_rate: 2e-2
soft_start: 0.15
annealing: 0.8
}
}
regularizer {
type: L1
weight: 3e-5
}
}
eval_config {
validation_period_during_training: 10
average_precision_mode: SAMPLE
batch_size: 16
matching_iou_threshold: 0.5
}
nms_config {
confidence_threshold: 0.01
clustering_iou_threshold: 0.6
top_k: 200
}
augmentation_config {
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
crop_right: 1248
crop_bottom: 384
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 0.7
zoom_max: 1.8
translate_max_x: 8.0
translate_max_y: 8.0
}
color_augmentation {
hue_rotation_max: 25.0
saturation_shift_max: 0.20000000298
contrast_scale_max: 0.10000000149
contrast_center: 0.5
}
}
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tlt-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tlt-experiments/data/training"
}
image_extension: "png"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}
Training Config
The training configuration (training_config) defines the parameters needed for the
training, evaluation and inference. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
batch_size_per_gpu |
The batch size for each GPU, so the effective batch size is batch_size_per_gpu * num_gpus |
Unsigned int, positive |
|
num_epochs |
The anchor batch size used to train the RPN. |
Unsigned int, positive. |
|
enable_qat |
Whether to use quantization aware training |
Boolean |
|
learning_rate |
Only soft_start_annealing_schedule with these nested parameters is supported.
|
Message type. |
|
regularizer |
This parameter configures the regularizer to be used while training and contains the following nested parameters:
|
Message type. |
L1 (Note: NVIDIA suggests using L1 regularizer when training a network before pruning as L1 regularization helps making the network weights more prunable.) |
Evaluation Config
The evaluation configuration (eval_config) defines the parameters needed for the evaluation
either during training or standalone. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
validation_period_during_training |
The number of training epochs per which one validation should run. |
Unsigned int, positive |
10 |
average_precision_mode |
Average Precision (AP) calculation mode can be either SAMPLE or INTEGRATE. SAMPLE is used as VOC metrics for VOC 2009 or before. INTEGRATE is used for VOC 2010 or after that. |
ENUM type ( SAMPLE or INTEGRATE) |
SAMPLE |
matching_iou_threshold |
The lowest iou of predicted box and ground truth box that can be considered a match. |
Boolean |
0.5 |
NMS Config
The NMS configuration (nms_config) defines the parameters needed for the NMS postprocessing.
NMS config applies to the NMS layer of the model in training, validation, evaluation, inference
and export. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
confidence_threshold |
Boxes with a confidence score less than confidence_threshold are discarded before applying NMS |
float |
0.01 |
cluster_iou_threshold |
IOU threshold below which boxes will go through NMS process |
float |
0.6 |
top_k |
top_k boxes will be outputted after the NMS keras layer. If the number of valid boxes is less than k, the returned array will be padded with boxes whose confidence score is 0. |
Unsigned int |
200 |
Augmentation Config
The augmentation configuration (augmentation_config) defines the parameters needed for data
augmentation. The configuration is shared with DetectNet_v2. See Augmentation module for more
information.
Dataset Config
The dataset configuration (dataset_config) defines the parameters needed for the data
loader. The configuration is shared with DetectNet_v2. See Dataloader for more information.
DSSD Config
The DSSD configuration (dssd_config) defines the parameters needed for building the DSSD
model. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
aspect_ratios_global |
Anchor boxes of aspect ratios defined in aspect_ratios_global will be generated for each feature layer used for prediction. Note: Only one of aspect_ratios_global or aspect_ratios is required. |
string |
“[1.0, 2.0, 0.5, 3.0, 0.33]” |
aspect_ratios |
The length of the outer list must be equivalent to the number of feature layers used for anchor box generation. And the i-th layer will have anchor boxes with aspect ratios defined in aspect_ratios[i]. Note: Only one of aspect_ratios_global or aspect_ratios is required. |
string |
“[[1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0, 2.0, 0.5, 3.0, 0.33]]” |
two_boxes_for_ar1 |
This setting is only relevant for layers that have 1.0 as the aspect ratio. If two_boxes_for_ar1 is true, two boxes will be generated with an aspect ratio of 1. One whose scale is the scale for this layer and the other one whose scale is the geometric mean of the scale for this layer and the scale for the next layer. |
Boolean |
True |
clip_boxes |
If true, all corner anchor boxes will be truncated so they are fully inside the feature images. |
Boolean |
False |
scales |
scales is a list of positive floats containing scaling factors per convolutional predictor layer. This list must be one element longer than the number of predictor layers, so if two_boxes_for_ar1 is true, the second aspect ratio 1.0 box for the last layer can have a proper scale. Except for the last element in this list, each positive float is the scaling factor for boxes in that layer. For example, if for one layer the scale is 0.1, then the generated anchor box with aspect ratio 1 for that layer (the first aspect ratio 1 box if two_boxes_for_ar1 is true) will have its height and width as 0.1*min(img_h, img_w). min_scale and max_scale are two positive floats. If both of them appear in the config, the program can automatically generate the scales by evenly splitting the space between min_scale and max_scale. |
string |
“[0.05, 0.1, 0.25, 0.4, 0.55, 0.7, 0.85]” |
min_scale/max_scale |
