cudnn_adv Library#
Data Type References#
These are the data type references in the cudnn_adv library.
Pointer To Opaque Struct Types#
These are the pointers to the opaque struct types in the cudnn_adv library.
cudnnAttnDescriptor_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnAttnDescriptor_t is a pointer to an opaque structure holding parameters of the multihead attention layer, such as:
weight and bias tensor shapes (vector lengths before and after linear projections)
parameters that can be set in advance and do not change when invoking functions to evaluate forward responses and gradients (number of attention heads, softmax smoothing and sharpening coefficient)
other settings that are necessary to compute temporary buffer sizes.
Use the cudnnCreateAttnDescriptor() function to create an instance of the attention descriptor object and cudnnDestroyAttnDescriptor() to delete the previously created descriptor. Use the cudnnSetAttnDescriptor() function to configure the descriptor.
cudnnRNNDataDescriptor_t#
cudnnRNNDataDescriptor_t is a pointer to an opaque structure holding the description of an RNN data set. The function cudnnCreateRNNDataDescriptor() is used to create one instance, and cudnnSetRNNDataDescriptor() must be used to initialize this instance.
cudnnRNNDescriptor_t#
cudnnRNNDescriptor_t is a pointer to an opaque structure holding the description of an RNN operation. cudnnCreateRNNDescriptor() is used to create one instance.
cudnnSeqDataDescriptor_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnSeqDataDescriptor_t is a pointer to an opaque structure holding parameters of the sequence data container or buffer. The sequence data container is used to store fixed size vectors defined by the VECT dimension. Vectors are arranged in additional three dimensions: TIME, BATCH, and BEAM.
The TIME dimension is used to bundle vectors into sequences of vectors. The actual sequences can be shorter than the TIME dimension, therefore, additional information is needed about each sequence length and how unused (padding) vectors should be saved.
It is assumed that the sequence data container is fully packed. The TIME, BATCH, and BEAM dimensions can be in any order when vectors are traversed in the ascending order of addresses. Six data layouts (permutation of TIME, BATCH, and BEAM) are possible.
The cudnnSeqDataDescriptor_t object holds the following parameters:
data type used by vectors
TIME,BATCH,BEAM, andVECTdimensionsdata layout
the length of each sequence along the
TIMEdimensionan optional value to be copied to output padding vectors
Use the cudnnCreateSeqDataDescriptor() function to create one instance of the sequence data descriptor object and cudnnDestroySeqDataDescriptor() to delete a previously created descriptor. Use the cudnnSetSeqDataDescriptor() function to configure the descriptor.
This descriptor is used by multihead attention API functions.
Enumeration Types#
These are the enumeration types in the cudnn_adv library.
cudnnDirectionMode_t#
cudnnDirectionMode_t is an enumerated type used to specify the recurrence pattern.
Values
CUDNN_UNIDIRECTIONALThe network iterates recurrently from the first input to the last.
CUDNN_BIDIRECTIONALEach layer of the network iterates recurrently from the first input to the last and separately from the last input to the first. The outputs of the two are concatenated at each iteration giving the output of the layer.
cudnnForwardMode_t#
cudnnForwardMode_t is an enumerated type to specify inference or training mode in RNN API. This parameter allows the cuDNN library to tune more precisely the size of the workspace buffer that could be different in inference and training regimens.
Values
CUDNN_FWD_MODE_INFERENCESelects the inference mode.
CUDNN_FWD_MODE_TRAININGSelects the training mode.
cudnnLossNormalizationMode_t#
cudnnLossNormalizationMode_t is an enumerated type that controls the input normalization mode for a loss function. This type can be used with cudnnSetCTCLossDescriptorEx().
Values
CUDNN_LOSS_NORMALIZATION_NONEThe input probs of the cudnnCTCLoss() function is expected to be the normalized probability, and the output
gradientsis the gradient of loss with respect to the unnormalized probability.CUDNN_LOSS_NORMALIZATION_SOFTMAXThe input probs of the cudnnCTCLoss() function is expected to be the unnormalized activation from the previous layer, and the output
gradientsis the gradient with respect to the activation. Internally the probability is computed by softmax normalization.
cudnnMultiHeadAttnWeightKind_t#
cudnnMultiHeadAttnWeightKind_t is an enumerated type that specifies a group of weights or biases in the cudnnGetMultiHeadAttnWeights() function.
Values
CUDNN_MH_ATTN_Q_WEIGHTSSelects the input projection weights for
queries.CUDNN_MH_ATTN_K_WEIGHTSSelects the input projection weights for
keys.CUDNN_MH_ATTN_V_WEIGHTSSelects the input projection weights for
values.CUDNN_MH_ATTN_O_WEIGHTSSelects the output projection weights.
CUDNN_MH_ATTN_Q_BIASESSelects the input projection biases for
queries.CUDNN_MH_ATTN_K_BIASESSelects the input projection biases for
keys.CUDNN_MH_ATTN_V_BIASESSelects the input projection biases for
values.CUDNN_MH_ATTN_O_BIASESSelects the output projection biases.
cudnnRNNAlgo_t#
cudnnRNNAlgo_t is an enumerated type used to specify the algorithm.
Values
CUDNN_RNN_ALGO_STANDARDThis algorithm uses cuBLASLt to perform all matrix multiplications and dedicated kernels for cell-specific operations such as applying nonlinearities or adding biases. This is the most versatile RNN algorithm. It supports pseudo-random dropout masks between RNN layers, variable length sequences in unpacked data layouts, recurrent projection in LSTM models, and multiple choices for RNN biases: no bias, one bias, or two biases. The algorithm traverses RNN cells layer-by-layer or in a diagonal pattern through multiple layers with a certain number of time steps grouped into one “comptational chunk”. Whenever possible GEMMs are executed in parallel CUDA streams. This algorithm is expected to deliver robust performance across a wide range of RNN configurations. It is also supported on a broad range of architectures, including the oldest GPUs.
CUDNN_RNN_ALGO_PERSIST_STATICInput GEMMs in this algorithm are performed by cuBLASLt. Recurrent GEMMs, typically with fused element-wise cell operations, are handled by persistent kernels that require all thread blocks of a grid to run concurrently on GPU and communicate. All recurrent weights are stored collaboratively in stream multi-processor (SM) registers and optionally in shared memory. RNN cells are traversed layer-by-layer. GPUs with a larger number of SMs can handle longer hidden state vectors using this algorithm. This method is expected to be fast when the first dimension of the input tensor is small (meaning, a small minibatch).
CUDNN_RNN_ALGO_PERSIST_STATICis supported on devices with compute capability >= 6.0.CUDNN_RNN_ALGO_PERSIST_DYNAMICThe recurrent parts of the network are executed using a persistent kernel approach. This method is expected to perform reasonably well for small RNN models.
CUDNN_RNN_ALGO_PERSIST_DYNAMICkernels are compiled at runtime and are optimized for specific parameters of the RNN model and active GPU. The limits on the maximum size of a hidden vector when usingCUDNN_RNN_ALGO_PERSIST_DYNAMICmay be higher than the corresponding limits ofCUDNN_RNN_ALGO_PERSIST_STATIC. This algorithm does not utilize NVIDIA Tensor Cores.CUDNN_RNN_ALGO_PERSIST_DYNAMICis supported on devices with compute capability >= 6.0.CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_HDespite its name, this algorithm does not rely on persistent GPU kernels (all thread blocks being active at the same time) but in other aspects it operates similarly to
CUDNN_RNN_ALGO_PERSIST_STATIC. Input GEMMs for all time-steps are performed by cuBLASLt and recurrent GEMMs with fused element-wise operations are handled by “regular” CUDA thread blocks. One thread block collaboratively loads all recurrent weights of one layer (square matrix) and a small number of input data vectors to compute the same number of output elements without any synchronization with other thread blocks. The algorithm is limited by available register resources so the hidden vector size cannot be very large, for example, up to 192 elements for LSTM/GRU cells and up to 384 elements for RELU/TANH cells in the forward pass. This algorithm could be surprisingly fast and it scales well with the number of available SMs for large batch sizes.
cudnnRNNBiasMode_t#
cudnnRNNBiasMode_t is an enumerated type used to specify the number of bias vectors for RNN functions. Refer to the description of the cudnnRNNMode_t enumerated type for the equations for each cell type based on the bias mode.
Values
CUDNN_RNN_NO_BIASApplies RNN cell formulas that do not use biases.
CUDNN_RNN_SINGLE_INP_BIASApplies RNN cell formulas that use one input bias vector in the input GEMM.
CUDNN_RNN_DOUBLE_BIASApplies RNN cell formulas that use two bias vectors.
CUDNN_RNN_SINGLE_REC_BIASApplies RNN cell formulas that use one recurrent bias vector in the recurrent GEMM.
cudnnRNNClipMode_t#
cudnnRNNClipMode_t is an enumerated type used to select the LSTM cell clipping mode.
Values
CUDNN_RNN_CLIP_NONEDisables LSTM cell clipping.
CUDNN_RNN_CLIP_MINMAXEnables LSTM cell clipping.
cudnnRNNDataLayout_t#
cudnnRNNDataLayout_t is an enumerated type used to select the RNN data layout. It is used in the API calls cudnnGetRNNDataDescriptor() and cudnnSetRNNDataDescriptor().
Values
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKEDData layout is padded, with outer stride from one time-step to the next.
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKEDThe sequence length is sorted and packed as in the basic RNN API.
CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKEDData layout is padded, with outer stride from one batch to the next.
cudnnRNNInputMode_t#
cudnnRNNInputMode_t is an enumerated type used to specify the behavior of the first layer.
Values
CUDNN_LINEAR_INPUTA biased matrix multiplication is performed at the input of the first recurrent layer.
CUDNN_SKIP_INPUTNo operation is performed at the input of the first recurrent layer. If
CUDNN_SKIP_INPUTis used the leading dimension of the input tensor must be equal to the hidden state size of the network.
cudnnRNNMode_t#
cudnnRNNMode_t is an enumerated type used to specify the type of network.
Values
CUDNN_RNN_RELUA single-gate recurrent neural network with a ReLU activation function.
In the forward pass, the output h t for a given iteration can be computed from the recurrent input h t-1 and the previous layer input x t, given the matrices
W,R, the bias vectors, and whereReLU(x) = max(x, 0).If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_DOUBLE_BIAS(default mode), then the following equation with biases b W and b R applies:h t = ReLU(W i x t + R i h t-1 + b Wi + b Ri)
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_SINGLE_INP_BIASorCUDNN_RNN_SINGLE_REC_BIAS, then the following equation with biasbapplies:h t = ReLU(W i x t + R i h t-1 + b i)
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_NO_BIAS, then the following equation applies:h t = ReLU(W i x t + R i h t-1)
CUDNN_RNN_TANHA single-gate recurrent neural network with a
tanhactivation function.In the forward pass, the output h t for a given iteration can be computed from the recurrent input h t-1 and the previous layer input x t, given the matrices
W,Rthe bias vectors, and wheretanhis the hyperbolic tangent function.If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_DOUBLE_BIAS(default mode), then the following equation with biases b W and b R applies:h t = tanh(W i x t + R i h t-1 + b Wi + b Ri)
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_SINGLE_INP_BIASorCUDNN_RNN_SINGLE_REC_BIAS, then the following equation with biasbapplies:h t = tanh(W i x t + R i h t-1 + b i)
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_NO_BIAS, then the following equation applies:h t = tanh(W i x t + R i h t-1)
CUDNN_LSTMA four-gate LSTM (Long Short-Term Memory) network with no peephole connections.
In the forward pass, the output h t and cell output c t for a given iteration can be computed from the recurrent input h t-1, the cell input c t-1 and the previous layer input x t, given the matrices
W,R, and the bias vectors. In addition, the following applies:σ is the sigmoid operator such that: σ(x) = 1 / (1 + e -x),
◦ represents a point-wise multiplication,
tanhis the hyperbolic tangent function, andi t, f t, o t, c’ t represent the input, forget, output and new gates respectively.
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_DOUBLE_BIAS(default mode), then the following equations with biases b W and b R apply:i t = σ(W i x t + R i h t-1 + b Wi + b Ri)
f t = σ(W f x t + R f h t-1 + b Wf + b Rf)
o t = σ(W o x t + R o h t-1 + b Wo + b Ro)
c’ t = tanh(W c x t + R c h t-1 + b Wc + b Rc)
c t = f t ◦ c t-1 + i t ◦ c’ t
h t = o t ◦ tanh(c t)
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_SINGLE_INP_BIASorCUDNN_RNN_SINGLE_REC_BIAS, then the following equations with biasbapply:i t = σ(W i x t + R i h t-1 + b i)
f t = σ(W f x t + R f h t-1 + b f)
o t = σ(W o x t + R o h t-1 + b o)
c’ t = tanh(W c x t + R c h t-1 + b c)
c t = f t ◦ c t-1 + i t ◦ c’ t
h t = o t ◦ tanh(c t)
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_NO_BIAS, then the following equations apply:i t = σ(W i x t + R i h t-1)
f t = σ(W f x t + R f h t-1)
o t = σ(W o x t + R o h t-1)
c’ t = tanh(W c x t + R c h t-1)
c t = f t ◦ c t-1 + i t ◦ c’ t
h t = o t ◦ tanh(c t)
CUDNN_GRUA three-gate network consisting of Gated Recurrent Units (GRU).
