Introduction#
The NVIDIA AI Virtual Workstation (vWS) Sizing Advisor, powered by NVIDIA NeMo™, is a RAG-enabled tool designed to provide sizing recommendations for AI development running on AI Virtual Workstations. This free tool assists IT professionals in determining the optimal virtual GPU resources and VM configurations necessary for AI development projects, considering factors such as AI model, quantization, and other specific requirements.
Visit the GitHub page to download the tool and access the instructions.
Highlighted Features:
Deployment verification:
Locally run a vLLM container with a pre-configured VM to simulate the vGPU profile size. This pre-configuration estimate is calculated from the RAG or inference workload you can customize.
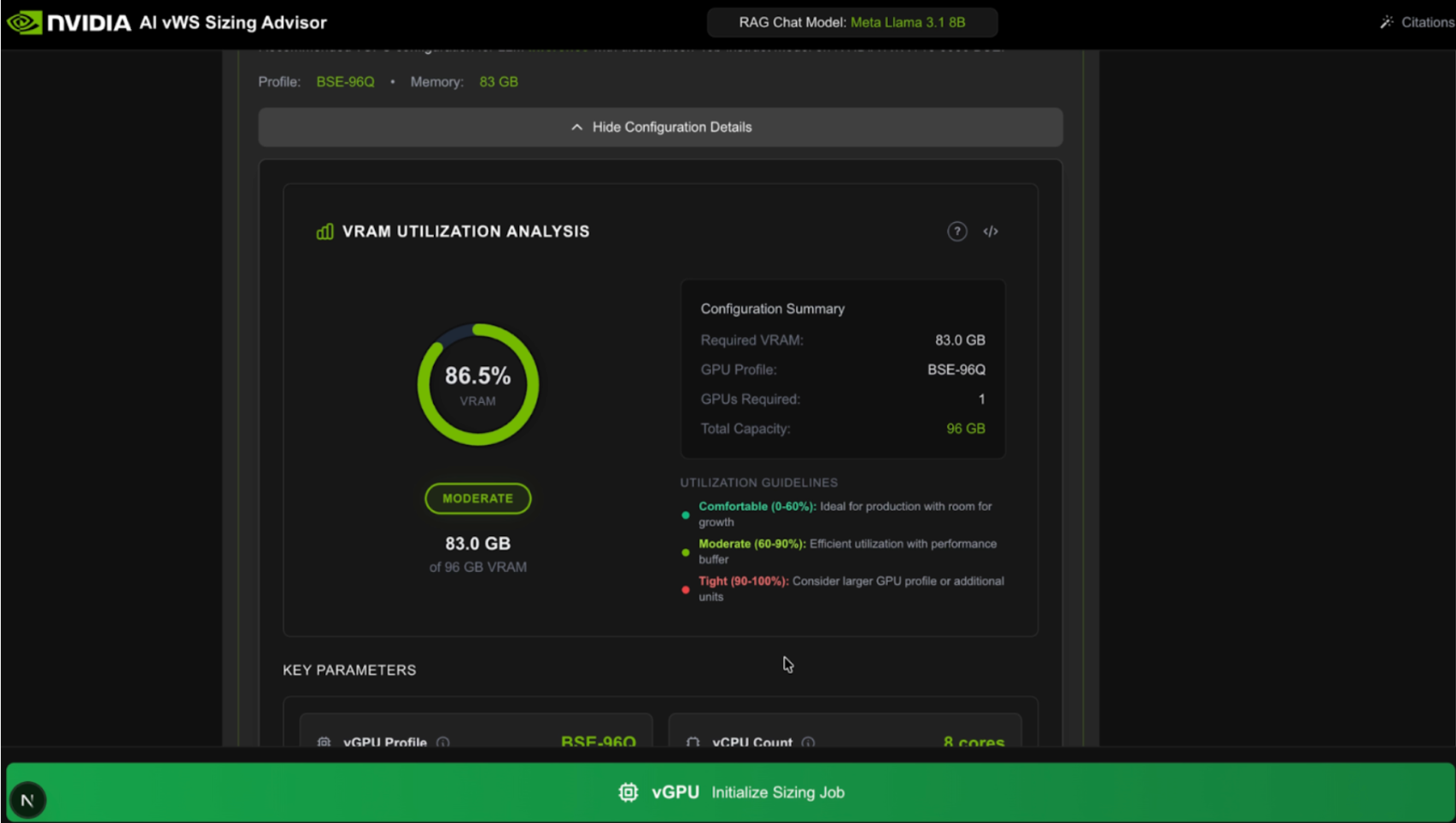
This verification process assesses whether the profile estimated by the Sizing Advisor is adequate for the custom workload. It does this by comparing the actual GPU memory utilized by the VM against the Sizing Advisor’s estimated allocation.
Shareable log:
Sizing suggestion: The tool provides a sizing suggestion by recommending the smallest appropriate vGPU profile for the estimated workload. If the workload is too large for any available vGPU profile, the tool will instead suggest using multiple GPUs via passthrough. The tool also creates a json formatted log with the information of workload, hardware, and suggested configurations.
Local deployment: A log of the deployment results/analysis is created after running the vLMM locally. This verifies if the suggested vGPU profile is sufficient for your AI workload. Additionally, a runtime log is created to go over steps in the actual vLLM deployment which can be useful for debugging deployment issues or reproducibility. These logs are exportable into a .txt file with both the deployment and runtime logs.
Citations for the RAG context:
Access citations located on a sidebar that allows you to view the vGPU documentation about profile sizes, which is used as context for the RAG-powered configuration tool.