Deployment#
Q: Where can I find minimal instructions for installing and configuring NVIDIA virtual GPU software?
This information is in our vGPU Quick Start Guide.
Q: What is vGPU Scheduling, and what Scheduler policies are supported in NVIDIA virtual GPU software?
NVIDIA offers three GPU scheduling options tailored to meet various Quality of Service (QoS) requirements for customers:
Best Effort Scheduler: Best effort is the default scheduler for all supported GPU architectures, suitable for all environments with fluctuating workloads. The key principles of this scheduler are as follows:
Time-sliced Round Robin Approach: GPU resources are allocated to VMs in a time-sliced manner. If a VM has no task or has used up its time slice, the scheduler will move to the next VM in the queue.
Non-Guaranteed Shares: This scheduler does not guarantee a fixed or equal share of GPU cycles per VM. Instead, the current demand determines the allocation, which can lead to uneven distribution of GPU resources.
Optimized Utilization: During idle periods, the scheduler maximizes resource utilization to enhance user density and Quality of Service (QoS).
Equal Share Scheduler: This mode divides GPU resources equally among all active vGPUs, ensuring fair access to GPU cycles. GPU processing cycles are allocated, and each vGPU receives an equal share of GPU resources. Specifically, each vGPU gets 1/N of the available GPU cycles, where N is the number of vGPUs running on the GPU.
Deterministic Allocation: Each vGPU is guaranteed a share of GPU cycles, regardless of demand, as long as the number of vGPUs does not change. If the number of vGPUs changes, the allocation will adjust accordingly to ensure a fair distribution of resources across all vGPUs.
Idle Periods: If a VM has no tasks during its allocated timeslice, its GPU resources will remain idle rather than being reallocated to other VMs.
Dynamic Adjustment: As vGPUs are added or removed, the scheduler dynamically reallocates resources to maintain equal distribution. This means a vGPU’s performance can improve when other vGPUs stop or degrade when more vGPUs are added to the same GPU.
Fairness and Consistency: Equal Share ensures fairness and consistency across workloads, making it ideal for environments prioritizing balanced resource allocation.
Fixed Share Scheduler: This mode allocates a dedicated, consistent portion of GPU resources to each VM, ensuring predictable availability and stable performance. Administrators can select a vGPU type, and the driver software determines the fixed allocation based on that choice. For example, a L4 GPU with four L4-6Q vGPUs allocates 25% of GPU cycles to each vGPU. As vGPUs are started or stopped, the share of the GPU’s processing cycles allocated to each vGPU remains constant, ensuring that the performance of a vGPU remains unchanged. Fixed share is particularly useful in environments where performance consistency is critical, such as high-priority applications. It also simplifies Proof of Concept (POC) testing by enabling reliable comparisons between physical and virtual workstations using benchmarks like SPECviewperf.
Q: Does the fixed share scheduler support heterogeneous vGPU configurations?
Yes. Starting with vGPU 20.0, the fixed share scheduler is supported for heterogeneous vGPU configurations. In earlier releases, only the best-effort and equal-share schedulers were supported for heterogeneous vGPU configurations.
Q: From where do I download the NVIDIA virtual GPU software?
NVIDIA virtual GPU software is available to customers from the NVIDIA Software Licensing Portal, which you can access by logging in to the NVIDIA Application Hub. If you have not already purchased NVIDIA virtual GPU software and want to try it, you can obtain a limited trial license for evaluation. Note that you will need a supported NVIDIA GPU to use the license.
Q: What are the differences between NVIDIA vGPU and GPU passthrough solutions?
NVIDIA vGPU allows multiple virtual machines (VMs) to share a single physical GPU simultaneously. This makes it cost-effective and scalable, as GPU resources are divided among workloads. It also provides excellent graphics and compute performance while using standard NVIDIA drivers. Additionally, vGPU mode supports live migration and suspend/resume, enabling greater flexibility in VM management. In GPU passthrough, an entire GPU is assigned to one VM only. The VM has exclusive access to the GPU, which gives maximum performance but does not support live migration or suspend/resume. Since the GPU cannot be shared with other VMs, passthrough is less scalable and more suitable for workloads needing dedicated GPU power.
