

What is Clustering?
Clustering groups similar vectors without requiring pre-labeled examples. Instead of asking for the nearest neighbors of one query, a clustering algorithm looks across a dataset and assigns vectors to groups that share some notion of similarity.
Many clustering approaches use nearest-neighbor-style operations internally. For example, K-Means assigns each vector to its nearest centroid, which turns the assignment step into a nearest-neighbor search over the current set of centroids.
Clustering is especially important for vectors because vectors do not have a natural lexical order. Text, relational, and other structured data can often be organized with lexicographic or key-based ordering. Vectors instead have geometric relationships: nearby points are similar, distant points are less similar, and useful organization depends on preserving spatial locality. Clustering provides that organization by grouping vectors that occupy nearby regions of the embedding space.
In vector search systems, clustering is often used before search rather than after it. It can summarize data, find structure, create partitions, train quantizers, and make large datasets easier to index. The right clustering method depends on whether you need compact centroids, density-based regions, a hierarchy of connected components, or graph-aware groups.
This page introduces the main clustering methods used around NVIDIA cuVS workflows: K-Means, single-linkage clustering, and spectral clustering. By the end, you should understand why K-Means is often the practical default for vector search at scale and when the other methods are a better fit.
Clustering Algorithms in NVIDIA cuVS
K-Means
K-Means learns k centroid vectors and assigns each data vector to the closest centroid. Each centroid acts like a representative for one group. The algorithm alternates between assigning vectors to centroids and updating centroids from the assigned vectors.
K-Means is often preferred for vector search at scale because it produces compact, easy-to-use partitions. A centroid table is small compared with the full dataset, assigning a vector to the nearest centroid is straightforward, and the work maps well to GPUs. This makes K-Means a natural fit for coarse partitioning in IVF indexes, vector quantization, dataset summarization, and training workflows that need predictable memory behavior.
The main limitation is shape. K-Means works best when clusters are roughly compact and centroid-like. If the natural groups are curved, chained, or defined by graph connectivity, K-Means may split one group or merge several groups that should stay separate.
See the K-Means guide for API examples and memory guidance.
Single-Linkage Clustering
Single-linkage clustering is hierarchical. It starts with each vector as its own cluster, then repeatedly merges the two clusters connected by the shortest distance between any pair of points. The result is a tree of merges called a dendrogram.
This makes single-linkage useful when the hierarchy itself matters or when clusters are connected by thin paths. It can capture chain-like structures that centroid methods may miss. In graph terms, single-linkage is closely related to building a minimum spanning tree and cutting it into connected components.
The same behavior can also be a weakness. Because a single close pair can merge two clusters, single-linkage can chain through sparse bridges and combine groups that should remain separate. It is usually less natural than K-Means for balanced vector-search partitions, especially when the goal is fast assignment and predictable partition sizes.
See the Single-linkage guide for API examples and tuning notes.
Spectral Clustering
Spectral clustering builds a graph over the data, computes an embedding from that graph, and then clusters the embedding, often with K-Means. It uses connectivity rather than only direct distance to centroids.
This is useful when the data has manifold-like structure: points in the same group may be connected through local neighborhoods even if the group is not compact in the original space. Spectral clustering can separate groups that K-Means would blend together.
The tradeoff is cost. Spectral clustering needs graph construction and eigenvector computation before the final clustering step. That extra work can be worthwhile for exploratory analysis or graph-shaped data, but it is usually heavier than K-Means for large vector-search indexing pipelines.
See the Spectral Clustering guide for API examples and configuration details.
Why K-Means is common in vector search
Large vector search systems usually need partitions that are cheap to train, cheap to store, cheap to assign, and easy to probe at query time. K-Means is a good match for that shape of problem.
In an IVF-style index, K-Means centroids define coarse partitions. During search, a query is compared with the centroids first, then only the most relevant partitions are searched. This turns one large search problem into a smaller search over selected partitions. It also makes quantization easier because each vector can be represented by a coarse centroid assignment plus optional residual information.
K-Means is not always the best clustering algorithm in a statistical sense. It is often the best engineering compromise for vector search at scale because it gives a simple partitioning structure that supports fast indexing, fast query routing, GPU parallelism, and predictable memory use.