In the forward pass, the output h t for a given iteration can be computed from the recurrent input h t-1 and the previous layer input x t given matrices
W,R, and the bias vectors. In addition, the following applies:σ is the sigmoid operator such that: σ(x) = 1 / (1 + e -x),
◦ represents a point-wise multiplication,
tanhis the hyperbolic tangent function, andi t, r t, h’ t represent the input, reset, and new gates respectively.
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_DOUBLE_BIAS(default mode), then the following equations with biases b W and b R apply:i t = σ(W i x t + R i h t-1 + b Wi + b Ru)
r t = σ(W r x t + R r h t-1 + b Wr + b Rr)
h’ t = tanh(W h x t + r t ◦ (R h h t-1 + b Rh) + b Wh)
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_SINGLE_INP_BIAS, then the following equations with biasbapply:i t = σ(W i x t + R i h t-1 + b i)
r t = σ(W r x t + R r h t-1 + b r)
h’ t = tanh(W h x t + r t ◦ (R h h t-1) + b Wh)
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_SINGLE_REC_BIAS, then the following equations with biasbapply:i t = σ(W i x t + R i h t-1 + b i)
r t = σ(W r x t + R r h t-1 + b r)
h’ t = tanh(W h x t + r t ◦ (R h h t-1 + b Rh))
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
If
cudnnRNNBiasMode_t biasModeinrnnDescisCUDNN_RNN_NO_BIAS, then the following equations apply:i t = σ(W i x t + R i h t-1)
r t = σ(W r x t + R r h t-1)
h’ t = tanh(W h x t + rt ◦ (R h h t-1))
h t = (1 - i t) ◦ h’ t + i t ◦ h t-1
cudnnSeqDataAxis_t#
cudnnSeqDataAxis_t is an enumerated type that indexes active dimensions in the dimA[] argument that is passed to the cudnnSetSeqDataDescriptor() function to configure the sequence data descriptor of type cudnnSeqDataDescriptor_t.
cudnnSeqDataAxis_t constants are also used in the axis[] argument of the cudnnSetSeqDataDescriptor() call to define the layout of the sequence data buffer in memory. Refer to cudnnSetSeqDataDescriptor() for a detailed description on how to use the cudnnSeqDataAxis_t enumerated type.
The CUDNN_SEQDATA_DIM_COUNT macro defines the number of constants in the cudnnSeqDataAxis_t enumerated type. This value is currently set to 4.
Values
CUDNN_SEQDATA_TIME_DIMIdentifies the
TIME(sequence length) dimension or specifies theTIMEin the data layout.CUDNN_SEQDATA_BATCH_DIMIdentifies the
BATCHdimension or specifies theBATCHin the data layout.CUDNN_SEQDATA_BEAM_DIMIdentifies the
BEAMdimension or specifies theBEAMin the data layout.CUDNN_SEQDATA_VECT_DIMIdentifies the
VECT(vector) dimension or specifies theVECTin the data layout.
cudnnWgradMode_t#
cudnnWgradMode_t is an enumerated type that selects how buffers holding gradients of the loss function, computed with respect to trainable parameters, are updated. Currently, this type is used by the cudnnMultiHeadAttnBackwardWeights() and cudnnRNNBackwardWeights_v8() functions only.
Values
CUDNN_WGRAD_MODE_ADDA weight gradient component corresponding to a new batch of inputs is added to previously evaluated weight gradients. Before using this mode, the buffer holding weight gradients should be initialized to zero. Alternatively, the first API call outputting to an uninitialized buffer should use the
CUDNN_WGRAD_MODE_SEToption.CUDNN_WGRAD_MODE_SETA weight gradient component, corresponding to a new batch of inputs, overwrites previously stored weight gradients in the output buffer.
API Functions#
These are the API functions for the cudnn_adv library.
cudnnAdvVersionCheck()#
Cross-library version checker. Each sublibrary has a version checker that checks whether its own version matches that of its dependencies.
Returns
CUDNN_STATUS_SUCCESSThe version check passed.
CUDNN_STATUS_SUBLIBRARY_VERSION_MISMATCHThe versions are inconsistent.
cudnnBuildRNNDynamic()#
This function compiles the RNN persistent code using CUDA runtime compilation library (NVRTC) when the CUDNN_RNN_ALGO_PERSIST_DYNAMIC algo is selected. The code is tailored to the current GPU and specific hyperparameters (miniBatch). This call is expected to be expensive in terms of runtime and should be invoked infrequently. Note that the CUDNN_RNN_ALGO_PERSIST_DYNAMIC algo does not support variable length sequences within the batch.
cudnnStatus_t cudnnBuildRNNDynamic( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int32_t miniBatch);
Parameters
handleInput. Handle to a previously created cuDNN context.
rnnDescInput. A previously initialized RNN descriptor.
miniBatchInput. The exact number of sequences in a batch.
Returns
CUDNN_STATUS_SUCCESSThe code was built and linked successfully.
CUDNN_STATUS_MAPPING_ERRORA GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling
cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle whencudnnCreate()was invoked.This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If
CUDNN_STATUS_MAPPING_ERRORis returned bycudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
CUDNN_STATUS_RUNTIME_PREREQUISITE_MISSINGThe prerequisite runtime library could not be found.
CUDNN_STATUS_NOT_SUPPORTEDThe current hyper-parameters are invalid.
cudnnCreateAttnDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function creates one instance of an opaque attention descriptor object by allocating the host memory for it and initializing all descriptor fields. The function writes NULL to attnDesc when the attention descriptor object cannot be allocated.
cudnnStatus_t cudnnCreateAttnDescriptor(cudnnAttnDescriptor_t *attnDesc);
Use the cudnnSetAttnDescriptor() function to configure the attention descriptor and cudnnDestroyAttnDescriptor() to destroy it and release the allocated memory.
Parameters
attnDescOutput. Pointer where the address to the newly created attention descriptor should be written.
Returns
CUDNN_STATUS_SUCCESSThe descriptor object was created successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was encountered (
attnDesc=NULL).CUDNN_STATUS_ALLOC_FAILEDThe memory allocation failed.
cudnnCreateCTCLossDescriptor()#
This function creates a CTC loss function descriptor.
cudnnStatus_t cudnnCreateCTCLossDescriptor( cudnnCTCLossDescriptor_t* ctcLossDesc)
Parameters
ctcLossDescOutput. CTC loss descriptor to be set. For more information, refer to cudnnCTCLossDescriptor_t.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMThe CTC loss descriptor passed to the function is invalid.
CUDNN_STATUS_ALLOC_FAILEDMemory allocation for this CTC loss descriptor failed.
cudnnCreateRNNDataDescriptor()#
This function creates a RNN data descriptor object by allocating the memory needed to hold its opaque structure.
cudnnStatus_t cudnnCreateRNNDataDescriptor( cudnnRNNDataDescriptor_t *RNNDataDesc)
Parameters
RNNDataDescOutput. Pointer to where the address to the newly created RNN data descriptor should be written.
Returns
CUDNN_STATUS_SUCCESSThe RNN data descriptor object was created successfully.
CUDNN_STATUS_BAD_PARAMThe
RNNDataDescargument isNULL.CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
cudnnCreateRNNDescriptor()#
This function creates a generic RNN descriptor object by allocating the memory needed to hold its opaque structure.
cudnnStatus_t cudnnCreateRNNDescriptor( cudnnRNNDescriptor_t *rnnDesc)
Parameters
rnnDescOutput. Pointer to where the address to the newly created RNN descriptor should be written.
Returns
CUDNN_STATUS_SUCCESSThe object was created successfully.
CUDNN_STATUS_BAD_PARAMThe
rnnDescargument isNULL.CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
cudnnCreateSeqDataDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function creates one instance of an opaque sequence data descriptor object by allocating the host memory for it and initializing all descriptor fields. The function writes NULL to seqDataDesc when the sequence data descriptor object cannot be allocated.
cudnnStatus_t cudnnCreateSeqDataDescriptor(cudnnSeqDataDescriptor_t *seqDataDesc)
Use the cudnnSetSeqDataDescriptor() function to configure the sequence data descriptor and cudnnDestroySeqDataDescriptor() to destroy it and release the allocated memory.
Parameters
seqDataDescOutput. Pointer where the address to the newly created sequence data descriptor should be written.
Returns
CUDNN_STATUS_SUCCESSThe descriptor object was created successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was encountered (
seqDataDesc=NULL).CUDNN_STATUS_ALLOC_FAILEDThe memory allocation failed.
cudnnCTCLoss()#
This function returns the CTC costs and gradients, given the probabilities and labels.
cudnnStatus_t cudnnCTCLoss( cudnnHandle_t handle, const cudnnTensorDescriptor_t probsDesc, const void *probs, const int hostLabels[], const int hostLabelLengths[], const int hostInputLengths[], void *costs, const cudnnTensorDescriptor_t gradientsDesc, const void *gradients, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, void *workspace, size_t *workSpaceSizeInBytes)
This function can have an inconsistent interface depending on the cudnnLossNormalizationMode_t chosen (bound to the cudnnCTCLossDescriptor_t with cudnnSetCTCLossDescriptorEx()). For the CUDNN_LOSS_NORMALIZATION_NONE, this function has an inconsistent interface, for example, the probs input is probability normalized by softmax, but the gradients output is with respect to the unnormalized activation. However, for CUDNN_LOSS_NORMALIZATION_SOFTMAX, the function has a consistent interface; all values are normalized by softmax.
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
probsDescInput. Handle to the previously initialized probabilities tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
probsInput. Pointer to a previously initialized probabilities tensor. These input probabilities are normalized by softmax.
hostLabelsInput. Pointer to a previously initialized labels list, in CPU memory.
hostLabelLengthsInput. Pointer to a previously initialized lengths list in CPU memory, to walk the above labels list.
hostInputLengthsInput. Pointer to a previously initialized list of the lengths of the timing steps in each batch, in CPU memory.
costsOutput. Pointer to the computed costs of CTC.
gradientsDescInput. Handle to a previously initialized gradient tensor descriptor.
gradientsOutput. Pointer to the computed gradients of CTC. These computed gradient outputs are with respect to the unnormalized activation.
algoInput. Enumerant that specifies the chosen CTC loss algorithm. For more information, refer to cudnnCTCLossAlgo_t.
ctcLossDescInput. Handle to the previously initialized CTC loss descriptor. For more information, refer to cudnnCTCLossDescriptor_t.
workspaceInput. Pointer to GPU memory of a workspace needed to be able to execute the specified algorithm.
sizeInBytesInput. Amount of GPU memory needed as workspace to be able to execute the CTC loss computation with the specified
algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The dimensions of
probsDescdo not match the dimensions ofgradientsDesc.The
inputLengthsdo not agree with the first dimension ofprobsDesc.The
workSpaceSizeInBytesis not sufficient.The
labelLengthsis greater than255.
CUDNN_STATUS_NOT_SUPPORTEDA compute or data type other than
FLOATwas chosen, or an unknown algorithm type was chosen.CUDNN_STATUS_EXECUTION_FAILEDThe function failed to launch on the GPU.
cudnnCTCLoss_v8()#
This function returns the CTC costs and gradients, given the probabilities and labels. Many CTC API functions were updated in version 8 with the _v8 suffix to support CUDA graphs. Label and input data is now passed in GPU memory.
cudnnStatus_t cudnnCTCLoss_v8( cudnnHandle_t handle, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, const cudnnTensorDescriptor_t probsDesc, const void *probs, const int labels[], const int labelLengths[], const int inputLengths[], void *costs, const cudnnTensorDescriptor_t gradientsDesc, const void *gradients, size_t *workSpaceSizeInBytes, void *workspace)
This function can have an inconsistent interface depending on the cudnnLossNormalizationMode_t chosen (bound to the cudnnCTCLossDescriptor_t with cudnnSetCTCLossDescriptorEx()). For the CUDNN_LOSS_NORMALIZATION_NONE, this function has an inconsistent interface, for example, the probs input is probability normalized by softmax, but the gradients output is with respect to the unnormalized activation. However, for CUDNN_LOSS_NORMALIZATION_SOFTMAX, the function has a consistent interface; all values are normalized by softmax.
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
algoInput. Enumerant that specifies the chosen CTC loss algorithm. For more information, refer to cudnnCTCLossAlgo_t.
ctcLossDescInput. Handle to the previously initialized CTC loss descriptor. For more information, refer to cudnnCTCLossDescriptor_t.
probsDescInput. Handle to the previously initialized probabilities tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
probsInput. Pointer to a previously initialized probabilities tensor. These input probabilities are normalized by softmax.
labelsInput. Pointer to a previously initialized labels list, in GPU memory.
labelLengthsInput. Pointer to a previously initialized lengths list in GPU memory, to walk the above labels list.
inputLengthsInput. Pointer to a previously initialized list of the lengths of the timing steps in each batch, in GPU memory.
costsOutput. Pointer to the computed costs of CTC.
gradientsDescInput. Handle to a previously initialized gradient tensor descriptor.
gradientsOutput. Pointer to the computed gradients of CTC. These computed gradient outputs are with respect to the unnormalized activation.
workspaceInput. Pointer to GPU memory of a workspace needed to be able to execute the specified algorithm.
sizeInBytesInput. Amount of GPU memory needed as a workspace to be able to execute the CTC loss computation with the specified algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The dimensions of
probsDescdo not match the dimensions ofgradientsDesc.The
workSpaceSizeInBytesis not sufficient.