If both appear in the config, scales will be generated evenly by splitting the space between min_scale and max_scale. |
float |
|
loss_loc_weight |
This is a positive float controlling how much location regression loss should contribute to the final loss. The final loss is calculated as classification_loss + loss_loc_weight * loc_loss |
float |
1.0 |
focal_loss_alpha |
Alpha is the focal loss equation. |
float |
0.25 |
focal_loss_gamma |
Gamma is the focal loss equation. |
float |
2.0 |
variances |
Variances should be a list of 4 positive floats. The four floats, in order, represent variances for box center x, box center y, log box height, log box width. The box offset for box center (cx, cy) and log box size (height/width) w.r.t. anchor will be divided by their respective variance value. Therefore, larger variances result in less significant differences between two different boxes on encoded offsets. |
||
steps |
An optional list inside quotation marks whose length is the number of feature layers for prediction. The elements should be floats or tuples/lists of two floats. Steps define how many pixels apart the anchor box center points should be. If the element is a float, both vertical and horizontal margin is the same. Otherwise, the first value is step_vertical and the second value is step_horizontal. If steps are not provided, anchor boxes will be distributed uniformly inside the image. |
string |
|
offsets |
An optional list of floats inside quotation marks whose length is the number of feature layers for prediction. The first anchor box will have offsets[i]*steps[i] pixels margin from the left and top borders. If offsets are not provided, 0.5 will be used as default value. |
string |
|
arch |
Backbone for feature extraction. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet” are supported. |
string |
resnet |
nlayers |
Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. |
Unsigned int |
|
pred_num_channels |
This setting controls the number of channels of the convolutional layers in the DSSD prediction module. Setting this value to 0 will disable the DSSD prediction module. Supported values for this setting are 0, 256, 512 and 1024. A larger value gives a larger network and usually means the network is harder to train. |
Unsigned int |
512 |
freeze_bn |
Whether to freeze all batch normalization layers during training. |
boolean |
False |
freeze_blocks |
The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. You can divide the whole model into several blocks and optionally freeze a subset of it. Note that for FasterRCNN you can only freeze the blocks that are before the ROI pooling layer. Any layer after the ROI pooling layer will not be frozen any way. For different backbones, the number of blocks and the block ID for each block are different. It deserves some detailed explanations on how to specify the block ID’s for each backbone. |
list(repeated integers)
|
dssd_config {
aspect_ratios_global: "[1.0, 2.0, 0.5, 3.0, 0.33]"
scales: "[0.1, 0.24166667, 0.38333333, 0.525, 0.66666667, 0.80833333, 0.95]"
two_boxes_for_ar1: true
clip_boxes: false
loss_loc_weight: 1.0
focal_loss_alpha: 0.25
focal_loss_gamma: 2.0
variances: "[0.1, 0.1, 0.2, 0.2]"
pred_num_channels: 0
arch: "resnet"
nlayers: 18
freeze_bn: True
freeze_blocks: 0
freeze_blocks: 1}
Using aspect_ratios_global or aspect_ratios
Only aspect_ratios_global or aspect_ratios is required.
aspect_ratios_global should be a 1-d array inside quotation marks. Anchor boxes of aspect
ratios defined in aspect_ratios_global will be generated for each feature layer used for
prediction. Example: “[1.0, 2.0, 0.5, 3.0, 0.33]”
aspect_ratios should be a list of lists inside quotation marks. The length of the outer
list must be equivalent to the number of feature layers used for anchor box generation. And the
i-th layer will have anchor boxes with aspect ratios defined in aspect_ratios[i]. Here’s an
example:
"[[1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0, 2.0, 0.5, 3.0, 0.33]]"
two_boxes_for_ar1
This setting is only relevant for layers that have 1.0 as the aspect ratio. If
two_boxes_for_ar1 is true, two boxes will be generated with an aspect ratio of 1. One
whose scale is the scale for this layer and the other one whose scale is the geometric mean of
the scale for this layer and the scale for the next layer.
scales or Combination of min_scale and max_scale
Only scales or the combination of min_scale and max_scale
is required.
scales should be a 1-d array inside quotation marks. It is a list of positive floats
containing scaling factors per convolutional predictor layer. This list must be one element
longer than the number of predictor layers, so if two_boxes_for_ar1 is true, the second
aspect ratio 1.0 box for the last layer can have a proper scale. Except for the last element in
this list, each positive float is the scaling factor for boxes in that layer. For example, if for
one layer the scale is 0.1, then the generated anchor box with aspect ratio 1 for that layer
(the first aspect ratio 1 box if two_boxes_for_ar1 is true) will have its height and width
as 0.1*min(img_h, img_w).
min_scale and max_scale are two positive floats. If both of them appear in the
config, the program can automatically generate the scales by evenly splitting the space between
min_scale and max_scale.
clip_boxes
If true, all corner anchor boxes will be truncated so they are fully inside the feature images.
loss_loc_weight
This is a positive float controlling how much location regression loss should contribute to the final loss. The final loss is calculated as classification_loss + loss_loc_weight * loc_loss.
focal_loss_alpha and focal_loss_gamma
Focal loss is calculated as:

focal_loss_alpha defines α and focal_loss_gamma defines γ in the formula.