Q: How can I check which component is driving the display inside a vGPU VM?
Users should run DXDIAG inside their user sessions. To do so, type “DXDIAG” into the search field in Windows and check the Display tab. By default, the display should be driven by NVIDIA.
Q: What is the difference between vGPU and MIG?
The key difference is how GPU resources are partitioned.
MIG (Multi-Instance GPU) uses spatial partitioning, dividing a GPU into independent instances, each with dedicated compute cores, memory, and resources. These instances operate simultaneously and independently, ensuring predictable performance without resource contention. While an entire MIG-enabled GPU can be passed through to a single VM, individual MIG instances cannot be assigned to multiple VMs without vGPU. To achieve multi-tenancy across VMs with MIG, vGPU is required, as it enables the hypervisor to manage and allocate separate MIG-backed vGPUs to different VMs. Once assigned, each MIG instance functions as a separate GPU, providing strict resource isolation and predictable performance for workloads.
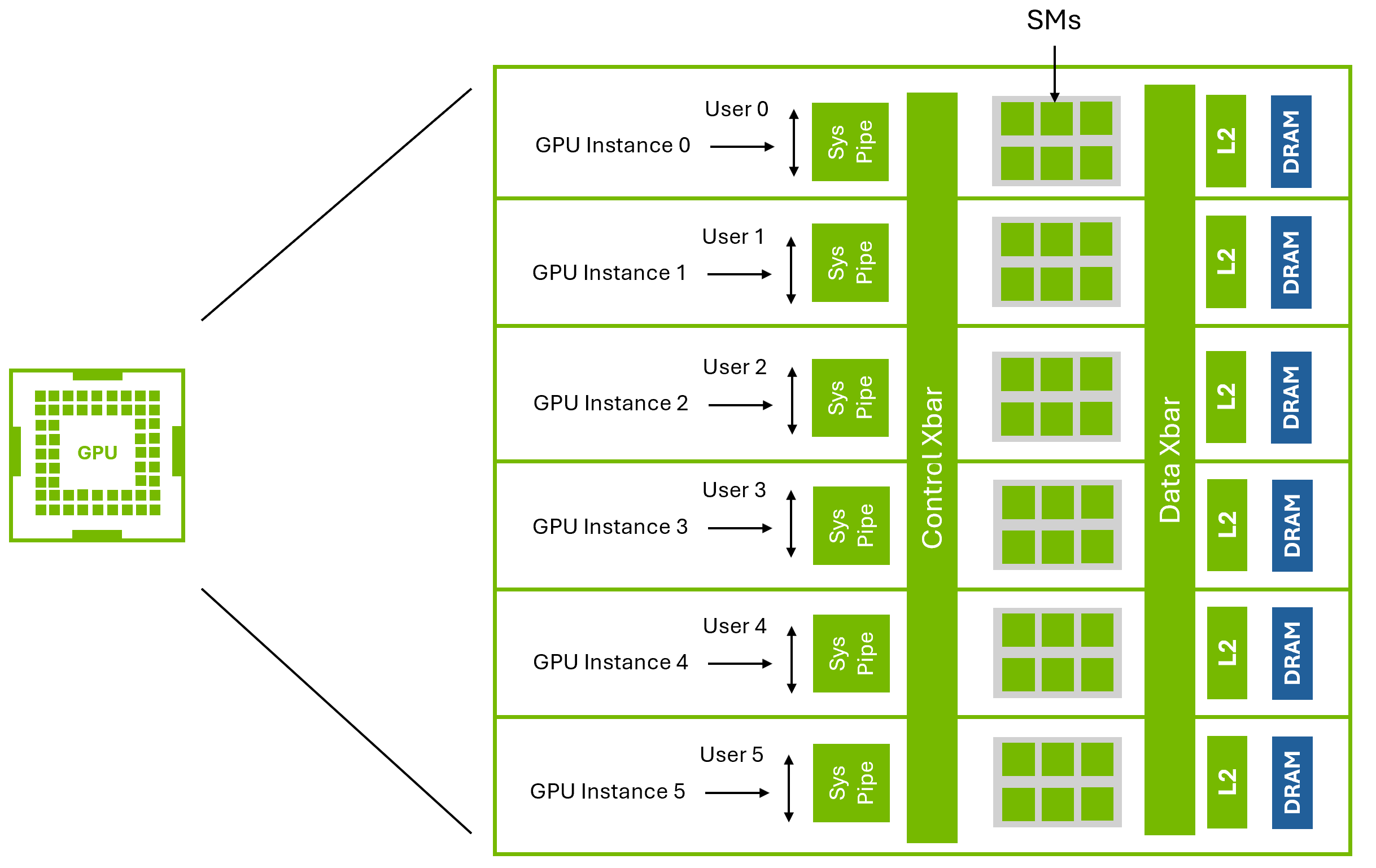
Figure 1 Multi-Instance GPU (MIG)#