CUDNN_STATUS_NOT_SUPPORTEDA compute or data type other than
FLOATwas chosen, or an unknown algorithm type was chosen.CUDNN_STATUS_EXECUTION_FAILEDThe function failed to launch on the GPU.
cudnnDestroyAttnDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function destroys the attention descriptor object and releases its memory. The attnDesc argument can be NULL. Invoking cudnnDestroyAttnDescriptor() with a NULL argument is a no operation (NOP).
cudnnStatus_t cudnnDestroyAttnDescriptor(cudnnAttnDescriptor_t attnDesc);
The cudnnDestroyAttnDescriptor() function is not able to detect if the attnDesc argument holds a valid address. Undefined behavior will occur in case of passing an invalid pointer, not returned by the cudnnCreateAttnDescriptor() function, or in the double deletion scenario of a valid address.
Parameters
attnDescInput. Pointer to the attention descriptor object to be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe descriptor was destroyed successfully.
cudnnDestroyCTCLossDescriptor()#
This function destroys a CTC loss function descriptor object.
cudnnStatus_t cudnnDestroyCTCLossDescriptor( cudnnCTCLossDescriptor_t ctcLossDesc)
Parameters
ctcLossDescInput. CTC loss function descriptor to be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
cudnnDestroyRNNDataDescriptor()#
This function destroys a previously created RNN data descriptor object. Invoking cudnnDestroyRNNDataDescriptor() with the NULL argument is a no operation (NOP).
cudnnStatus_t cudnnDestroyRNNDataDescriptor( cudnnRNNDataDescriptor_t RNNDataDesc)
The cudnnDestroyRNNDataDescriptor() function is not able to detect if the RNNDataDesc argument holds a valid address. Undefined behavior will occur in cases of passing an invalid pointer, not returned by the cudnnCreateRNNDataDescriptor() function, or in the double deletion scenario of a valid address.
Parameters
RNNDataDescInput. Pointer to the RNN data descriptor object to be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe RNN data descriptor object was destroyed successfully.
cudnnDestroyRNNDescriptor()#
This function destroys a previously created RNN descriptor object. Invoking cudnnDestroyRNNDescriptor() with the NULL argument is a no operation (NOP).
cudnnStatus_t cudnnDestroyRNNDescriptor( cudnnRNNDescriptor_t rnnDesc)
The cudnnDestroyRNNDescriptor() function is not able to detect if the rnnDesc argument holds a valid address. Undefined behavior will occur in cases of passing an invalid pointer, not returned by the cudnnCreateRNNDescriptor() function, or in the double deletion scenario of a valid address.
Parameters
rnnDescInput. Pointer to the RNN descriptor object to be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe object was destroyed successfully.
cudnnDestroySeqDataDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function destroys the sequence data descriptor object and releases its memory. The seqDataDesc argument can be NULL. Invoking cudnnDestroySeqDataDescriptor() with a NULL argument is a no operation (NOP).
cudnnStatus_t cudnnDestroySeqDataDescriptor(cudnnSeqDataDescriptor_t seqDataDesc);
The cudnnDestroySeqDataDescriptor() function is not able to detect if the seqDataDesc argument holds a valid address. Undefined behavior will occur in case of passing an invalid pointer, not returned by the cudnnCreateSeqDataDescriptor() function, or in the double deletion scenario of a valid address.
Parameters
seqDataDescInput. Pointer to the sequence data descriptor object to be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe descriptor was destroyed successfully.
cudnnGetAttnDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function retrieves settings from the previously created attention descriptor. The user can assign NULL to any pointer except attnDesc when the retrieved value is not needed.
cudnnStatus_t cudnnGetAttnDescriptor( cudnnAttnDescriptor_t attnDesc, unsigned *attnMode, int *nHeads, double *smScaler, cudnnDataType_t *dataType, cudnnDataType_t *computePrec, cudnnMathType_t *mathType, cudnnDropoutDescriptor_t *attnDropoutDesc, cudnnDropoutDescriptor_t *postDropoutDesc, int *qSize, int *kSize, int *vSize, int *qProjSize, int *kProjSize, int *vProjSize, int *oProjSize, int *qoMaxSeqLength, int *kvMaxSeqLength, int *maxBatchSize, int *maxBeamSize);
Parameters
attnDescInput. Attention descriptor.
attnModeOutput. Pointer to the storage for binary attention flags.
nHeadsOutput. Pointer to the storage for the number of attention heads.
smScalerOutput. Pointer to the storage for the softmax smoothing/sharpening coefficient.
dataTypeOutput. Data type for attention weights, sequence data inputs, and outputs.
computePrecOutput. Pointer to the storage for the compute precision.
mathTypeOutput. NVIDIA Tensor Core settings.
attnDropoutDescOutput. Descriptor of the dropout operation applied to the softmax output.
postDropoutDescOutput. Descriptor of the dropout operation applied to the multihead attention output.
qSize,kSize,vSizeOutput. Q, K, and V embedding vector lengths.
qProjSize,kProjSize,vProjSizeOutput. Q, K, and V embedding vector lengths after input projections.
oProjSizeOutput. Pointer to store the output vector length after projection.
qoMaxSeqLengthOutput. Largest sequence length expected in sequence data descriptors related to Q, O, dQ, dO inputs and outputs.
kvMaxSeqLengthOutput. Largest sequence length expected in sequence data descriptors related to K, V, dK, dV inputs and outputs.
maxBatchSizeOutput. Largest batch size expected in the cudnnSeqDataDescriptor_t container.
maxBeamSizeOutput. Largest beam size expected in the cudnnSeqDataDescriptor_t container.
Returns
CUDNN_STATUS_SUCCESSRequested attention descriptor fields were retrieved successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found.
cudnnGetCTCLossDescriptor()#
This function has been deprecated in cuDNN 9.0; use cudnnGetCTCLossDescriptor_v9() instead.
This function returns the configuration of the passed CTC loss function descriptor.
cudnnStatus_t cudnnGetCTCLossDescriptor( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t* compType)
Parameters
ctcLossDescInput. CTC loss function descriptor passed, from which to retrieve the configuration.
compTypeOutput. Compute type associated with this CTC loss function descriptor.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMInput
ctcLossDescdescriptor passed is invalid.
cudnnGetCTCLossDescriptor_v8()#
This function has been deprecated in cuDNN 9.0; use cudnnGetCTCLossDescriptor_v9() instead.
This function returns the configuration of the passed CTC loss function descriptor.
cudnnStatus_t cudnnGetCTCLossDescriptor_v8( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t *compType, cudnnLossNormalizationMode_t *normMode, cudnnNanPropagation_t *gradMode, int *maxLabelLength)
Parameters
ctcLossDescInput. CTC loss function descriptor passed, from which to retrieve the configuration.
compTypeOutput. Compute type associated with this CTC loss function descriptor.
normModeOutput. Input normalization type for this CTC loss function descriptor. For more information, refer to cudnnLossNormalizationMode_t.
gradModeOutput. NaN propagation type for this CTC loss function descriptor.
maxLabelLengthOutput. The max label length for this CTC loss function descriptor.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMInput
ctcLossDescdescriptor passed is invalid.
cudnnGetCTCLossDescriptor_v9()#
This function returns the configuration of the passed CTC loss function descriptor.
cudnnStatus_t cudnnGetCTCLossDescriptor_v8( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t *compType, cudnnLossNormalizationMode_t *normMode, cudnnCTCGradMode_t *ctcGradMode, int *maxLabelLength)
Parameters
ctcLossDescInput. CTC loss function descriptor passed, from which to retrieve the configuration.
compTypeOutput. Compute type associated with this CTC loss function descriptor.
normModeOutput. Input normalization type for this CTC loss function descriptor. For more information, refer to cudnnLossNormalizationMode_t.
ctcGradModeOutput. The gradient mode for handling OOB samples for this CTC loss function descriptor. Refer to cudnnSetCTCLossDescriptor_v9() for more information.
maxLabelLengthOutput. The max label length for this CTC loss function descriptor.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMInput
ctcLossDescdescriptor passed is invalid.
cudnnGetCTCLossDescriptorEx()#
This function has been deprecated in cuDNN 9.0; use cudnnGetCTCLossDescriptor_v9() instead.
This function returns the configuration of the passed CTC loss function descriptor.
cudnnStatus_t cudnnGetCTCLossDescriptorEx( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t *compType, cudnnLossNormalizationMode_t *normMode, cudnnNanPropagation_t *gradMode)
Parameters
ctcLossDescInput. CTC loss function descriptor passed, from which to retrieve the configuration.
compTypeOutput. Compute type associated with this CTC loss function descriptor.
normModeOutput. Input normalization type for this CTC loss function descriptor. For more information, refer to cudnnLossNormalizationMode_t.
gradModeOutput. NaN propagation type for this CTC loss function descriptor.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMInput
ctcLossDescdescriptor passed is invalid.
cudnnGetCTCLossWorkspaceSize()#
This function returns the amount of GPU memory workspace the user needs to allocate to be able to call cudnnCTCLoss() with the specified algorithm. The workspace allocated will then be passed to the routine cudnnCTCLoss().
cudnnStatus_t cudnnGetCTCLossWorkspaceSize( cudnnHandle_t handle, const cudnnTensorDescriptor_t probsDesc, const cudnnTensorDescriptor_t gradientsDesc, const int *labels, const int *labelLengths, const int *inputLengths, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, size_t *sizeInBytes)
Parameters
handleInput. Handle to a previously created cuDNN context.
probsDescInput. Handle to the previously initialized probabilities tensor descriptor.
gradientsDescInput. Handle to a previously initialized gradient tensor descriptor.
labelsInput. Pointer to a previously initialized labels list.
labelLengthsInput. Pointer to a previously initialized lengths list, to walk the above labels list.
inputLengthsInput. Pointer to a previously initialized list of the lengths of the timing steps in each batch.
algoInput. Enumerant that specifies the chosen CTC loss algorithm.
ctcLossDescInput. Handle to the previously initialized CTC loss descriptor.
sizeInBytesOutput. Amount of GPU memory needed as workspace to be able to execute the CTC loss computation with the specified
algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The dimensions of
probsDescdo not match the dimensions ofgradientsDescThe
inputLengthsdo not agree with the first dimension ofprobsDescThe
workSpaceSizeInBytesis not sufficientThe
labelLengthsis greater than256
CUDNN_STATUS_NOT_SUPPORTEDA compute or data type other than
FLOATwas chosen, or an unknown algorithm type was chosen.
cudnnGetCTCLossWorkspaceSize_v8()#
This function returns the amount of GPU memory workspace the user needs to allocate to be able to call cudnnCTCLoss_v8 with the specified algorithm. The workspace allocated will then be passed to the routine cudnnCTCLoss_v8().
cudnnStatus_t cudnnGetCTCLossWorkspaceSize_v8( cudnnHandle_t handle, cudnnCTCLossAlgo_t algo, const cudnnCTCLossDescriptor_t ctcLossDesc, const cudnnTensorDescriptor_t probsDesc, const cudnnTensorDescriptor_t gradientsDesc, size_t *sizeInBytes)
Parameters
handleInput. Handle to a previously created cuDNN context.
algoInput. Enumerant that specifies the chosen CTC loss algorithm.
ctcLossDescInput. Handle to the previously initialized CTC loss descriptor.
probsDescInput. Handle to the previously initialized probabilities tensor descriptor.
gradientsDescInput. Handle to a previously initialized gradient tensor descriptor.
sizeInBytesOutput. Amount of GPU memory needed as workspace to be able to execute the CTC loss computation with the specified
algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The dimensions of
probsDescdo not match the dimensions ofgradientsDesc
CUDNN_STATUS_NOT_SUPPORTED
- A compute or data type other than FLOAT was chosen, or an unknown algorithm type was chosen.
- For the deterministic CTC loss algorithm, the maxLabelLength in ctcLossDesc is greater than or equal to 256.
- For the nondeterministic CTC loss algorithm, the maxLabelLength in ctcLossDesc is greater than or equal to 2048.
cudnnGetMultiHeadAttnBuffers()#
This function has been deprecated in cuDNN 9.0.
This function computes weight, work, and reserve space buffer sizes used by the following functions:
cudnnStatus_t cudnnGetMultiHeadAttnBuffers( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, size_t *weightSizeInBytes, size_t *workSpaceSizeInBytes, size_t *reserveSpaceSizeInBytes);
Assigning NULL to the reserveSpaceSizeInBytes argument indicates that the user does not plan to invoke multihead attention gradient functions: cudnnMultiHeadAttnBackwardData() and cudnnMultiHeadAttnBackwardWeights(). This situation occurs in the inference mode.
Note
NULLcannot be assigned toweightSizeInBytesandworkSpaceSizeInBytespointers.