NVIDIA recommends α=0.25 and γ=2.0 if you don’t know what values to use.
variances
Variances should be a list of 4 positive floats. The four floats, in order, represent variances for box center x, box center y, log box height, log box width. The box offset for box center (cx, cy) and log box size (height/width) w.r.t. anchor will be divided by their respective variance value. Therefore, larger variances result in less significant differences between two different boxes on encoded offsets. The formula for offset calculation is:
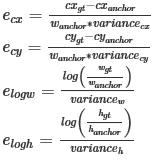
steps
An optional list inside quotation marks whose length is the number of feature layers for
prediction. The elements should be floats or tuples/lists of two floats. Steps define how
many pixels apart the anchor box center points should be. If the element is a float, both
vertical and horizontal margin is the same. Otherwise, the first value is step_vertical
and the second value is step_horizontal. If steps are not provided, anchorboxes will be
distributed uniformly inside the image.
offsets
An optional list of floats inside quotation marks whose length is the number of feature layers for prediction. The first anchor box will have offsets[i]*steps[i] pixels margin from the left and top borders. If offsets are not provided, 0.5 will be used as default value.
arch
A string indicating which feature extraction architecture you want to use. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet” are supported.
nlayers
An integer specifying the number of layers of the selected arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file.
freeze_bn
Whether to freeze all batch normalization layers during training.
freeze_blocks
Optionally, you can have more than 1 freeze_blocks field. Weights of layers in those blocks
will be freezed during training. See Model config for more information.
Below is a sample for the RetinaNet spec file. It has 6 major components:
retinanet_config, training_config, eval_config, nms_config,
augmentation_config and dataset_config. The format of the spec file is a protobuf
text (prototxt) message and each of its fields can be either a basic data type or a nested
message. The top level structure of the spec file is summarized in the table below:
random_seed: 42
retinanet_config {
aspect_ratios_global: "[1.0, 2.0, 0.5]"
scales: "[0.045, 0.09, 0.2, 0.4, 0.55, 0.7]"
two_boxes_for_ar1: false
clip_boxes: false
loss_loc_weight: 0.8
focal_loss_alpha: 0.25
focal_loss_gamma: 2.0
variances: "[0.1, 0.1, 0.2, 0.2]"
arch: "resnet"
nlayers: 18
n_kernels: 1
feature_size: 256
freeze_bn: false
freeze_blocks: 0
}
training_config {
enable_qat: False
batch_size_per_gpu: 24
num_epochs: 100
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 4e-5
max_learning_rate: 1.5e-2
soft_start: 0.15
annealing: 0.5
}
}
regularizer {
type: L1
weight: 2e-5
}
}
eval_config {
validation_period_during_training: 10
average_precision_mode: SAMPLE
batch_size: 32
matching_iou_threshold: 0.5
}
nms_config {
confidence_threshold: 0.01
clustering_iou_threshold: 0.6
top_k: 200
}
augmentation_config {
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
crop_right: 1248
crop_bottom: 384
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 0.7
zoom_max: 1.8
translate_max_x: 8.0
translate_max_y: 8.0
}
color_augmentation {
hue_rotation_max: 25.0
saturation_shift_max: 0.2
contrast_scale_max: 0.1
contrast_center: 0.5
}
}
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tlt-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tlt-experiments/data/training"
}
image_extension: "png"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}
Training Config
The training configuration(training_config) defines the parameters needed for the training,
evaluation and inference. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
batch_size_per_gpu |
The batch size for each GPU, so the effective batch size is batch_size_per_gpu * num_gpus |
Unsigned int, positive |
|
num_epochs |
The anchor batch size used to train the RPN. |
Unsigned int, positive. |
|
enable_qat |
Whether to use quantization aware training |
Boolean |
|
learning_rate |
Only soft_start_annealing_schedule with these nested parameters is supported.
|
Message type. |
|
regularizer |
This parameter configures the regularizer to be used while training and contains the following nested parameters.
|
Message type. |
L1 (Note: NVIDIA suggests using L1 regularizer when training a network before pruning as L1 regularization helps making the network weights more prunable.) |
Evaluation Config
The evaluation configuration (eval_config) defines the parameters needed for the evaluation
either during training or standalone. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
validation_period_during_training |
The number of training epochs per which one validation should run. |
Unsigned int, positive |
10 |
average_precision_mode |
Average Precision (AP) calculation mode can be either SAMPLE or INTEGRATE. SAMPLE is used as VOC metrics for VOC 2009 or before. INTEGRATE is used for VOC 2010 or after that. |
ENUM type ( SAMPLE or INTEGRATE) |
SAMPLE |
matching_iou_threshold |
The lowest iou of predicted box and ground truth box that can be considered a match. |
Boolean |
0.5 |
NMS Config
The NMS configuration (nms_config) defines the parameters needed for the NMS postprocessing.
NMS config applies to the NMS layer of the model in training, validation, evaluation, inference
and export. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
confidence_threshold |
Boxes with a confidence score less than confidence_threshold are discarded before applying NMS |
float |
0.01 |
cluster_iou_threshold |
IOU threshold below which boxes will go through NMS process |
float |
0.6 |
top_k |
top_k boxes will be outputted after the NMS keras layer. If the number of valid boxes is less than k, the returned array will be padded with boxes whose confidence score is 0. |
Unsigned int |
200 |
Augmentation Config
The augmentation configuration (augmentation_config) defines the parameters needed for data
augmentation. The configuration is shared with DetectNet_v2. See Augmentation Module for more information.
