Supported Model Architectures
Transfer Learning Toolkit supports image classification, six object detection architectures, including: YOLOV3, FasterRCNN, SSD, DSSD, RetinaNet, and DetectNet_v2 and 1 instance segmentation architecture, namely MaskRCNN. In addition, there are 13 classification backbones supported by TLT. For a complete list of all the permutations that are supported by TLT, please see the matrix below:
ImageClassification |
Object Detection |
Instance Segmentation |
||||||
Backbone |
DetectNet_V2 |
FasterRCNN |
SSD |
YOLOV3 |
RetinaNet |
DSSD |
MaskRCNN |
|
ResNet10/18/34/50/101 |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
VGG 16/19 |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
GoogLeNet |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
MobileNet V1/V2 |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
SqueezeNet |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
DarkNet 19/53 |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Classification
Input size: 3 * H * W (W, H >= 16)
Input format: JPG, JPEG, PNG
Classification input images do not need to be manually resized. The input dataloader resizes images as needed.
Object Detection
DetectNet_v2
Input size: C * W * H (where C = 1 or 3, W > =480, H >=272 and W, H are multiples of 16)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
The tlt-train tool does not support training on images of multiple resolutions, or resizing images during training. All of the images must be resized offline to the final training size and the corresponding bounding boxes must be scaled accordingly.
FasterRCNN
Input size: C * W * H (where C = 1 or 3; W > =160; H >=160)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
The tlt-train tool does not support training on images of multiple resolutions, or resizing images during training. All of the images must be resized offline to the final training size and the corresponding bounding boxes must be scaled accordingly.
SSD
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128, W, H are multiples of 32)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
The tlt-train tool does not support training on images of multiple resolutions, or resizing images during training. All of the images must be resized offline to the final training size and the corresponding bounding boxes must be scaled accordingly.
DSSD
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128, W, H are multiples of 32)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
The tlt-train tool does not support training on images of multiple resolutions, or resizing images during training. All of the images must be resized offline to the final training size and the corresponding bounding boxes must be scaled accordingly.