The user must allocate weight, work, and reserve space buffer sizes in the GPU memory using cudaMalloc() with the reported buffer sizes. The buffers can be also carved out from a larger chunk of allocated memory but the buffer addresses must be at least 16B aligned.
The workspace buffer is used for temporary storage. Its content can be discarded or modified after all GPU kernels launched by the corresponding API complete. The reserve-space buffer is used to transfer intermediate results from cudnnMultiHeadAttnForward() to cudnnMultiHeadAttnBackwardData(), and from cudnnMultiHeadAttnBackwardData() to cudnnMultiHeadAttnBackwardWeights(). The content of the reserve-space buffer cannot be modified until all GPU kernels launched by the above three multihead attention API functions finish.
All multihead attention weight and bias tensors are stored in a single weight buffer. For speed optimizations, the cuDNN API may change tensor layouts and their relative locations in the weight buffer based on the provided attention parameters. Use the cudnnGetMultiHeadAttnWeights() function to obtain the start address and the shape of each weight or bias tensor.
Parameters
handleInput. The current cuDNN context handle.
attnDescInput. Pointer to a previously initialized attention descriptor.
weightSizeInBytesOutput. Minimum buffer size required to store all multihead attention trainable parameters.
workSpaceSizeInBytesOutput. Minimum buffer size required to hold all temporary surfaces used by the forward and gradient multihead attention API calls.
reserveSpaceSizeInBytesOutput. Minimum buffer size required to store all intermediate data exchanged between forward and backward (gradient) multihead attention functions. Set this parameter to
NULLin the inference mode indicating that gradient API calls will not be invoked.
Returns
CUDNN_STATUS_SUCCESSThe requested buffer sizes were computed successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found.
cudnnGetMultiHeadAttnWeights()#
This function has been deprecated in cuDNN 9.0.
This function obtains the shape of the weight or bias tensor. It also retrieves the start address of tensor data located in the weight buffer. Use the wKind argument to select a particular tensor. For more information, refer to cudnnMultiHeadAttnWeightKind_t for the description of the enumerant type.
cudnnStatus_t cudnnGetMultiHeadAttnWeights( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, cudnnMultiHeadAttnWeightKind_t wKind, size_t weightSizeInBytes, const void *weights, cudnnTensorDescriptor_t wDesc, void **wAddr);
Biases are used in the input and output projections when the CUDNN_ATTN_ENABLE_PROJ_BIASES flag is set in the attention descriptor. Refer to cudnnSetAttnDescriptor() for the description of flags to control projection biases.
When the corresponding weight or bias tensor does not exist, the function writes NULL to the storage location pointed by wAddr and returns zeros in the wDesc tensor descriptor. The return status of the cudnnGetMultiHeadAttnWeights() function is CUDNN_STATUS_SUCCESS in this case.
The cuDNN multiHeadAttention sample code demonstrates how to access multihead attention weights. Although the buffer with weights and biases should be allocated in the GPU memory, the user can copy it to the host memory and invoke the cudnnGetMultiHeadAttnWeights() function with the host weights address to obtain tensor pointers in the host memory. This scheme allows the user to inspect trainable parameters directly in the CPU memory.
Parameters
handleInput. The current cuDNN context handle.
attnDescInput. A previously configured attention descriptor.
wKindInput. Enumerant type to specify which weight or bias tensor should be retrieved.
weightSizeInBytesInput. Buffer size that stores all multihead attention weights and biases.
weightsInput. Pointer to the
weightbuffer in the host or device memory.wDescOutput. The descriptor specifying weight or bias tensor shape. For weights, the
wDesc.dimA[]array has three elements:[nHeads, projected size, original size]. For biases, thewDesc.dimA[]array also has three elements:[nHeads, projected size, 1]. ThewDesc.strideA[]array describes how tensor elements are arranged in memory.wAddrOutput. Pointer to a location where the start address of the requested tensor should be written. When the corresponding projection is disabled, the address written to
wAddrisNULL.
Returns
CUDNN_STATUS_SUCCESSThe weight tensor descriptor and the address of data in the device memory were successfully retrieved.
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered. For example,
wKinddid not have a valid value orweightSizeInByteswas too small.
cudnnGetRNNDataDescriptor()#
This function retrieves a previously created RNN data descriptor object.
cudnnStatus_t cudnnGetRNNDataDescriptor( cudnnRNNDataDescriptor_t RNNDataDesc, cudnnDataType_t *dataType, cudnnRNNDataLayout_t *layout, int *maxSeqLength, int *batchSize, int *vectorSize, int arrayLengthRequested, int seqLengthArray[], void *paddingFill);
Parameters
RNNDataDescInput. A previously created and initialized RNN descriptor.
dataTypeOutput. Pointer to the host memory location to store the datatype of the RNN data tensor.
layoutOutput. Pointer to the host memory location to store the memory layout of the RNN data tensor.
maxSeqLengthOutput. The maximum sequence length within this RNN data tensor, including the padding vectors.
batchSizeOutput. The number of sequences within the mini-batch.
vectorSizeOutput. The vector length (meaning, embedding size) of the input or output tensor at each time-step.
arrayLengthRequestedInput. The number of elements that the user requested for
seqLengthArray.seqLengthArrayOutput. Pointer to the host memory location to store the integer array describing the length (meaning, number of timesteps) of each sequence. This is allowed to be a
NULLpointer ifarrayLengthRequestedis0.paddingFillOutput. Pointer to the host memory location to store the user defined symbol. The symbol should be interpreted as the same data type as the RNN data tensor.
Returns
CUDNN_STATUS_SUCCESSThe parameters are fetched successfully.
CUDNN_STATUS_BAD_PARAMAny one of these have occurred:
Any of
RNNDataDesc,dataType,layout,maxSeqLength,batchSize,vectorSize, orpaddingFillisNULL.seqLengthArrayisNULLwhilearrayLengthRequestedis greater than zero.arrayLengthRequestedis less than zero.
cudnnGetRNNDescriptor_v8()#
This function retrieves RNN network parameters that were configured by cudnnSetRNNDescriptor_v8(). The user can assign NULL to any pointer except rnnDesc when the retrieved value is not needed. The function does not check the validity of retrieved parameters.
cudnnStatus_t cudnnGetRNNDescriptor_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNAlgo_t *algo, cudnnRNNMode_t *cellMode, cudnnRNNBiasMode_t *biasMode, cudnnDirectionMode_t *dirMode, cudnnRNNInputMode_t *inputMode, cudnnDataType_t *dataType, cudnnDataType_t *mathPrec, cudnnMathType_t *mathType, int32_t *inputSize, int32_t *hiddenSize, int32_t *projSize, int32_t *numLayers, cudnnDropoutDescriptor_t *dropoutDesc, uint32_t *auxFlags);
Parameters
rnnDescInput. A previously created and initialized RNN descriptor.
algoOutput. Pointer to where RNN algorithm type should be stored.
cellModeOutput. Pointer to where RNN cell type should be saved.
biasModeOutput. Pointer to where RNN bias mode cudnnRNNBiasMode_t should be saved.
dirModeOutput. Pointer to where RNN unidirectional/bidirectional mode should be saved.
inputModeOutput. Pointer to where the mode of the first RNN layer should be saved.
dataTypeOutput. Pointer to where the data type of RNN weights/biases should be stored.
mathPrecOutput. Pointer to where the math precision type should be stored.
mathTypeOutput. Pointer to where the preferred option for Tensor Cores are saved.
inputSizeOutput. Pointer to where the RNN input vector size is stored.
hiddenSizeOutput. Pointer to where the size of the hidden state should be stored (the same value is used in every RNN layer).
projSizeOutput. Pointer to where the LSTM cell output size after the recurrent projection is stored.
numLayersOutput. Pointer to where the number of RNN layers should be stored.
dropoutDescOutput. Pointer to where the handle to a previously configured dropout descriptor should be stored.
auxFlagsOutput. Pointer to miscellaneous RNN options (flags) that do not require passing additional numerical values to configure.
Returns
CUDNN_STATUS_SUCCESSRNN parameters were successfully retrieved from the RNN descriptor.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found (
rnnDescwasNULL).CUDNN_STATUS_NOT_INITIALIZEDThe cuDNN library was not initialized properly.
cudnnGetRNNTempSpaceSizes()#
This function computes the work and reserve space buffer sizes based on the RNN network geometry stored in rnnDesc, designated usage (inference or training) defined by the fMode argument, and the current RNN data dimensions (maxSeqLength, batchSize) retrieved from xDesc. When RNN data dimensions change, the cudnnGetRNNTempSpaceSizes() must be called again because RNN temporary buffer sizes are not monotonic.
cudnnStatus_t cudnnGetRNNTempSpaceSizes( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnForwardMode_t fMode, cudnnRNNDataDescriptor_t xDesc, size_t *workSpaceSize, size_t *reserveSpaceSize);
The user can assign NULL to workSpaceSize or reserveSpaceSize pointers when the corresponding value is not needed.
Parameters
handleInput. The current cuDNN context handle.
rnnDescInput. A previously initialized RNN descriptor.
fModeInput. Specifies whether temporary buffers are used in inference or training modes. The reserve-space buffer is not used during inference. Therefore, the returned size of the reserve space buffer will be zero when the
fModeargument isCUDNN_FWD_MODE_INFERENCE.xDescInput. A single RNN data descriptor that specifies current RNN data dimensions:
maxSeqLengthandbatchSize.workSpaceSizeOutput. Minimum amount of GPU memory in bytes needed as a workspace buffer. The workspace buffer is not used to pass intermediate results between APIs but as a temporary read/write buffer.
reserveSpaceSizeOutput. Minimum amount of GPU memory in bytes needed as the reserve-space buffer. The reserve space buffer is used to pass intermediate results from cudnnRNNForward() to RNN
BackwardDataandBackwardWeightsroutines that compute first order derivatives with respect to RNN inputs or trainable weight and biases.
Returns
CUDNN_STATUS_SUCCESSRNN temporary buffer sizes were computed successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was detected.
CUDNN_STATUS_NOT_SUPPORTEDAn incompatible or unsupported combination of input arguments was detected.
cudnnGetRNNWeightParams()#
This function is used to obtain the start address and shape of every RNN weight matrix and bias vector in each pseudo-layer within the recurrent neural network model.
cudnnStatus_t cudnnGetRNNWeightParams( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int32_t pseudoLayer, size_t weightSpaceSize, const void *weightSpace, int32_t linLayerID, cudnnTensorDescriptor_t mDesc, void **mAddr, cudnnTensorDescriptor_t bDesc, void **bAddr);
Parameters
handleInput. Handle to a previously created cuDNN library descriptor.
rnnDescInput. A previously initialized RNN descriptor.
pseudoLayerInput. The pseudo-layer to query. In unidirectional RNNs, a pseudo-layer is the same as a physical layer (
pseudoLayer=0is the RNN input layer,pseudoLayer=1is the first hidden layer). In bidirectional RNNs, there are twice as many pseudo-layers in comparison to physical layers:pseudoLayer=0refers to the forward direction sub-layer of the physical input layerpseudoLayer=1refers to the backward direction sub-layer of the physical input layerpseudoLayer=2is the forward direction sub-layer of the first hidden layer, and so on
weightSpaceSizeInput. Address of the weight space buffer. Starting from cuDNN version 9.1, this parameter can be
NULL. This allows you to retrieve weight/bias offsets instead of the actual pointers within the buffer. For best performance, the recommended alignment of the weight space buffer should be 256 B or the same as returned bycudaMalloc().weightSpaceInput. Pointer to the weight space buffer.
linLayerIDInput. Weight matrix or bias vector linear ID index.
If
cellModeinrnnDescwas set toCUDNN_RNN_RELUorCUDNN_RNN_TANH:Value
0references the weight matrix or bias vector used in conjunction with the input from the previous layer or input to the RNN model.Value
1references the weight matrix or bias vector used in conjunction with the hidden state from the previous time step or the initial hidden state.
If
cellModeinrnnDescwas set toCUDNN_LSTM:Values
0,1,2, and3reference weight matrices or bias vectors used in conjunction with the input from the previous layer or input to the RNN model.Values
4,5,6, and7reference weight matrices or bias vectors used in conjunction with the hidden state from the previous time step or the initial hidden state.Value 8 corresponds to the projection matrix, if enabled (there is no bias in this operation).
Values and their LSTM gates:
linLayerID 0and4correspond to the input gate.linLayerID 1and5correspond to the forget gate.linLayerID 2and6correspond to the new cell state calculations with hyperbolic tangent.linLayerID 3and7correspond to the output gate.
If
cellModeinrnnDescwas set toCUDNN_GRU:Values 0,1, and2reference weight matrices or bias vectors used in conjunction with the input from the previous layer or input to the RNN model.Values 3,4, and5reference weight matrices or bias vectors used in conjunction with the hidden state from the previous time step or the initial hidden state.
Values and their GRU gates:
linLayerID 0and3correspond to the reset gate.linLayerID 1and4reference to the update gate.linLayerID 2and5correspond to the new hidden state calculations with hyperbolic tangent.