Dataset Config
The dataset configuration (dataset_config) defines the parameters needed for the data
loader. The configuration is shared with DetectNet_v2. See Dataloader for more
information.
RetinaNet Config
The RetinaNet configuration (retinanet_config) defines the parameters needed for
building the RetinaNet model. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
aspect_ratios_global |
Anchor boxes of aspect ratios defined in aspect_ratios_global will be generated for each feature layer used for prediction. Note: Only one of aspect_ratios_global or aspect_ratios is required. |
string |
“[1.0, 2.0, 0.5]” |
aspect_ratios |
The length of the outer list must be equivalent to the number of feature layers used for anchor box generation. And the i-th layer will have anchor boxes with aspect ratios defined in aspect_ratios[i]. Note: Only one of aspect_ratios_global or aspect_ratios is required. |
string |
“[[1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0,2.0,0.5], [1.0, 2.0, 0.5, 3.0, 0.33]]” |
two_boxes_for_ar1 |
This setting is only relevant for layers that have 1.0 as the aspect ratio. If two_boxes_for_ar1 is true, two boxes will be generated with an aspect ratio of 1. One whose scale is the scale for this layer and the other one whose scale is the geometric mean of the scale for this layer and the scale for the next layer. |
Boolean |
True |
clip_boxes |
If true, all corner anchor boxes will be truncated so they are fully inside the feature images. |
Boolean |
False |
scales |
scales is a list of positive floats containing scaling factors per convolutional predictor layer. This list must be one element longer than the number of predictor layers, so if two_boxes_for_ar1 is true, the second aspect ratio 1.0 box for the last layer can have a proper scale. Except for the last element in this list, each positive float is the scaling factor for boxes in that layer. For example, if for one layer the scale is 0.1, then the generated anchor box with aspect ratio 1 for that layer (the first aspect ratio 1 box if two_boxes_for_ar1 is true) will have its height and width as 0.1*min(img_h, img_w). min_scale and max_scale are two positive floats. If both of them appear in the config, the program can automatically generate the scales by evenly splitting the space between min_scale and max_scale. |
string |
“[0.05, 0.1, 0.25, 0.4, 0.55, 0.7, 0.85]” |
min_scale/max_scale |
If both appear in the config, scales will be generated evenly by splitting the space between min_scale and max_scale. |
float |
|
loss_loc_weight |
This is a positive float controlling how much location regression loss should contribute to the final loss. The final loss is calculated as classification_loss + loss_loc_weight * loc_loss |
float |
1.0 |
focal_loss_alpha |
Alpha is the focal loss equation. |
float |
0.25 |
focal_loss_gamma |
Gamma is the focal loss equation. |
float |
2.0 |
variances |
Variances should be a list of 4 positive floats. The four floats, in order, represent variances for box center x, box center y, log box height, log box width. The box offset for box center (cx, cy) and log box size (height/width) w.r.t. anchor will be divided by their respective variance value. Therefore, larger variances result in less significant differences between two different boxes on encoded offsets. |
||
steps |
An optional list inside quotation marks whose length is the number of feature layers for prediction. The elements should be floats or tuples/lists of two floats. Steps define how many pixels apart the anchor box center points should be. If the element is a float, both vertical and horizontal margin is the same. Otherwise, the first value is step_vertical and the second value is step_horizontal. If steps are not provided, anchor boxes will be distributed uniformly inside the image. |
string |
|
offsets |
An optional list of floats inside quotation marks whose length is the number of feature layers for prediction. The first anchor box will have offsets[i]*steps[i] pixels margin from the left and top borders. If offsets are not provided, 0.5 will be used as default value. |
string |
|
arch |
Backbone for feature extraction. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet” are supported. |
string |
resnet |
nlayers |
Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. |
Unsigned int |
|
freeze_bn |
Whether to freeze all batch normalization layers during training. |
boolean |
False |
freeze_blocks |
The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. You can divide the whole model into several blocks and optionally freeze a subset of it. Note that for FasterRCNN you can only freeze the blocks that are before the ROI pooling layer. Any layer after the ROI pooling layer will not be frozen any way. For different backbones, the number of blocks and the block ID for each block are different. It deserves some detailed explanations on how to specify the block ID’s for each backbone. |
list(repeated integers)
|
|
n_kernels |
This setting controls the number of convolutional layers in the RetinaNet subnets for classification and anchor box regression. A larger value generates a larger network and usually means the network is harder to train. |
Unsigned int |
2 |
feature_size |
This setting controls the number of channels of the convolutional layers in the RetinaNet subnets for classification and anchor box regression. A larger value gives a larger network and usually means the network is harder to train. Note that RetinaNet FPN generates 5 feature maps, thus the scales field requires a list of 6 scaling factors. The last number is not used if two_boxes_for_ar1 is set to False. There are also three underlying scaling factors at each feature map level (2^0, 2^⅓, 2^⅔ ). |
Unsigned int |
256 |
Focal loss is calculated as follows:
Variances:
Below is a sample for the YOLOv3 spec file. It has 6 major components: yolo_config,
training_config, eval_config, nms_config, augmentation_config, and
dataset_config. The format of the spec file is a protobuf text (prototxt) message and each
of its fields can be either a basic data type or a nested message. The top level structure of the
spec file is summarized in the table below.