YOLOv3
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128, W, H are multiples of 32)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
The tlt-train tool does not support training on images of multiple resolutions, or resizing images during training. All of the images must be resized offline to the final training size and the corresponding bounding boxes must be scaled accordingly.
RetinaNet
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128, W, H are multiples of 32)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
The tlt-train tool does not support training on images of multiple resolutions, or resizing images during training. All of the images must be resized offline to the final training size and the corresponding bounding boxes must be scaled accordingly.
Instance Segmentation
MaskRCNN
Input size: C * W * H (where C = 3, W > =128, H >=128 and W, H are multiples of 32)
Image format: JPG
Label format: COCO detection
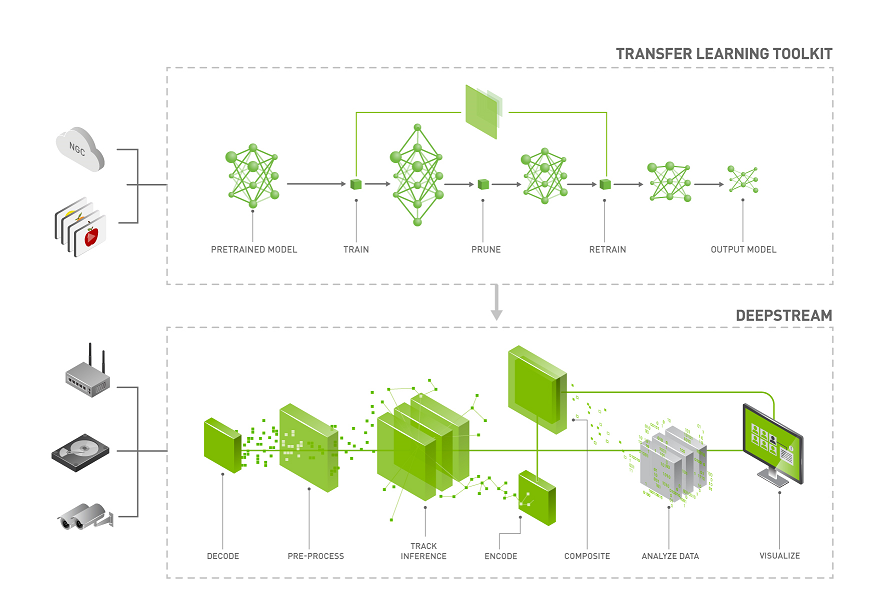
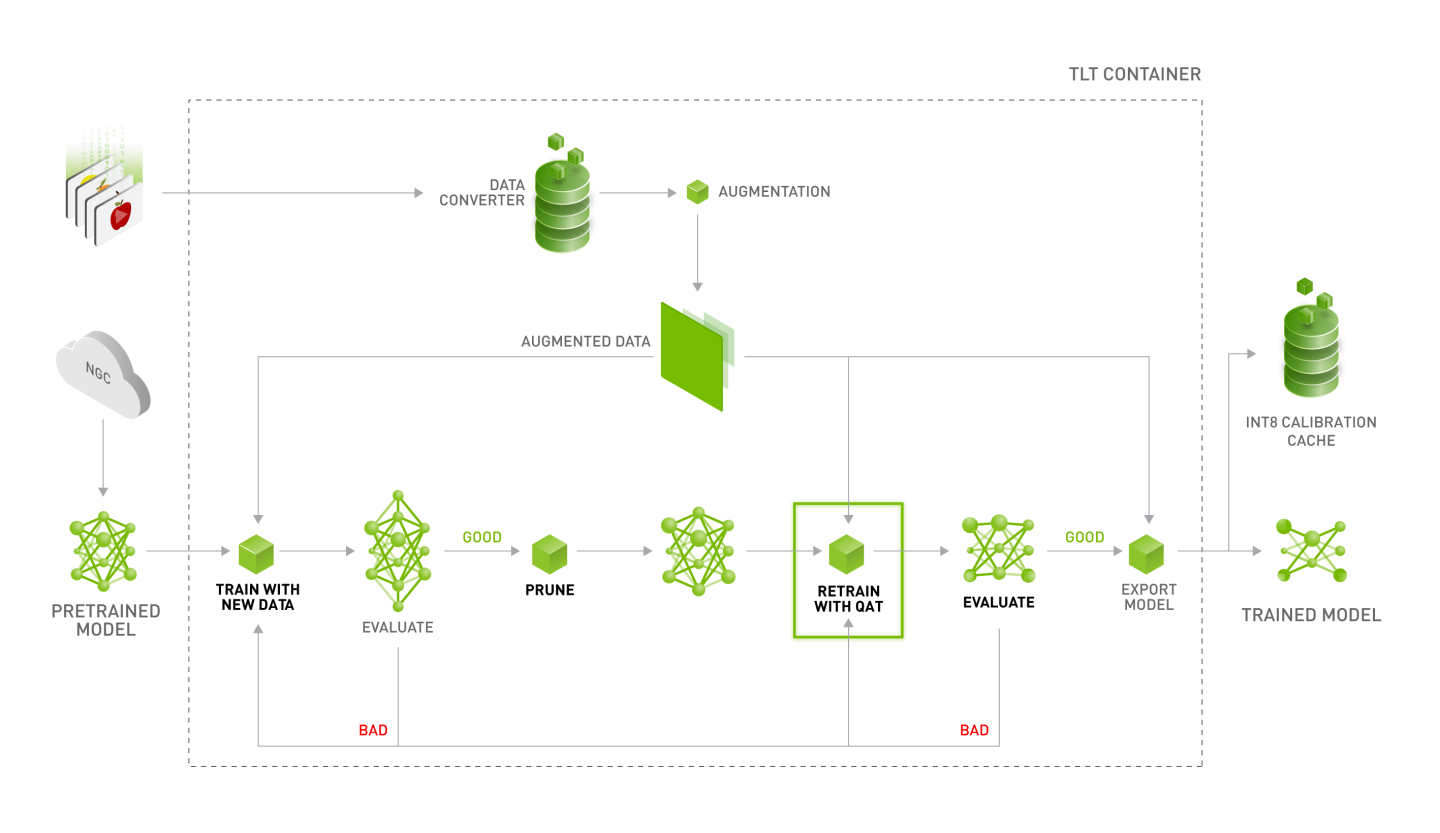
Training
The TLT container contains Jupyter notebooks and the necessary spec files to train any network combination. The pre-trained weight for each backbone is provided on NGC. The pre-trained model is trained on Open image dataset. The pre-trained weights provide a great starting point for applying transfer learning on your own dataset.
- To get started, first choose the type of model that you want to train, then go to the appropriate
model card on NGC and then choose one of the supported backbones.
Model to train |
NGC model card |
Supported Backbone |
YOLOv3 |
resnet10, resnet18, resnet34, resnet50, resnet101, vgg16, vgg19, googlenet, mobilenet_v1, mobilenet_v2, squeezenet, darknet19, darknet53 |
|
SSD |
||
FasterRCNN |
||
RetinaNet |
||
DSSD |
||
DetectNet_v2 |
resnet10, resnet18, resnet34, resnet50, resnet101, vgg16, vgg19, googlenet, mobilenet_v1, mobilenet_v2, squeezenet, darknet19, darknet53 |
|
MaskRCNN |
resnet10, resnet18, resnet34, resnet50, resnet101 |
|
Image Classification |
resnet10, resnet18, resnet34, resnet50, resnet101, vgg16, vgg19, googlenet, mobilenet_v1, mobilenet_v2, squeezenet, darknet19, darknet53 |
Once you pick the appropriate pre-trained model, follow the TLT workflow to use your dataset and pre-trained model to export a tuned model that is adapted to your use case. The TLT Workflow sections walk you through all the steps in training.
Deployment
You can deploy your trained model on any edge device using DeepStream and TensorRT. See Deploying to DeepStream for deployment instructions.