For more information on modes and bias modes, refer to cudnnRNNMode_t.
mDescOutput. Handle to a previously created tensor descriptor. The shape of the corresponding weight matrix is returned in this descriptor in the following format:
dimA[3] = {1, rows, cols}. The reported number of tensor dimensions is zero when the weight matrix does not exist. This situation occurs for input GEMM matrices of the first layer whenCUDNN_SKIP_INPUTis selected or for the LSTM projection matrix when the feature is disabled.mAddrOutput. Pointer to the beginning of the weight matrix within the weight space buffer. When the weight matrix does not exist, the returned address written to
mAddrisNULL. Starting from cuDNN version 9.1, themDescandmAddrarguments can be bothNULL. In this case, the shape of the weight matrix and its address will not be reported. By assigningmDesc=NULLandmAddr=NULL, you can retrieve information about bias vectors only.bDescOutput. Handle to a previously created tensor descriptor. The shape of the corresponding bias vector is returned in this descriptor in the following format:
dimA[3] = {1, rows, 1}. The reported number of tensor dimensions is zero when the bias vector does not exist.bAddrOutput. Pointer to the beginning of the bias vector within the weight space buffer. When the bias vector does not exist, the returned address is
NULL. Starting from cuDNN version 9.1, thebDescandbAddrarguments can be bothNULL. In this case, the shape of the bias vector and its address will not be reported. By assigningbDesc=NULLandbAddr=NULL, you can retrieve information about weight matrices only.
Returns
CUDNN_STATUS_SUCCESSThe query was completed successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was encountered. For example, the value of
pseudoLayeris out of range orlinLayerIDis negative or larger than8.CUDNN_STATUS_INVALID_VALUESome weight/bias elements are outside the weight space buffer boundaries.
CUDNN_STATUS_NOT_INITIALIZEDThe cuDNN library was not initialized properly.
cudnnGetRNNWeightSpaceSize()#
This function reports the required size of the weight space buffer in bytes. The weight space buffer holds all RNN weight matrices and bias vectors.
cudnnStatus_t cudnnGetRNNWeightSpaceSize( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, size_t *weightSpaceSize);
Parameters
handleInput. The current cuDNN context handle.
rnnDescInput. A previously initialized RNN descriptor.
weightSpaceSizeOutput. Minimum size in bytes of GPU memory needed for all RNN trainable parameters.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was encountered. For example, any input argument was
NULL.CUDNN_STATUS_NOT_INITIALIZEDThe cuDNN library was not initialized properly.
cudnnGetSeqDataDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function retrieves settings from a previously created sequence data descriptor. The user can assign NULL to any pointer except seqDataDesc when the retrieved value is not needed. The nbDimsRequested argument applies to both dimA[] and axes[] arrays. A positive value of nbDimsRequested or seqLengthSizeRequested is ignored when the corresponding array, dimA[], axes[], or seqLengthArray[] is NULL.
cudnnStatus_t cudnnGetSeqDataDescriptor( const cudnnSeqDataDescriptor_t seqDataDesc, cudnnDataType_t *dataType, int *nbDims, int nbDimsRequested, int dimA[], cudnnSeqDataAxis_t axes[], size_t *seqLengthArraySize, size_t seqLengthSizeRequested, int seqLengthArray[], void *paddingFill);
The cudnnGetSeqDataDescriptor() function does not report the actual strides in the sequence data buffer. Those strides can be handy in computing the offset to any sequence data element. The user must precompute strides based on the axes[] and dimA[] arrays reported by the cudnnGetSeqDataDescriptor() function. Below is sample code that performs this task:
// Array holding sequence data strides. size_t strA[CUDNN_SEQDATA_DIM_COUNT] = {0}; // Compute strides from dimension and order arrays. size_t stride = 1; for (int i = nbDims - 1; i >= 0; i--) { int j = int(axes[i]); if (unsigned(j) < CUDNN_SEQDATA_DIM_COUNT-1 && strA[j] == 0) { strA[j] = stride; stride *= dimA[j]; } else { fprintf(stderr, "ERROR: invalid axes[%d]=%d\n\n", i, j); abort(); } }
Now, the strA[] array can be used to compute the index to any sequence data element, for example:
// Using four indices (batch, beam, time, vect) with ranges already checked. size_t base = strA[CUDNN_SEQDATA_BATCH_DIM] * batch + strA[CUDNN_SEQDATA_BEAM_DIM] * beam + strA[CUDNN_SEQDATA_TIME_DIM] * time; val = seqDataPtr[base + vect];
The above code assumes that all four indices (batch, beam, time, vect) are less than the corresponding value in the dimA[] array. The sample code also omits the strA[CUDNN_SEQDATA_VECT_DIM] stride because its value is always 1, meaning, elements of one vector occupy a contiguous block of memory.
Parameters
seqDataDescInput. Sequence data descriptor.
dataTypeOutput. Data type used in the sequence data buffer.
nbDimsOutput. The number of active dimensions in the
dimA[]andaxes[]arrays.nbDimsRequestedInput. The maximum number of consecutive elements that can be written to
dimA[]andaxes[]arrays starting from index zero. The recommended value for this argument isCUDNN_SEQDATA_DIM_COUNT.dimA[]Output. Integer array holding sequence data dimensions.
axes[]Output. Array of cudnnSeqDataAxis_t that defines the layout of sequence data in memory.
seqLengthArraySizeOutput. The number of required elements in
seqLengthArray[]to save all sequence lengths.seqLengthSizeRequestedInput. The maximum number of consecutive elements that can be written to the
seqLengthArray[]array starting from index zero.seqLengthArray[]Output. Integer array holding sequence lengths.
paddingFillOutput. Pointer to a storage location of
dataTypewith the fill value that should be written to all padding vectors. UseNULLwhen an explicit initialization of output padding vectors was not requested.
Returns
CUDNN_STATUS_SUCCESSRequested sequence data descriptor fields were retrieved successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found.
CUDNN_STATUS_INTERNAL_ERRORAn inconsistent internal state was encountered.
cudnnMultiHeadAttnBackwardData()#
This function has been deprecated in cuDNN 9.0.
This function computes exact, first-order derivatives of the multihead attention block with respect to its inputs: Q, K, V. If y=F(w) is a vector-valued function that represents the multihead attention layer and it takes some vector \(\chi\epsilon\mathbb{R}^{n}\) as an input (with all other parameters and inputs constant), and outputs vector \(\chi\epsilon\mathbb{R}^{m}\), then cudnnMultiHeadAttnBackwardData() computes the result of \(\left(\partial y_{i}/\partial x_{j}\right)^{T} \delta_{out}\) where \(\delta_{out}\) is the mx1 gradient of the loss function with respect to multihead attention outputs. The \(\delta_{out}\) gradient is back propagated through prior layers of the deep learning model. \(\partial y_{i}/\partial x_{j}\) is the mxn Jacobian matrix of F(x). The input is supplied via the dout argument and gradient results for Q, K, V are written to the dqueries, dkeys, and dvalues buffers.
The cudnnMultiHeadAttnBackwardData() function does not output partial derivatives for residual connections because this result is equal to \(\delta_{out}\). If the multihead attention model enables residual connections sourced directly from Q, then the dout tensor needs to be added to dqueries to obtain the correct result of the latter. This operation is demonstrated in the cuDNN multiHeadAttention sample code.
cudnnStatus_t cudnnMultiHeadAttnBackwardData( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, const int loWinIdx[], const int hiWinIdx[], const int devSeqLengthsDQDO[], const int devSeqLengthsDKDV[], const cudnnSeqDataDescriptor_t doDesc, const void *dout, const cudnnSeqDataDescriptor_t dqDesc, void *dqueries, const void *queries, const cudnnSeqDataDescriptor_t dkDesc, void *dkeys, const void *keys, const cudnnSeqDataDescriptor_t dvDesc, void *dvalues, const void *values, size_t weightSizeInBytes, const void *weights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
The cudnnMultiHeadAttnBackwardData() function must be invoked after cudnnMultiHeadAttnForward(). The loWinIdx[], hiWinIdx[], queries, keys, values, weights, and reserveSpace arguments should be the same as in the cudnnMultiHeadAttnForward() call. devSeqLengthsDQDO[] and devSeqLengthsDKDV[] device arrays should contain the same start and end attention window indices as devSeqLengthsQO[] and devSeqLengthsKV[] arrays in the forward function invocation.
Note
cudnnMultiHeadAttnBackwardData()does not verify that sequence lengths stored indevSeqLengthsDQDO[]anddevSeqLengthsDKDV[]contain the same settings asseqLengthArray[]in the corresponding sequence data descriptor.
Parameters
handleInput. The current cuDNN context handle.
attnDescInput. A previously initialized attention descriptor.
loWinIdx[],hiWinIdx[]Input. Two host integer arrays specifying the start and end indices of the attention window for each Q time-step. The start index in K, V sets is inclusive, and the end index is exclusive.
devSeqLengthsDQDO[]Input. Device array containing a copy of the sequence length array from the
dqDescordoDescsequence data descriptor.devSeqLengthsDKDV[]Input. Device array containing a copy of the sequence length array from the
dkDescordvDescsequence data descriptor.doDescInput. Descriptor for the \(\delta_{out}\) gradients (vectors of partial derivatives of the loss function with respect to the multihead attention outputs).
doutInput. Pointer to the \(\delta_{out}\) gradient data in the device memory.
dqDescInput. Descriptor for
queriesanddqueriessequence data.dqueriesOutput. Device pointer to gradients of the loss function computed with respect to
queriesvectors.queriesInput. Pointer to
queriesdata in the device memory. This is the same input as in cudnnMultiHeadAttnForward().dkDescInput. Descriptor for keys and
dkeyssequence data.dkeysOutput. Device pointer to gradients of the loss function computed with respect to
keysvectors.keysInput. Pointer to
keysdata in the device memory. This is the same input as in cudnnMultiHeadAttnForward().dvDescInput. Descriptor for
valuesanddvaluessequence data.dvaluesOutput. Device pointer to gradients of the loss function computed with respect to
valuesvectors.valuesInput. Pointer to
valuesdata in the device memory. This is the same input as in cudnnMultiHeadAttnForward().weightSizeInBytesInput. Size of the
weightbuffer in bytes where all multihead attention trainable parameters are stored.weightsInput. Address of the
weightbuffer in the device memory.workSpaceSizeInBytesInput. Size of the workspace buffer in bytes used for temporary API storage.
workSpaceInput/Output. Address of the workspace buffer in the device memory.
reserveSpaceSizeInBytesInput. Size of the reserve-space buffer in bytes used for data exchange between forward and backward (gradient) API calls.
reserveSpaceInput/Output. Address to the reserve-space buffer in the device memory.
Returns
CUDNN_STATUS_SUCCESSNo errors were detected while processing API input arguments and launching GPU kernels.
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered.
CUDNN_STATUS_EXECUTION_FAILEDThe process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
CUDNN_STATUS_INTERNAL_ERRORAn inconsistent internal state was encountered.
CUDNN_STATUS_NOT_SUPPORTEDA requested option or a combination of input arguments is not supported.
CUDNN_STATUS_ALLOC_FAILEDInsufficient amount of shared memory to launch a GPU kernel.
cudnnMultiHeadAttnBackwardWeights()#
This function has been deprecated in cuDNN 9.0.
This function computes exact, first-order derivatives of the multihead attention block with respect to its trainable parameters: projection weights and projection biases. If y=F(w) is a vector-valued function that represents the multihead attention layer and it takes some vector \(\chi\epsilon\mathbb{R}^{n}\) of “flatten” weights or biases as an input (with all other parameters and inputs fixed), and outputs vector \(\chi\epsilon\mathbb{R}^{m}\), then cudnnMultiHeadAttnBackwardWeights() computes the result of \(\left(\partial y_{i}/\partial w_{j}\right)^{T} \delta_{out}\) where \(\delta_{out}\) is the mx1 gradient of the loss function with respect to multihead attention outputs. The \(\delta_{out}\) gradient is back propagated through prior layers of the deep learning model. \(\partial y_{i}/\partial w_{j}\) is the mxn Jacobian matrix of F(w). The \(\delta_{out}\) input is supplied via the dout argument.
cudnnStatus_t cudnnMultiHeadAttnBackwardWeights( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, cudnnWgradMode_t addGrad, const cudnnSeqDataDescriptor_t qDesc, const void *queries, const cudnnSeqDataDescriptor_t kDesc, const void *keys, const cudnnSeqDataDescriptor_t vDesc, const void *values, const cudnnSeqDataDescriptor_t doDesc, const void *dout, size_t weightSizeInBytes, const void *weights, void *dweights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
All gradient results with respect to weights and biases are written to the dweights buffer. The size and the organization of the dweights buffer is the same as the weights buffer that holds multihead attention weights and biases. The cuDNN multiHeadAttention sample code demonstrates how to access those weights.
Gradient of the loss function with respect to weights or biases is typically computed over multiple batches. In such a case, partial results computed for each batch should be summed together. The addGrad argument specifies if the gradients from the current batch should be added to previously computed results or the dweights buffer should be overwritten with the new results.
The cudnnMultiHeadAttnBackwardWeights() function should be invoked after cudnnMultiHeadAttnBackwardData(). The queries, keys, values, weights, and reserveSpace arguments should be the same as in cudnnMultiHeadAttnForward() and cudnnMultiHeadAttnBackwardData() calls. The dout argument should be the same as in cudnnMultiHeadAttnBackwardData().