random_seed: 42
yolo_config {
big_anchor_shape: "[(116,90), (156,198), (373,326)]"
mid_anchor_shape: "[(30,61), (62,45), (59,119)]"
small_anchor_shape: "[(10,13), (16,30), (33,23)]"
matching_neutral_box_iou: 0.5
arch: "darknet"
nlayers: 53
arch_conv_blocks: 2
loss_loc_weight: 5.0
loss_neg_obj_weights: 50.0
loss_class_weights: 1.0
freeze_bn: True
freeze_blocks: 0
freeze_blocks: 1}
training_config {
batch_size_per_gpu: 16
num_epochs: 80
enable_qat: false
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 5e-5
max_learning_rate: 2e-2
soft_start: 0.15
annealing: 0.8
}
}
regularizer {
type: L1
weight: 3e-5
}
}
eval_config {
validation_period_during_training: 10
average_precision_mode: SAMPLE
batch_size: 16
matching_iou_threshold: 0.5
}
nms_config {
confidence_threshold: 0.01
clustering_iou_threshold: 0.6
top_k: 200
}
augmentation_config {
preprocessing {
output_image_width: 1248
output_image_height: 384
output_image_channel: 3
crop_right: 1248
crop_bottom: 384
min_bbox_width: 1.0
min_bbox_height: 1.0
}
spatial_augmentation {
hflip_probability: 0.5
vflip_probability: 0.0
zoom_min: 0.7
zoom_max: 1.8
translate_max_x: 8.0
translate_max_y: 8.0
}
color_augmentation {
hue_rotation_max: 25.0
saturation_shift_max: 0.20000000298
contrast_scale_max: 0.10000000149
contrast_center: 0.5
}
}
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tlt-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tlt-experiments/data/training"
}
image_extension: "png"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}
Training Config
The training configuration(training_config) defines the parameters needed for the
training, evaluation and inference. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
batch_size_per_gpu |
The batch size for each GPU, so the effective batch size is batch_size_per_gpu * num_gpus |
Unsigned int, positive |
|
num_epochs |
The anchor batch size used to train the RPN |
Unsigned int, positive. |
|
enable_qat |
Whether to use quantization aware training |
Boolean |
|
learning_rate |
Only soft_start_annealing_schedule with these nested parameters is supported.
|
Message type. |
|
regularizer |
This parameter configures the regularizer to be used while training and contains the following nested parameters.
|
Message type. |
L1 (Note: NVIDIA suggests using L1 regularizer when training a network before pruning as L1 regularization helps making the network weights more prunable.) |
Evaluation Config
The evaluation configuration (eval_config) defines the parameters needed for the
evaluation either during training or standalone. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
validation_period_during_training |
The number of training epochs per which one validation should run. |
Unsigned int, positive |
10 |
average_precision_mode |
Average Precision (AP) calculation mode can be either SAMPLE or INTEGRATE. SAMPLE is used as VOC metrics for VOC 2009 or before. INTEGRATE is used for VOC 2010 or after that. |
ENUM type ( SAMPLE or INTEGRATE) |
SAMPLE |
matching_iou_threshold |
The lowest iou of predicted box and ground truth box that can be considered a match. |
Boolean |
0.5 |
NMS Config
The NMS configuration (nms_config) defines the parameters needed for the NMS postprocessing.
NMS config applies to the NMS layer of the model in training, validation, evaluation, inference
and export. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
confidence_threshold |
Boxes with a confidence score less than confidence_threshold are discarded before applying NMS |
float |
0.01 |
cluster_iou_threshold |
IOU threshold below which boxes will go through NMS process |
float |
0.6 |
top_k |
top_k boxes will be outputted after the NMS keras layer. If the number of valid boxes is less than k, the returned array will be padded with boxes whose confidence score is 0. |
Unsigned int |
200 |
Augmentation Config
The augmentation configuration (augmentation_config) defines the parameters needed for data
augmentation. The configuration is shared with DetectNet_v2. See Augmentation module for more information.
Dataset Config
The dataset configuration (dataset_config) defines the parameters needed for the data
loader. The configuration is shared with DetectNet_v2. See Dataloader for
more information.