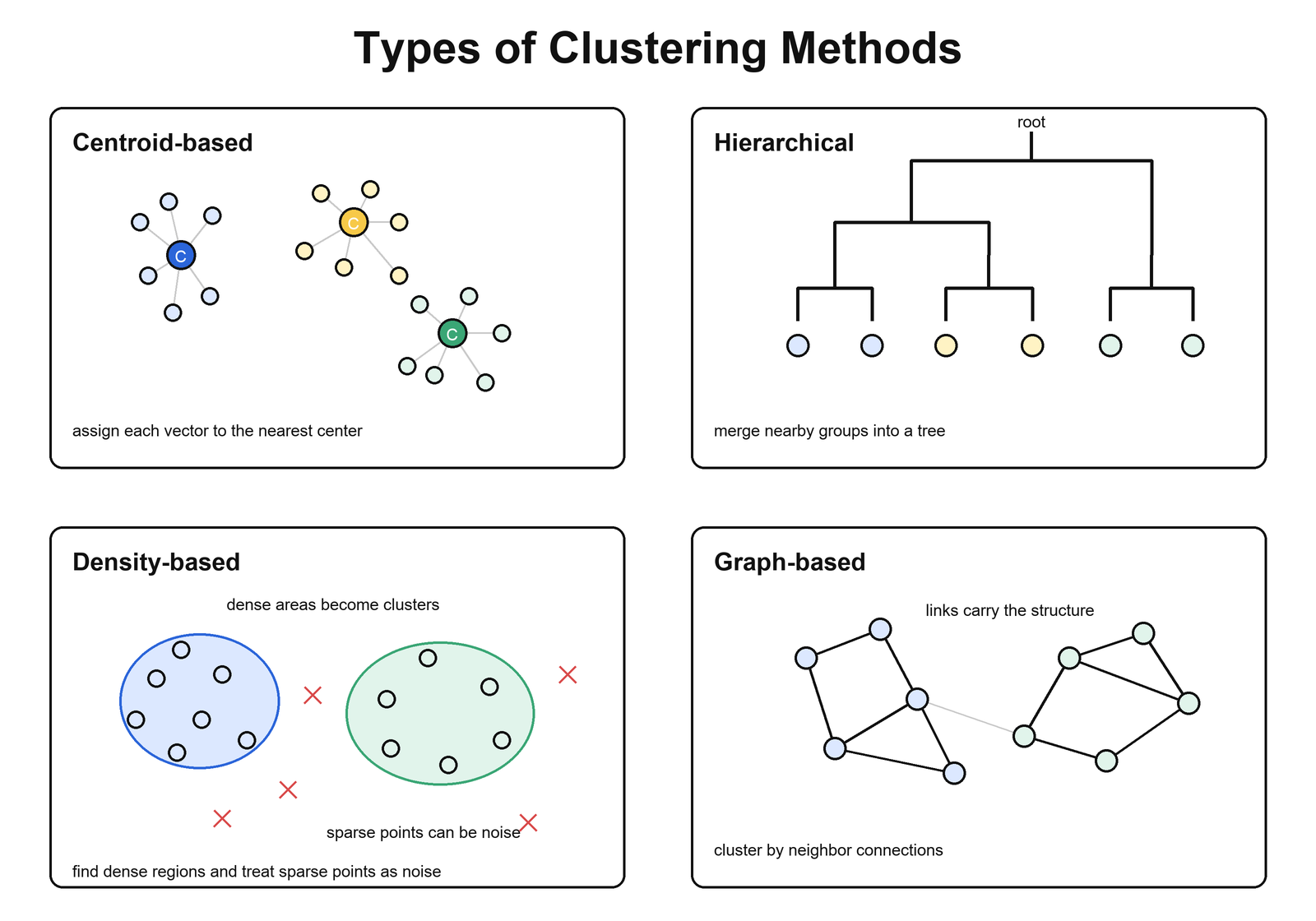
How the methods differ
K-Means is centroid-based. It asks, “Which representative center is closest?” This makes it simple, scalable, and useful for partitioning.
Single-linkage is hierarchy-based. It asks, “Which clusters are connected by the closest pair of points?” This makes it useful for dendrograms and connected structure, but sensitive to chaining.
Spectral clustering is graph-based. It asks, “Which points are connected through the neighborhood graph?” This makes it powerful for non-spherical clusters, but more expensive than centroid-based clustering.
Choosing a starting point
Use K-Means when you need scalable partitions, coarse quantization, representative centroids, or a simple baseline for large vector datasets.
Use single-linkage when the merge tree matters, when clusters may be connected by paths, or when you need to analyze hierarchical structure.
Use spectral clustering when local graph connectivity reveals structure that centroid distance alone does not capture.
For vector search at scale, start with K-Means unless you have a clear reason to preserve hierarchy or graph connectivity. It is usually the easiest clustering method to connect to indexing, quantization, and query routing.
Conclusion
Clustering helps turn an unstructured vector collection into groups that can be summarized, inspected, compressed, or searched more efficiently. K-Means, single-linkage, and spectral clustering all group nearby points, but they define “nearby” in different ways: centroids, closest links, and graph connectivity.
For production vector search, K-Means is often the practical starting point because it creates simple partitions that scale well. Single-linkage and spectral clustering are valuable when the structure of the data is more important than creating fast, balanced search partitions.