Parameters
handleInput. The current cuDNN context handle.
attnDescInput. A previously initialized attention descriptor.
addGradInput. Weight gradient output mode.
qDescInput. Descriptor for the query sequence data.
queriesInput. Pointer to
queriessequence data in the device memory.kDescInput. Descriptor for the
keyssequence data.keysInput. Pointer to
keyssequence data in the device memory.vDescInput. Descriptor for the
valuessequence data.valuesInput. Pointer to
valuessequence data in the device memory.doDescInput. Descriptor for the \(\delta_{out}\) gradients (vectors of partial derivatives of the loss function with respect to the multihead attention outputs).
doutInput. Pointer to the \(\delta_{out}\) gradient vectors in the device memory.
weightSizeInBytesInput. Size of the
weightsanddweightsbuffers in bytes.weightsInput. Address of the
weightbuffer in the device memory.dweightsOutput. Address of the weight gradient buffer in the device memory.
workSpaceSizeInBytesInput. Size of the workspace buffer in bytes used for temporary API storage.
workSpaceInput/Output. Address of the workspace buffer in the device memory.
reserveSpaceSizeInBytesInput. Size of the reserve-space buffer in bytes used for data exchange between forward and backward (gradient) API calls.
reserveSpaceInput/Output. Address to the reserve-space buffer in the device memory.
Returns
CUDNN_STATUS_SUCCESSNo errors were detected while processing API input arguments and launching GPU kernels.
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered.
CUDNN_STATUS_EXECUTION_FAILEDThe process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
CUDNN_STATUS_INTERNAL_ERRORAn inconsistent internal state was encountered.
CUDNN_STATUS_NOT_SUPPORTEDA requested option or a combination of input arguments is not supported.
cudnnMultiHeadAttnForward()#
This function has been deprecated in cuDNN 9.0.
The cudnnMultiHeadAttnForward() function computes the forward responses of the multihead attention layer. When reserveSpaceSizeInBytes=0 and reserveSpace=NULL, the function operates in the inference mode in which backward (gradient) functions are not invoked, otherwise, the training mode is assumed. In the training mode, the reserve space is used to pass intermediate results from cudnnMultiHeadAttnForward() to cudnnMultiHeadAttnBackwardData() and from cudnnMultiHeadAttnBackwardData() to cudnnMultiHeadAttnBackwardWeights().
cudnnStatus_t cudnnMultiHeadAttnForward( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, int currIdx, const int loWinIdx[], const int hiWinIdx[], const int devSeqLengthsQO[], const int devSeqLengthsKV[], const cudnnSeqDataDescriptor_t qDesc, const void *queries, const void *residuals, const cudnnSeqDataDescriptor_t kDesc, const void *keys, const cudnnSeqDataDescriptor_t vDesc, const void *values, const cudnnSeqDataDescriptor_t oDesc, void *out, size_t weightSizeInBytes, const void *weights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
In the inference mode, the currIdx specifies the time-step or sequence index of the embedding vectors to be processed. In this mode, the user can perform one iteration for time-step zero (currIdx=0), then update Q, K, V vectors and the attention window, and execute the next step (currIdx=1). The iterative process can be repeated for all time-steps.
When all Q time-steps are available (for example, in the training mode or in the inference mode on the encoder side in self-attention), the user can assign a negative value to currIdx and the cudnnMultiHeadAttnForward() API will automatically sweep through all Q time-steps.
The loWinIdx[] and hiWinIdx[] host arrays specify the attention window size for each Q time-step. In a typical self-attention case, the user must include all previously visited embedding vectors but not the current or future vectors. In this situation, the user should set:
currIdx=0: loWinIdx[0]=0; hiWinIdx[0]=0; // initial time-step, no attention window currIdx=1: loWinIdx[1]=0; hiWinIdx[1]=1; // attention window spans one vector currIdx=2: loWinIdx[2]=0; hiWinIdx[2]=2; // attention window spans two vectors (...)
When currIdx is negative in cudnnMultiHeadAttnForward(), the loWinIdx[] and hiWinIdx[] arrays must be fully initialized for all time-steps. When cudnnMultiHeadAttnForward() is invoked with currIdx=0, currIdx=1, currIdx=2, and so on, then the user can update loWinIdx[currIdx] and hiWinIdx[currIdx] elements only before invoking the forward response function. All other elements in the loWinIdx[] and hiWinIdx[] arrays will not be accessed. Any adaptive attention window scheme can be implemented that way.
Use the following settings when the attention window should be the maximum size, for example, in cross-attention:
currIdx=0: loWinIdx[0]=0; hiWinIdx[0]=maxSeqLenK; currIdx=1: loWinIdx[1]=0; hiWinIdx[1]=maxSeqLenK; currIdx=2: loWinIdx[2]=0; hiWinIdx[2]=maxSeqLenK; (...)
The maxSeqLenK value above should be equal to or larger than dimA[CUDNN_SEQDATA_TIME_DIM] in the kDesc descriptor. A good choice is to use maxSeqLenK=INT_MAX from limits.h.
Note
The actual length of any K sequence defined in
seqLengthArray[]in cudnnSetSeqDataDescriptor() can be shorter thanmaxSeqLenK. The effective attention window span is computed based onseqLengthArray[]stored in the K sequence descriptor and indices held inloWinIdx[]andhiWinIdx[]arrays.
devSeqLengthsQO[] and devSeqLengthsKV[] are pointers to device (not host) arrays with Q, O, and K, V sequence lengths. Note that the same information is also passed in the corresponding descriptors of type cudnnSeqDataDescriptor_t on the host side. The need for extra device arrays comes from the asynchronous nature of cuDNN calls and limited size of the constant memory dedicated to GPU kernel arguments. When the cudnnMultiHeadAttnForward() API returns, the sequence length arrays stored in the descriptors can be immediately modified for the next iteration. However, the GPU kernels launched by the forward call may not have started at this point. For this reason, copies of sequence arrays are needed on the device side to be accessed directly by GPU kernels. Those copies cannot be created inside the cudnnMultiHeadAttnForward() function for very large K, V inputs without the device memory allocation and CUDA stream synchronization.
To reduce the cudnnMultiHeadAttnForward() API overhead, devSeqLengthsQO[] and devSeqLengthsKV[] device arrays are not validated to contain the same settings as seqLengthArray[] in the sequence data descriptors.
Sequence lengths in the kDesc and vDesc descriptors should be the same. Similarly, sequence lengths in the qDesc and oDesc descriptors should match. The user can define six different data layouts in the qDesc, kDesc, vDesc, and oDesc descriptors. Refer to the cudnnSetSeqDataDescriptor() function for the discussion of those layouts. All multihead attention API calls require that the same layout is used in all sequence data descriptors.
In the transformer model, the multihead attention block is tightly coupled with the layer normalization and residual connections. cudnnMultiHeadAttnForward() does not encompass the layer normalization but it can be used to handle residual connections as depicted in the following figure.
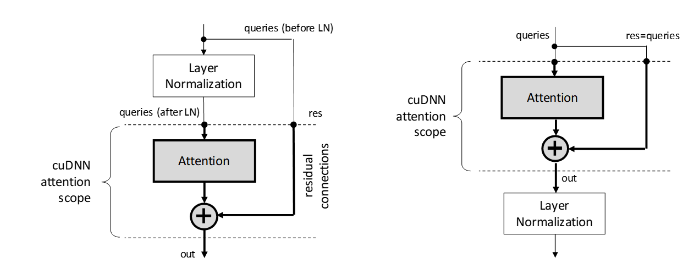
Queries and residuals share the same qDesc descriptor in cudnnMultiHeadAttnForward(). When residual connections are disabled, the residuals pointer should be NULL. When residual connections are enabled, the vector length in qDesc should match the vector length specified in the oDesc descriptor, so that a vector addition is feasible.
The queries, keys, and values pointers are not allowed to be NULL, even when K and V are the same inputs or Q, K, V are the same inputs.
Parameters
handleInput. The current cuDNN context handle.
attnDescInput. A previously initialized attention descriptor.
currIdxInput. Time-step in queries to process. When the
currIdxargument is negative, all Q time-steps are processed. WhencurrIdxis zero or positive, the forward response is computed for the selected time-step only. The latter input can be used in inference mode only, to process one time-step while updating the next attention window and Q, R, K, V inputs in-between calls.loWinIdx[],hiWinIdx[]Input. Two host integer arrays specifying the start and end indices of the attention window for each Q time-step. The start index in K, V sets is inclusive, and the end index is exclusive.
devSeqLengthsQO[]Input. Device array specifying sequence lengths of query, residual, and output sequence data.
devSeqLengthsKV[]Input. Device array specifying sequence lengths of key and value input data.
qDescInput. Descriptor for the query and residual sequence data.
queriesInput. Pointer to queries data in the device memory.
residualsInput. Pointer to residual data in device memory. Set this argument to
NULLif no residual connections are required.kDescInput. Descriptor for the keys sequence data.
keysInput. Pointer to
keysdata in the device memory.vDescInput. Descriptor for the
valuessequence data.valuesInput. Pointer to
valuesdata in the device memory.oDescInput. Descriptor for the multihead attention output sequence data.
outOutput. Pointer to device memory where the output response should be written.
weightSizeInBytesInput. Size of the
weightbuffer in bytes where all multihead attention trainable parameters are stored.weightsInput. Pointer to the
weightbuffer in device memory.workSpaceSizeInBytesInput. Size of the workspace buffer in bytes used for temporary API storage.
workSpaceInput/Output. Pointer to the workspace buffer in device memory.
reserveSpaceSizeInBytesInput. Size of the reserve-space buffer in bytes used for data exchange between forward and backward (gradient) API calls. This parameter should be zero in the inference mode and non-zero in the training mode.
reserveSpaceInput/Output. Pointer to the reserve-space buffer in device memory. This argument should be
NULLin inference mode andnon-NULLin the training mode.
Returns
CUDNN_STATUS_SUCCESSNo errors were detected while processing API input arguments and launching GPU kernels.
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered. Some examples include:
a required input pointer was
NULLcurrIdxwas out of boundthe descriptor value for
attention,query,key,value, andoutputwere incompatible with one another
CUDNN_STATUS_EXECUTION_FAILEDThe process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
CUDNN_STATUS_INTERNAL_ERRORAn inconsistent internal state was encountered.
CUDNN_STATUS_NOT_SUPPORTEDA requested option or a combination of input arguments is not supported.
CUDNN_STATUS_ALLOC_FAILEDInsufficient amount of shared memory to launch a GPU kernel.
cudnnRNNBackwardData_v8()#
This function computes exact, first-order derivatives of the RNN model with respect to its inputs: x, hx and for the LSTM cell type also cx. If o = [y, hy, cy] = F(x, hx, cx) = F(z) is a vector-valued function that represents the entire RNN model and it takes vectors x (for all time-steps) and vectors hx, cx (for all layers) as inputs, concatenated into \(\textbf{z}\epsilon\mathbb{R}^{n}\) (network weights and biases are assumed constant), and outputs vectors y, hy, cy concatenated into a vector \(\textbf{o}\epsilon\mathbb{R}^{m}\), then cudnnRNNBackwardData_v8() computes the result of \(\left(\partial o_{i}/\partial z_{j}\right)^{T} \delta_{out}\) where \(\delta_{out}\) is the mx1 gradient of the loss function with respect to all RNN outputs. The \(\delta_{out}\) gradient is back propagated through prior layers of the deep learning model, starting from the model output. \(\partial o_{i}/\partial z_{j}\) is the mxn Jacobian matrix of F(z). The \(\delta_{out}\) input is supplied via the dy, dhy, and dcy arguments and gradient results \(\left(\partial o_{i}/\partial z_{j}\right)^{T} \delta_{out}\) are written to the dx, dhx, and dcx buffers.
cudnnStatus_t cudnnRNNBackwardData_v8( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, const int32_t devSeqLengths[], cudnnRNNDataDescriptor_t yDesc, const void *y, const void *dy, cudnnRNNDataDescriptor_t xDesc, void *dx, cudnnTensorDescriptor_t hDesc, const void *hx, const void *dhy, void *dhx, cudnnTensorDescriptor_t cDesc, const void *cx, const void *dcy, void *dcx, size_t weightSpaceSize, const void *weightSpace, size_t workSpaceSize, void *workSpace, size_t reserveSpaceSize, void *reserveSpace);
Locations of x, y, hx, cx, hy, cy, dx, dy, dhx, dcx, dhy, and dcy signals a multi-layer RNN model are shown in the following figure. Note that internal RNN signals (between time-steps and between layers) are not exposed by the cudnnRNNBackwardData_v8() function.
Memory addresses to the primary RNN output y, the initial hidden state hx, and the initial cell state cx (for LSTM only) should point to the same data as in the preceding cudnnRNNForward() call. The dy and dx pointers cannot be NULL.
The cudnnRNNBackwardData_v8() function accepts any combination of dhy, dhx, dcy, dcx buffer addresses being NULL. When dhy or dcy are NULL, it is assumed that those inputs are zero. When dhx or dcx pointers are NULL, then the corresponding results are not written by cudnnRNNBackwardData_v8(). When all hx, dhy, dhx pointers are NULL, then the corresponding tensor descriptor hDesc can be NULL too. The same rule applies to the cx, dcy, dcx pointers and the cDesc tensor descriptor.