YOLOv3 Config
The YOLOv3 configuration (yolo_config) defines the parameters needed for building the
DSSD model. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
big_anchor_shape, mid_anchor_shape, and small_anchor_shape |
Those settings should be 1-d arrays inside quotation marks. The elements of those arrays are tuples representing the pre-defined anchor shape in the order of width, height. The default YOLOv3 has 9 predefined anchor shapes. They are divided into 3 groups corresponding to big, medium and small objects. The detection output corresponding to different groups are from different depths in the network. Users should run the kmeans.py file attached with the example notebook to determine the best anchor shapes for their own dataset and put those anchor shapes in the spec file. It is worth noting that the number of anchor shapes for any field is not limited to 3. Users only need to specify at least 1 anchor shape in each of those three fields. |
string |
Use kmeans.py attached in examples/yolo inside docker to generate those shapes |
matching_neutral_box_iou |
This field should be a float number between 0 and 1. Any anchor not matching to ground truth boxes, but with IOU higher than this float value with any ground truth box, will not have their objectiveness loss back-propagated during training. This is to reduce false negatives. |
float |
0.5 |
arch_conv_blocks |
Supported values are 0, 1 and 2. This value controls how many convolutional blocks are present among detection output layers. Setting this value to 2 if you want to reproduce the meta architecture of the original YOLOv3 model coming with DarkNet 53. Please note this config setting only controls the size of the YOLO meta architecture and the size of the feature extractor has nothing to do with this config field. |
0, 1 or 2 |
2 |
loss_loc_weight, loss_neg_obj_weights, and loss_class_weights |
Those loss weights can be configured as float numbers. The YOLOv3 loss is a summation of localization loss, negative objectiveness loss, positive objectiveness loss and classification loss. The weight of positive objectiveness loss is set to 1 while the weights of other losses are read from config file. |
float |
loss_loc_weight: 5.0 loss_neg_obj_weights: 50.0 loss_class_weights: 1.0 |
arch |
Backbone for feature extraction. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet” are supported. |
string |
resnet |
nlayers |
Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. |
Unsigned int |
|
freeze_bn |
Whether to freeze all batch normalization layers during training. |
boolean |
False |
freeze_blocks |
The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. You can divide the whole model into several blocks and optionally freeze a subset of it. Note that for FasterRCNN you can only freeze the blocks that are before the ROI pooling layer. Any layer after the ROI pooling layer will not be frozen any way. For different backbones, the number of blocks and the block ID for each block are different. It deserves some detailed explanations on how to specify the block ID’s for each backbone. |
list(repeated integers)
|
Below is a sample for the MaskRCNN spec file. It has 3 major components: top level experiment
configs, data_config and maskrcnn_config, explained below in detail. The format of
the spec file is a protobuf text (prototxt) message and each of its fields can be either a
basic data type or a nested message. The top level structure of the spec file is summarized in
the table below.
Here’s a sample of the MaskRCNN spec file:
seed: 123
use_amp: False
warmup_steps: 0
checkpoint: "/workspace/tlt-experiments/maskrcnn/pretrained_resnet50/tlt_instance_segmentation_vresnet50/resnet50.hdf5"
learning_rate_steps: "[60000, 80000, 100000]"
learning_rate_decay_levels: "[0.1, 0.02, 0.002]"
total_steps: 120000
train_batch_size: 2
eval_batch_size: 4
num_steps_per_eval: 10000
momentum: 0.9
l2_weight_decay: 0.0001
warmup_learning_rate: 0.0001
init_learning_rate: 0.02
data_config{
image_size: "(832, 1344)"
augment_input_data: True
eval_samples: 500
training_file_pattern: "/workspace/tlt-experiments/data/train*.tfrecord"
validation_file_pattern: "/workspace/tlt-experiments/data/val*.tfrecord"
val_json_file: "/workspace/tlt-experiments/data/annotations/instances_val2017.json"
# dataset specific parameters
num_classes: 91
skip_crowd_during_training: True
}
maskrcnn_config {
nlayers: 50
arch: "resnet"
freeze_bn: True
freeze_blocks: "[0,1]"
gt_mask_size: 112
# Region Proposal Network
rpn_positive_overlap: 0.7
rpn_negative_overlap: 0.3
rpn_batch_size_per_im: 256
rpn_fg_fraction: 0.5
rpn_min_size: 0.
# Proposal layer.
batch_size_per_im: 512
fg_fraction: 0.25
fg_thresh: 0.5
bg_thresh_hi: 0.5
bg_thresh_lo: 0.
# Faster-RCNN heads.
fast_rcnn_mlp_head_dim: 1024
bbox_reg_weights: "(10., 10., 5., 5.)"
# Mask-RCNN heads.
include_mask: True
mrcnn_resolution: 28
# training
train_rpn_pre_nms_topn: 2000
train_rpn_post_nms_topn: 1000
train_rpn_nms_threshold: 0.7
# evaluation
test_detections_per_image: 100
test_nms: 0.5
test_rpn_pre_nms_topn: 1000
test_rpn_post_nms_topn: 1000
test_rpn_nms_thresh: 0.7
# model architecture
min_level: 2
max_level: 6
num_scales: 1
aspect_ratios: "[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]"
anchor_scale: 8
# localization loss
rpn_box_loss_weight: 1.0
fast_rcnn_box_loss_weight: 1.0
mrcnn_weight_loss_mask: 1.0
}
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
seed |
The random seed for the experiment. |
Unsigned int |
123 |
warmup_steps |
The steps taken for learning rate to ramp up to the init_learning_rate. |
Unsigned int |
|
warmup_learning_rate |
The initial learning rate during in the warmup phase. |
float |
|
learning_rate_steps |
List of steps, at which the learning rate decays by the factor specified in learning_rate_decay_levels. |
string |
|
learning_rate_decay_levels |
List of decay factors. The length should match the length of learning_rate_steps. |
string |
|
total_steps |
Total number of training iterations. |
Unsigned int |
|
train_batch_size |
Batch size during training. |
Unsigned int |
4 |
eval_batch_size |
Batch size during validation or evaluation. |
Unsigned int |
8 |
num_steps_per_eval |
Save a checkpoint and run evaluation every N steps. |
Unsigned int |
|
momentum |
Momentum of SGD optimizer. |
float |
0.9 |
l2_weight_decay |
L2 weight decay |
float |
0.0001 |
use_amp |
Whether to use Automatic Mixed Precision training. |
boolean |
False |
checkpoint |
Path to a pretrained model. |
string |
|
maskrcnn_config |
The architecture of the model. |
message |
|
data_config |
Input data configuration. |
message |
|
skip_checkpoint_variables |
If specified, the weights of the layers with matching regular expressions will not be loaded. This is especially helpful for transfer learning. |
string |
When using skip_checkpoint_variables, you can first find the model structure in the training log (Part of MaskRCNN+ResNet50 model structure is shown below). If, for example, you want to retrain all prediction heads, you can set skip_checkpoint_variables to “head”. TLT uses Python re library to check whether “head” matches any layer name or re.search($skip_checkpoint_variables, $layer_name).