The figure above illustrates NVIDIA’s Multi-Instance GPU (MIG) technology, which enables hardware partitioning by dividing a single GPU into multiple isolated instances, each with dedicated compute cores and memory. This ensures strict resource isolation and predictable performance. To enable multi-tenancy with MIG, vGPU is required. For more information on using vGPU with MIG, refer to the technical brief.
vGPU (Virtual GPU) uses temporal partitioning, where multiple virtual machines share GPU resources by alternating access through time-slicing. The GPU scheduler assigns time slices to each VM, balancing workload demands. This enables greater flexibility and higher utilization but can result in varying performance based on workload demands. To achieve multi-tenancy, vGPU is required, as it allows multiple VMs to share a single physical GPU. Without vGPU, a GPU can only be assigned to one VM at a time, limiting scalability and resource efficiency.
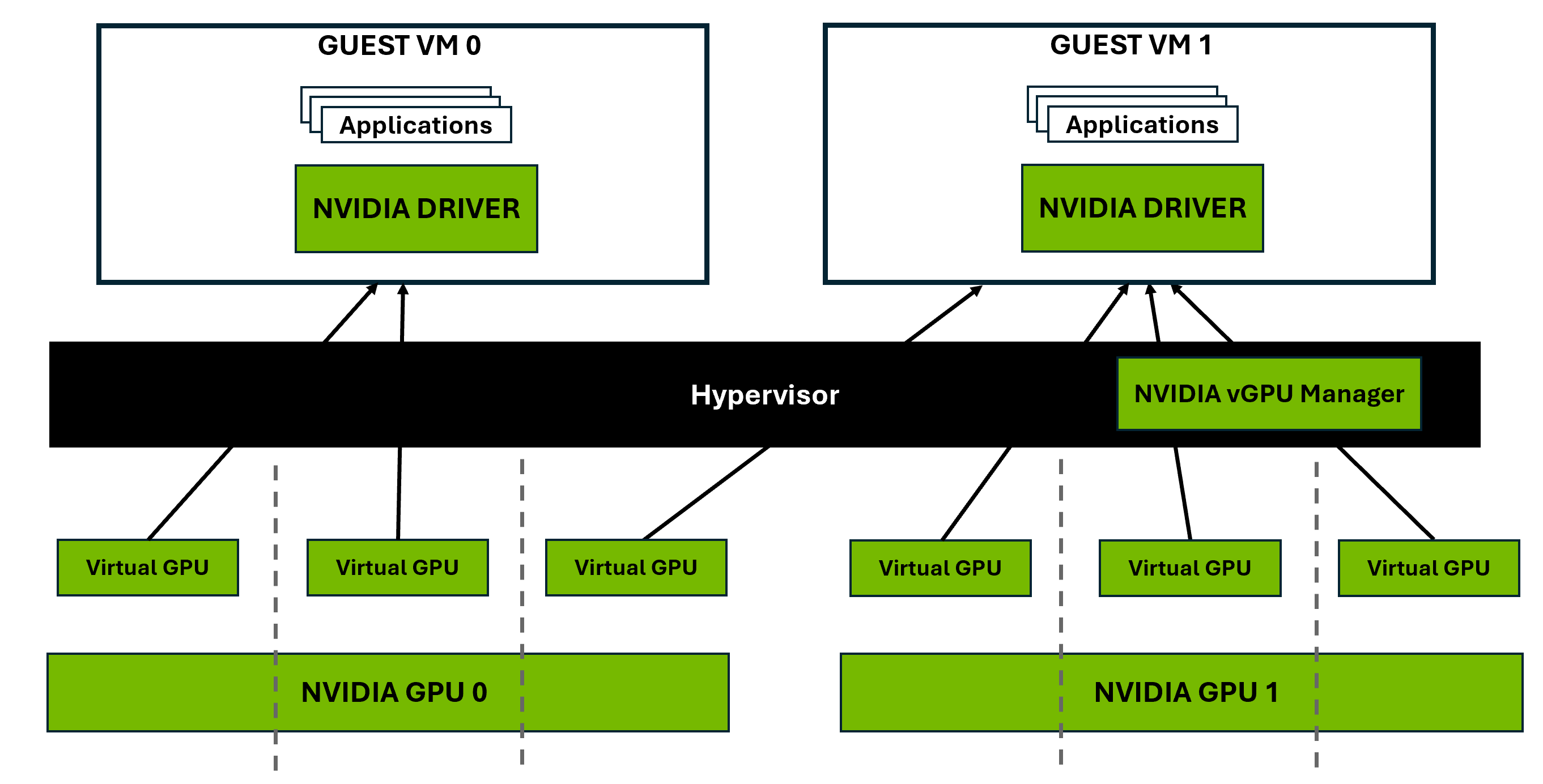
Figure 2 Virtual GPU (vGPU)#
The figure above illustrates NVIDIA vGPU technology, where a single physical GPU is virtualized and shared among multiple virtual VMs. Under the control of the NVIDIA Virtual GPU Manager running under the hypervisor, NVIDIA physical GPUs are capable of supporting multiple virtual GPU devices (vGPUs) that can be assigned directly to guest VMs, each running their own NVIDIA driver, enabling hardware-accelerated graphics and compute workloads in a virtualized environment.
Q: What is MIG-backed vGPU?
NVIDIA vGPU software supports two MIG-backed vGPU models:
1:1 MIG-Backed vGPU assigns exactly one vGPU to one MIG instance, providing full hardware isolation between VMs.
MIG-backed time-sliced vGPU allows multiple vGPUs to be created from individual MIG slices and assigned to virtual machines. This model combines MIG’s hardware-level spatial partitioning with the temporal partitioning capabilities of vGPU, offering flexibility in how GPU resources are shared across workloads.
Universal MIG-backed vGPU is supported on the NVIDIA RTX PRO 6000 Blackwell Server Edition and NVIDIA RTX PRO 4500 Blackwell Server Edition GPUs. More information is available here.
Note
Starting with vGPU 20.0, VMware Cloud Foundation (VCF) 9.1 and later support MIG-backed time-sliced vGPU. In earlier versions, only 1:1 MIG-Backed vGPU was supported.
Q: Where can I find deployment information for NVIDIA vGPU features and system capabilities?
Detailed deployment information for NVIDIA vGPU features and supported system capabilities is available in the Comprehensive Knowledge Base about vGPU Features across Hypervisors.