The cudnnRNNBackwardData_v8() function allows the user to use padded layouts for inputs y, dy, and output dx. In padded or unpacked layouts (CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED, CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED) each sequence of vectors in a mini-batch has a fixed length defined by the maxSeqLength argument in the cudnnSetRNNDataDescriptor() function. The term “unpacked” refers here to the presence of padding vectors, and not unused address ranges between contiguous vectors.
Each padded, fixed-length sequence starts from a segment of valid vectors. The valid vector count is stored in seqLengthArray passed to cudnnSetRNNDataDescriptor(), such that 0 < seqLengthArray[i] <= maxSeqLength for all sequences in a mini-batch, that is, for i=0..batchSize-1. The remaining, padding vectors make the combined sequence length equal to maxSeqLength. Both sequence-major and batch-major padded layouts are supported. In addition, a packed sequence-major layout is supported: CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED.
In the latter layout, sequences of vectors in a mini-batch are sorted in the descending order according to the sequence lengths. First all vectors for time step zero are stored. They are followed by all vectors for time step one, and so on. This layout uses no padding vectors.
The same layout type must be specified in xDesc and yDesc descriptors.
Two host arrays named seqLengthArray in xDesc and yDesc RNN data descriptors must be the same. In addition, a copy of seqLengthArray in the device memory must be passed via the devSeqLengths argument. This array is supplied directly to GPU kernels. Starting in cuDNN 8.9.1, the devSeqLengths parameter is no longer required and can be set to NULL. The variable sequence length array is transferred automatically to GPU memory by the cudnnRNNBackwardData_v8() function.
The cudnnRNNBackwardData_v8() function does not verify that sequence lengths stored in devSeqLengths in GPU memory are the same as in xDesc and yDesc descriptors in CPU memory. Sequence length arrays from xDesc and yDesc descriptors are checked for consistency, however.
The cudnnRNNBackwardData_v8() function must be called after cudnnRNNForward(). The cudnnRNNForward() function should be invoked with the fwdMode argument of type cudnnForwardMode_t set to CUDNN_FWD_MODE_TRAINING.
Parameters
handleInput. The current cuDNN context handle.
rnnDescInput. A previously initialized RNN descriptor.
devSeqLengthsInput. A copy of
seqLengthArrayfromxDescoryDescRNN data descriptors. ThedevSeqLengthsarray must be stored in GPU memory as it is accessed asynchronously by GPU kernels, possibly after thecudnnRNNBackwardData_v8()function exists. In cuDNN 8.9.1 and later versions,devSeqLengthsshould beNULL.yDescInput. A previously initialized descriptor corresponding to the RNN model primary output. The
dataType,layout,maxSeqLength,batchSize, andseqLengthArrayneed to match that ofxDesc.y,dyInput. Data pointers to GPU buffers holding the RNN model primary output and gradient deltas (gradient of the loss function with respect to
y). Theyoutput should be produced by the preceding cudnnRNNForward() call. Theyanddyvectors are expected to be laid out in memory according to the layout specified byyDesc. The elements in the tensor (including elements in padding vectors) must be densely packed. Theyanddyarguments cannot beNULL.xDescInput. A previously initialized RNN data descriptor corresponding to the gradient of the loss function with respect to the RNN primary model input. The
dataType,layout,maxSeqLength,batchSize, andseqLengthArraymust match that ofyDesc. The parametervectorSizemust match theinputSizeargument passed to the cudnnSetRNNDescriptor_v8() function.dxOutput. Data pointer to GPU memory where back-propagated gradients of the loss function with respect to the RNN primary input x should be stored. The vectors are expected to be arranged in memory according to the layout specified by
xDesc. The elements in the tensor (including padding vectors) must be densely packed. This argument cannot beNULL.hDescInput. A tensor descriptor describing the initial RNN hidden state
hxand gradient deltasdhy, dhxof the loss function. Hidden state data and gradients must be fully packed. The first dimension of the tensor depends on thedirModeargument passed to the cudnnSetRNNDescriptor_v8() function.If
dirModeisCUDNN_UNIDIRECTIONAL, then the first dimension should match thenumLayersargument passed to cudnnSetRNNDescriptor_v8().If
dirModeisCUDNN_BIDIRECTIONAL, then the first dimension should be double thenumLayersargument passed to cudnnSetRNNDescriptor_v8().
The second dimension must match the
batchSizeparameter described inxDesc. The third dimension depends on whether RNN mode isCUDNN_LSTMand whether the LSTM projection is enabled. Specifically:If RNN mode is
CUDNN_LSTMand LSTM projection is enabled, the third dimension must match theprojSizeargument.Otherwise, the third dimension must match the
hiddenSizeargument.
hx,dhyInput. Addresses of GPU buffers with the RNN initial hidden state
hxand gradient deltasdhy. Data dimensions are described by thehDesctensor descriptor. If aNULLpointer is passed inhxordhyarguments, the corresponding buffer is assumed to contain all zeros.dhxOutput. Pointer to the GPU buffer where first-order derivatives corresponding to initial hidden state variables should be stored. Data dimensions are described by the
hDesctensor descriptor. If aNULLpointer is assigned todhx, the back-propagated derivatives are not saved.cDescInput. For LSTM networks only. This argument should be
NULLforRELU,TANH, orGRUcell types.cDescis a tensor descriptor specifying buffer layouts of the initial cell statecxand gradient deltasdcy, dcxof the loss function. Cell state data must be fully packed. The first dimension of the tensor depends on thedirModeargument passed to the cudnnSetRNNDescriptor_v8() call.If
dirModeisCUDNN_UNIDIRECTIONAL, then the first dimension should match thenumLayersargument passed to cudnnSetRNNDescriptor_v8().If
dirModeisCUDNN_BIDIRECTIONAL, then the first dimension should be double thenumLayersargument passed to cudnnSetRNNDescriptor_v8().
The second tensor dimension must match the
batchSizeparameter inxDesc. The third dimension must match thehiddenSizeargument passed to the cudnnSetRNNDescriptor_v8() call.cx,dcyInput. For LSTM networks only. Addresses of GPU buffers with the initial LSTM state data and gradient deltas
dcy. Data dimensions are described by thecDesctensor descriptor. If aNULLpointer is passed incxordcyarguments, the corresponding buffer is assumed to contain all zeros.dcxOutput. For LSTM networks only. Pointer to the GPU buffer where first-order derivatives corresponding to initial LSTM state variables should be stored. Data dimensions are described by the
cDesctensor descriptor. If aNULLpointer is assigned todcx, the back-propagated derivatives are not saved.weightSpaceSizeInput. Specifies the size in bytes of the provided weight space buffer.
weightSpaceInput. Address of the weight space buffer in GPU memory.
workSpaceSizeInput. Specifies the size in bytes of the provided workspace buffer.
workSpaceInput/Output. Address of the workspace buffer in GPU memory to store temporary data.
reserveSpaceSizeInput. Specifies the size in bytes of the reserve-space buffer.
reserveSpaceInput/Output. Address of the reserve-space buffer in GPU memory.
Returns
CUDNN_STATUS_SUCCESSNo errors were detected while processing API input arguments and launching GPU kernels.
CUDNN_STATUS_NOT_SUPPORTEDAt least one of the following conditions are met:
variable sequence length input is passed while
CUDNN_RNN_ALGO_PERSIST_STATIC,CUDNN_RNN_ALGO_PERSIST_DYNAMIC, orCUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_His specifiedCUDNN_RNN_ALGO_PERSIST_STATICorCUDNN_RNN_ALGO_PERSIST_DYNAMICis requested on pre-Pascal devicesthe ‘double’ floating point type is used for input/output and the
CUDNN_RNN_ALGO_PERSIST_STATICalgo
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered. Some examples include:
some descriptors or data buffer addresses are
NULLsettings in
rnnDesc,xDesc,yDesc,hDesc, orcDescdescriptors are invalidweightSpaceSize,workSpaceSize, orreserveSpaceSizeis too small
CUDNN_STATUS_MAPPING_ERRORA GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle when cudnnCreate() was invoked.
This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If
CUDNN_STATUS_MAPPING_ERRORis returned by cudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.CUDNN_STATUS_EXECUTION_FAILEDThe process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
CUDNN_STATUS_ALLOC_FAILEDThe function was unable to allocate CPU memory.
cudnnRNNBackwardWeights_v8()#
This function computes exact, first-order derivatives of the RNN model with respect to all trainable parameters: weights and biases. If o = [y, hy, cy] = F(w) is a vector-valued function that represents the multi-layer RNN model and it takes some vector \(\textbf{w}\epsilon\mathbb{R}^{n}\) of “flatten” weights or biases as input (with all other data inputs constant), and outputs vector \(\textbf{o}\epsilon\mathbb{R}^{m}\), then cudnnRNNBackwardWeights_v8() computes the result of \(\left(\partial o_{i}/\partial w_{j}\right)^{T} \delta_{out}\) where \(\delta_{out}\) is the mx1 gradient of the loss function with respect to all RNN outputs. The \(\delta_{out}\) gradient is back propagated through prior layers of the deep learning model, starting from the model output. \(\partial o_{i}/\partial w_{j}\) is the mxn Jacobian matrix of F(w). The \(\delta_{out}\) input is supplied via the dy, dhy, and dcy arguments in the cudnnRNNBackwardData_v8() function.
cudnnStatus_t cudnnRNNBackwardWeights_v8( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnWgradMode_t addGrad, const int32_t devSeqLengths[], cudnnRNNDataDescriptor_t xDesc, const void *x, cudnnTensorDescriptor_t hDesc, const void *hx, cudnnRNNDataDescriptor_t yDesc, const void *y, size_t weightSpaceSize, void *dweightSpace, size_t workSpaceSize, void *workSpace, size_t reserveSpaceSize, void *reserveSpace);
All gradient results \(\left(\partial o_{i}/\partial w_{j}\right)^{T} \delta_{out}\) with respect to weights and biases are written to the dweightSpace buffer. The size and the organization of the dweightSpace buffer is the same as the weightSpace buffer that holds RNN weights and biases.
Gradient of the loss function with respect to weights and biases is typically computed over multiple mini-batches. In such a case, partial results computed for each mini-batch should be aggregated. The addGrad argument specifies if gradients from the current mini-batch should be added to previously computed results (CUDNN_WGRAD_MODE_ADD) or the dweightSpace buffer should be overwritten with the new results (CUDNN_WGRAD_MODE_SET). Currently, the cudnnRNNBackwardWeights_v8() function supports the CUDNN_WGRAD_MODE_ADD mode only so the dweightSpace buffer should be zeroed by the user before invoking the routine for the first time.
The same sequence lengths must be specified in the xDesc descriptor and in the device array devSeqLengths. Starting in cuDNN 8.9.1, the devSeqLengths parameter is no longer required and can be set to NULL. The variable sequence length array is transferred automatically to GPU memory by the cudnnRNNBackwardWeights_v8() function.
The cudnnRNNBackwardWeights_v8() function should be invoked after cudnnRNNBackwardData_v8().
Parameters
handleInput. The current cuDNN context handle.
rnnDescInput. A previously initialized RNN descriptor.
addGradInput. Weight gradient output mode. For more details, refer to the description of the cudnnWgradMode_t enumerated type. Currently, only the
CUDNN_WGRAD_MODE_ADDmode is supported by thecudnnRNNBackwardWeights_v8()function.devSeqLengthsInput. A copy of
seqLengthArrayfrom thexDescRNN data descriptor. ThedevSeqLengthsarray must be stored in GPU memory as it is accessed asynchronously by GPU kernels, possibly after thecudnnRNNBackwardWeights_v8()function exists. In cuDNN 8.9.1 and later versions,devSeqLengthsshould beNULL.xDescInput. A previously initialized descriptor corresponding to the RNN model input data. This is the same RNN data descriptor as used in the preceding cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
xInput. Pointer to the GPU buffer with the primary RNN input. The same buffer address
xshould be provided in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.hDescInput. A tensor descriptor describing the initial RNN hidden state. Hidden state data are fully packed. This is the same tensor descriptor as used in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
hxInput. Pointer to the GPU buffer with the RNN initial hidden state. The same buffer address
hxshould be provided in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.yDescInput. A previously initialized descriptor corresponding to the RNN model output data. This is the same RNN data descriptor as used in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
yOutput. Pointer to the GPU buffer with the primary RNN output as generated by the prior cudnnRNNForward() call. Data in the
ybuffer are described by theyDescdescriptor. Elements in theytensor (including elements in padding vectors) must be densely packed.weightSpaceSizeInput. Specifies the size in bytes of the provided weight space buffer.
dweightSpaceOutput. Address of the weight space buffer in GPU memory.
workSpaceSizeInput. Specifies the size in bytes of the provided workspace buffer.
workSpaceInput/Output. Address of the workspace buffer in GPU memory to store temporary data.
reserveSpaceSizeInput. Specifies the size in bytes of the reserve-space buffer.
reserveSpaceInput/Output. Address of the reserve-space buffer in GPU memory.