[MaskRCNN] INFO : ================ TRAINABLE VARIABLES ==================
[MaskRCNN] INFO : [#0001] conv1/kernel:0 => (7, 7, 3, 64)
[MaskRCNN] INFO : [#0002] bn_conv1/gamma:0 => (64,)
[MaskRCNN] INFO : [#0003] bn_conv1/beta:0 => (64,)
[MaskRCNN] INFO : [#0004] block_1a_conv_1/kernel:0 => (1, 1, 64, 64)
[MaskRCNN] INFO : [#0005] block_1a_bn_1/gamma:0 => (64,)
[MaskRCNN] INFO : [#0006] block_1a_bn_1/beta:0 => (64,)
[MaskRCNN] INFO : [#0007] block_1a_conv_2/kernel:0 => (3, 3, 64, 64)
[MaskRCNN] INFO : [#0008] block_1a_bn_2/gamma:0 => (64,)
[MaskRCNN] INFO : [#0009] block_1a_bn_2/beta:0 => (64,)
[MaskRCNN] INFO : [#0010] block_1a_conv_3/kernel:0 => (1, 1, 64, 256)
[MaskRCNN] INFO : [#0011] block_1a_bn_3/gamma:0 => (256,)
[MaskRCNN] INFO : [#0012] block_1a_bn_3/beta:0 => (256,)
[MaskRCNN] INFO : [#0110] block_3d_bn_3/gamma:0 => (1024,)
[MaskRCNN] INFO : [#0111] block_3d_bn_3/beta:0 => (1024,)
[MaskRCNN] INFO : [#0112] block_3e_conv_1/kernel:0 => (1, 1, 1024, [MaskRCNN] INFO : [#0144] block_4b_bn_1/beta:0 => (512,)
… … … … ...
[MaskRCNN] INFO : [#0174] fpn/post_hoc_d5/kernel:0 => (3, 3, 256, 256)
[MaskRCNN] INFO : [#0175] fpn/post_hoc_d5/bias:0 => (256,)
[MaskRCNN] INFO : [#0176] rpn_head/rpn/kernel:0 => (3, 3, 256, 256)
[MaskRCNN] INFO : [#0177] rpn_head/rpn/bias:0 => (256,)
[MaskRCNN] INFO : [#0178] rpn_head/rpn-class/kernel:0 => (1, 1, 256, 3)
[MaskRCNN] INFO : [#0179] rpn_head/rpn-class/bias:0 => (3,)
[MaskRCNN] INFO : [#0180] rpn_head/rpn-box/kernel:0 => (1, 1, 256, 12)
[MaskRCNN] INFO : [#0181] rpn_head/rpn-box/bias:0 => (12,)
[MaskRCNN] INFO : [#0182] box_head/fc6/kernel:0 => (12544, 1024)
[MaskRCNN] INFO : [#0183] box_head/fc6/bias:0 => (1024,)
[MaskRCNN] INFO : [#0184] box_head/fc7/kernel:0 => (1024, 1024)
[MaskRCNN] INFO : [#0185] box_head/fc7/bias:0 => (1024,)
[MaskRCNN] INFO : [#0186] box_head/class-predict/kernel:0 => (1024, 91)
[MaskRCNN] INFO : [#0187] box_head/class-predict/bias:0 => (91,)
[MaskRCNN] INFO : [#0188] box_head/box-predict/kernel:0 => (1024, 364)
[MaskRCNN] INFO : [#0189] box_head/box-predict/bias:0 => (364,)
[MaskRCNN] INFO : [#0190] mask_head/mask-conv-l0/kernel:0 => (3, 3, 256, 256)
[MaskRCNN] INFO : [#0191] mask_head/mask-conv-l0/bias:0 => (256,)
[MaskRCNN] INFO : [#0192] mask_head/mask-conv-l1/kernel:0 => (3, 3, 256, 256)
[MaskRCNN] INFO : [#0193] mask_head/mask-conv-l1/bias:0 => (256,)
[MaskRCNN] INFO : [#0194] mask_head/mask-conv-l2/kernel:0 => (3, 3, 256, 256)
[MaskRCNN] INFO : [#0195] mask_head/mask-conv-l2/bias:0 => (256,)
[MaskRCNN] INFO : [#0196] mask_head/mask-conv-l3/kernel:0 => (3, 3, 256, 256)
[MaskRCNN] INFO : [#0197] mask_head/mask-conv-l3/bias:0 => (256,)
[MaskRCNN] INFO : [#0198] mask_head/conv5-mask/kernel:0 => (2, 2, 256, 256)
[MaskRCNN] INFO : [#0199] mask_head/conv5-mask/bias:0 => (256,)
[MaskRCNN] INFO : [#0200] mask_head/mask_fcn_logits/kernel:0 => (1, 1, 256, 91)
[MaskRCNN] INFO : [#0201] mask_head/mask_fcn_logits/bias:0 => (91,)
MaskRCNN Config
The maskrcnn configuration (maskrcnn_config) defines the model structure. This model
is used for training, evaluation and inference. Detailed description is summarized in the
table below. Currently, MaskRCNN only supports ResNet10/18/34/50/101 as its backbone.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
nlayers |
Number of layers in ResNet arch |
message |
50 |
arch |
The backbone feature extractor name |
string |
resnet |
freeze_bn |
Whether to freeze all BatchNorm layers in the backbone |
boolean |
False |
freeze_blocks |
List of conv blocks in the backbone to freeze |
string ResNet: For the ResNet series, the block IDs valid for freezing is any subset of [0, 1, 2, 3] (inclusive) |
|
gt_mask_size |
Groundtruth mask size |
Unsigned int |
112 |
rpn_positive_overlap |
Lower bound threshold to assign positive labels for anchors |
float |
0.7 |
rpn_positive_overlap |
Upper bound threshold to assign negative labels for anchors |
float |
0.3 |
rpn_batch_size_per_im |
The number of sampled anchors per image in RPN |
Unsigned int |
256 |
rpn_fg_fraction |
Desired fraction of positive anchors in a batch |
Unsigned int |
0.5 |
rpn_min_size |
Minimum proposal height and width |
0 |
|
batch_size_per_im |
RoI minibatch size per image |
Unsigned int |
512 |
fg_fraction |
The target fraction of RoI minibatch that is labeled as foreground |
float |
0.25 |
fast_rcnn_mlp_head_dim |
fast rcnn classification head dimension |
Unsigned int |
1024 |
bbox_reg_weights |
Bounding box regularization weights |
string |
“(10, 10, 5, 5)” |
include_mask |
Whether to include mask head |
boolean |
True (currently only True is supported) |
mrcnn_resolution |
Mask head resolution |
Unsigned int |
28 |
train_rpn_pre_nms_topn |
Number of top scoring RPN proposals to keep before applying NMS (per FPN level) |
Unsigned int |
2000 |
train_rpn_post_nms_topn |
Number of top scoring RPN proposals to keep after applying NMS (total number produced) |
Unsigned int |
1000 |
train_rpn_nms_threshold |
NMS IOU threshold in RPN during training |
float |
0.7 |
test_detections_per_image |
Number of bounding box candidates after NMS |
Unsigned int |
100 |
test_nms |
NMS IOU threshold during test |
float |
0.5 |
test_rpn_pre_nms_topn |
Number of top scoring RPN proposals to keep before applying NMS (per FPN level) during test |
Unsigned int |
1000 |
test_rpn_post_nms_topn |
Number of top scoring RPN proposals to keep after applying NMS (total number produced) during test |
Unsigned int |
1000 |
test_rpn_nms_threshold |
NMS IOU threshold in RPN during test |
float |
0.7 |
min_level |
Minimum level of the output feature pyramid |
Unsigned int |
2 |
max_level |
Maximum level of the output feature pyramid |
Unsigned int |
6 |
num_scales |
Number of anchor octave scales on each pyramid level (e.g. if it’s set to 3, the anchor scales are [2^0, 2^(1/3), 2^(2/3)]) |
Unsigned int |
1 |
aspect_ratios |
List of tuples representing the aspect ratios of anchors on each pyramid level |
string |
“[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]” |
anchor_scale |
Scale of base anchor size to the feature pyramid stride |
Unsigned int |
8 |
rpn_box_loss_weight |
Weight for adjusting RPN box loss in the total loss |
float |
1.0 |
fast_rcnn_box_loss_weight |
Weight for adjusting FastRCNN box regression loss in the total loss |
float |
1.0 |
mrcnn_weight_loss_mask |
Weight for adjusting mask loss in the total loss |
float |
1.0 |
The min_level, max_level, num_scales, aspect_ratios
and anchor_scale are used to determine MaskRCNN’s anchor generation.
anchor_scale is the base anchor’s scale. And min_level and
max_level sets the range of the scales on different feature maps. For example,
the actual anchor scale for the feature map at min_level will be anchor_scale *
2^min_level and the actual anchor scale for the feature map at max_level will be
anchor_scale * 2^max_level. And it will generate anchors of different
aspect_ratios based on the actual anchor scale.
Data Config
The data configuration (data_config) specifies the input data source and format. This is
used for training, evaluation and inference. Detailed description is summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
image_size |
Image dimension as a tuple within quote marks. “(height, width)” indicates the dimension of the resized and padded input |
string |
“(832, 1344)” |
augment_input_data |
Whether to augment data |
boolean |
True |
eval_samples |
Number of samples for evaluation |
Unsigned int |
|
training_file_pattern |
TFRecord path for training |
string |
|
validation_file_pattern |
TFRecord path for validation |
string |
|
val_json_file |
The annotation file path for validation |
string |
|
num_classes |
Number of classes |
Unsigned int |
|
skip_crowd_druing_training |
Whether to skip crowd during training |
boolean |
True |