Returns
CUDNN_STATUS_SUCCESSNo errors were detected while processing API input arguments and launching GPU kernels.
CUDNN_STATUS_NOT_SUPPORTEDThe function does not support the provided configuration.
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered. Some examples include:
some descriptors or data buffer addresses are
NULLsettings in
rnnDesc,xDesc,yDesc, orhDescdescriptors are invalidweightSpaceSize,workSpaceSize, orreserveSpaceSizevalues are too smallthe
addGradargument is not equal toCUDNN_WGRAD_MODE_ADD
CUDNN_STATUS_EXECUTION_FAILEDThe process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
CUDNN_STATUS_ALLOC_FAILEDThe function was unable to allocate CPU memory
cudnnRNNForward()#
This routine computes the forward response of the recurrent neural network described by rnnDesc with inputs in x, hx, cx, and weights/biases in the weightSpace buffer. RNN outputs are written to y, hy, and cy buffers. Locations of x, y, hx, cx, hy, and cy signals in the multi-layer RNN model are shown in the following figure. Note that internal RNN signals between time-steps and between layers are not exposed to the user.
cudnnStatus_t cudnnRNNForward( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnForwardMode_t fwdMode, const int32_t devSeqLengths[], cudnnRNNDataDescriptor_t xDesc, const void *x, cudnnRNNDataDescriptor_t yDesc, void *y, cudnnTensorDescriptor_t hDesc, const void *hx, void *hy, cudnnTensorDescriptor_t cDesc, const void *cx, void *cy, size_t weightSpaceSize, const void *weightSpace, size_t workSpaceSize, void *workSpace, size_t reserveSpaceSize, void *reserveSpace);
The next figure depicts data flow when the RNN model is bidirectional. In this mode, each RNN physical layer consists of two consecutive pseudo-layers, each with its own weights, biases, the initial hidden state hx, and for LSTM, also the initial cell state cx. Even pseudo-layers 0, 2, 4 process input vectors from left to right or in the forward (F) direction. Odd pseudo-layers 1, 3, 5 process input vectors from right to left or in the reverse (R) direction. Two successive pseudo-layers operate on the same input vectors, just in a different order. Pseudo-layers 0 and 1 access the original sequences stored in the x buffer. Outputs of F and R cells are concatenated so vectors fed to the next two pseudo-layers have lengths of 2x hiddenSize or 2x projSize. Input GEMMs in subsequent pseudo-layers adjust vector lengths to 1x hiddenSize.
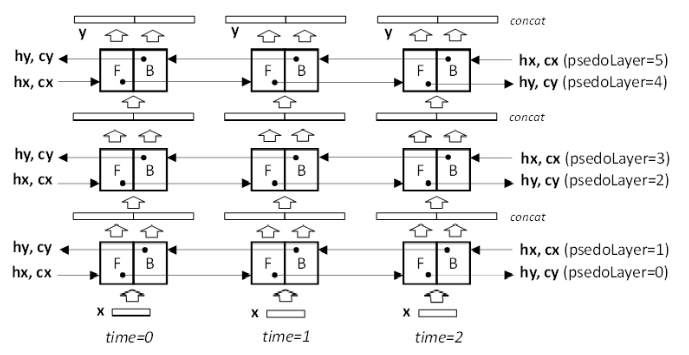
When the fwdMode parameter is set to CUDNN_FWD_MODE_TRAINING, the cudnnRNNForward() function stores intermediate data required to compute first order derivatives in the reserve space buffer. Work and reserve space buffer sizes should be computed by the cudnnGetRNNTempSpaceSizes() function with the same fwdMode setting as used in the cudnnRNNForward() call.
The same layout type must be specified in xDesc and yDesc descriptors. The same sequence lengths must be configured in xDesc, yDesc and in the device array devSeqLengths. Starting in cuDNN 8.9.1, the devSeqLengths parameter is no longer required and can be set to NULL. The variable sequence length array is transferred automatically to GPU memory by the cudnnRNNForward() function.
The cudnnRNNForward() function does not verify that sequence lengths stored in devSeqLengths in GPU memory are the same as in xDesc and yDesc descriptors in CPU memory. Sequence length arrays from xDesc and yDesc descriptors are checked for consistency, however.
Parameters
handleInput. The current cuDNN context handle.
rnnDescInput. A previously initialized RNN descriptor.
fwdModeInput. Specifies inference or training mode (
CUDNN_FWD_MODE_INFERENCEandCUDNN_FWD_MODE_TRAINING). In the training mode, additional data is stored in the reserve space buffer. This information is used in the backward pass to compute derivatives.devSeqLengthsInput. A copy of
seqLengthArrayfromxDescoryDescRNN data descriptor. ThedevSeqLengthsarray must be stored in GPU memory as it is accessed asynchronously by GPU kernels, possibly after thecudnnRNNForward()function exists. In cuDNN 8.9.1 and later versions,devSeqLengthsshould beNULL.xDescInput. A previously initialized descriptor corresponding to the RNN model primary input. The
dataType,layout,maxSeqLength,batchSize, andseqLengthArraymust match that ofyDesc. The parametervectorSizemust match theinputSizeargument passed to the cudnnSetRNNDescriptor_v8() function.xInput. Data pointer to the GPU memory associated with the RNN data descriptor
xDesc. The vectors are expected to be arranged in memory according to the layout specified byxDesc. The elements in the tensor (including padding vectors) must be densely packed.yDescInput. A previously initialized RNN data descriptor. The
dataType,layout,maxSeqLength,batchSize, andseqLengthArraymust match that ofxDesc. The parametervectorSizedepends on whether LSTM projection is enabled and whether the network is bidirectional. Specifically:For unidirectional models, the parameter
vectorSizemust match thehiddenSizeargument passed to cudnnSetRNNDescriptor_v8(). If the LSTM projection is enabled, thevectorSizemust be the same as theprojSizeargument passed to cudnnSetRNNDescriptor_v8().For bidirectional models, if the RNN
cellModeisCUDNN_LSTMand the projection feature is enabled, the parametervectorSizemust be 2x theprojSizeargument passed to cudnnSetRNNDescriptor_v8(). Otherwise, it should be 2x thehiddenSizevalue.
yOutput. Data pointer to the GPU memory associated with the RNN data descriptor
yDesc. The vectors are expected to be laid out in memory according to the layout specified byyDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.hDescInput. A tensor descriptor specifying layouts of the initial or final hidden state buffers (hx, hy). Hidden state data must be fully packed. The first dimension of the tensor depends on the
dirModeargument passed to the cudnnSetRNNDescriptor_v8() function.If
dirModeisCUDNN_UNIDIRECTIONAL, then the first dimension should match thenumLayersargument passed to cudnnSetRNNDescriptor_v8().If
dirModeisCUDNN_BIDIRECTIONAL, then the first dimension should be double thenumLayersargument passed to cudnnSetRNNDescriptor_v8().
The second dimension must match the
batchSizeparameter described inxDesc. The third dimension depends on whether RNN mode isCUDNN_LSTMand whether the LSTM projection is enabled. Specifically:If RNN mode is
CUDNN_LSTMand LSTM projection is enabled, the third dimension must match theprojSizeargument.Otherwise, the third dimension must match the
hiddenSizeargument passed to the cudnnSetRNNDescriptor_v8() call used to initializernnDesc.
hxInput. Pointer to the GPU buffer with the RNN initial hidden state. Data dimensions are described by the
hDesctensor descriptor. If aNULLpointer is passed, the initial hidden state of the network will be initialized to zero.hyOutput. Pointer to the GPU buffer where the final RNN hidden state should be stored. Data dimensions are described by the
hDesctensor descriptor. If aNULLpointer is passed, the final hidden state of the network will not be saved.cDescInput. For LSTM networks only. This argument should be
NULLforRELU,TANH, orGRUcell types.cDescis a tensor descriptor specifying layouts of the initial or final cell state buffers (cx, cy) used byLSTM networks. Cell state data must be fully packed. The first dimension of the tensor depends on thedirModeargument passed to the cudnnSetRNNDescriptor_v8() call.If
dirModeisCUDNN_UNIDIRECTIONALthe first dimension should match thenumLayersargument passed to cudnnSetRNNDescriptor_v8().If
dirModeisCUDNN_BIDIRECTIONALthe first dimension should match double thenumLayersargument passed to cudnnSetRNNDescriptor_v8().
The second tensor dimension must match the
batchSizeparameter inxDesc. The third dimension must match thehiddenSizeargument passed to the cudnnSetRNNDescriptor_v8() call.cxInput. For LSTM networks only. Pointer to the GPU buffer with the initial LSTM state data. Data dimensions are described by the
cDesctensor descriptor. If aNULLpointer is passed, the initial cell state of the network will be initialized to zero.cyOutput. For LSTM networks only. Pointer to the GPU buffer where final LSTM state data should be stored. Data dimensions are described by the
cDesctensor descriptor. If aNULLpointer is passed, the final LSTM cell state will not be saved.weightSpaceSizeInput. Specifies the size in bytes of the provided weight space buffer.
weightSpaceInput. Address of the weight space buffer in GPU memory.
workSpaceSizeInput. Specifies the size in bytes of the provided workspace buffer.
workSpaceInput/Output. Address of the workspace buffer in GPU memory to store temporary data.
reserveSpaceSizeInput. Specifies the size in bytes of the reserve-space buffer.
reserveSpaceInput/Output. Address of the reserve-space buffer in GPU memory.
Returns
CUDNN_STATUS_SUCCESSNo errors were detected while processing API input arguments and launching GPU kernels.
CUDNN_STATUS_NOT_SUPPORTEDAt least one of the following conditions are met:
variable sequence length input is passed while
CUDNN_RNN_ALGO_PERSIST_STATIC,CUDNN_RNN_ALGO_PERSIST_DYNAMIC, orCUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_His specifiedCUDNN_RNN_ALGO_PERSIST_STATICorCUDNN_RNN_ALGO_PERSIST_DYNAMICis requested on pre-Pascal devicesthe ‘double’ floating point type is used for input/output and the
CUDNN_RNN_ALGO_PERSIST_STATICalgo
CUDNN_STATUS_BAD_PARAMAn invalid or incompatible input argument was encountered. Some examples include:
some input descriptors are
NULLat least one of the settings in
rnnDesc,xDesc,yDesc,hDesc, orcDescdescriptors is invalidweightSpaceSize,workSpaceSize, orreserveSpaceSizeis too small
CUDNN_STATUS_EXECUTION_FAILEDThe process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
CUDNN_STATUS_ALLOC_FAILEDThe function was unable to allocate CPU memory.
cudnnRNNGetClip_v8()#
This function has been deprecated in cuDNN 9.0; use cudnnRNNGetClip_v9() instead.
Retrieves the current LSTM cell clipping parameters, and stores them in the arguments provided. The user can assign NULL to any pointer except rnnDesc when the retrieved value is not needed. The function does not check the validity of retrieved parameters.
cudnnStatus_t cudnnRNNGetClip_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t *clipMode, cudnnNanPropagation_t *clipNanOpt, double *lclip, double *rclip);
Parameters
rnnDescInput. A previously initialized RNN descriptor.
clipModeOutput. Pointer to the location where the retrieved cudnnRNNClipMode_t value is stored. The
clipModecan beCUDNN_RNN_CLIP_NONEin which case no LSTM cell state clipping is being performed; orCUDNN_RNN_CLIP_MINMAX, in which case the cell state activation to other units are being clipped.clipNanOptOutput. Pointer to the location where the retrieved cudnnNanPropagation_t value is stored.
lclip,rclipOutput. Pointers to the location where the retrieved LSTM cell clipping range
[lclip, rclip]is stored.
Returns
CUDNN_STATUS_SUCCESSLSTM clipping parameters were successfully retrieved from the RNN descriptor.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found (
rnnDescwasNULL).
cudnnRNNGetClip_v9()#
Retrieves the current LSTM cell clipping parameters, and stores them in the arguments provided. The user can assign NULL to any pointer except rnnDesc when the retrieved value is not needed. The function does not check the validity of retrieved parameters.
cudnnStatus_t cudnnRNNGetClip_v9( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t *clipMode, double *lclip, double *rclip);
Parameters
rnnDescInput. A previously initialized RNN descriptor.
clipModeOutput. Pointer to the location where the retrieved cudnnRNNClipMode_t value is stored. The
clipModecan beCUDNN_RNN_CLIP_NONEin which case no LSTM cell state clipping is being performed; orCUDNN_RNN_CLIP_MINMAX, in which case the cell state activation to other units are being clipped.lclip,rclipOutput. Pointers to the location where the retrieved LSTM cell clipping range
[lclip, rclip]is stored.
Returns
CUDNN_STATUS_SUCCESSLSTM clipping parameters were successfully retrieved from the RNN descriptor.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found (
rnnDescwasNULL).
cudnnRNNSetClip_v8()#
This function has been deprecated in cuDNN 9.0; use cudnnRNNSetClip_v9() instead.
Sets the LSTM cell clipping mode. The LSTM clipping is disabled by default. When enabled, clipping is applied to all layers. This cudnnRNNSetClip_v8() function does not affect the work, reserve, and weight-space buffer sizes and may be called multiple times.
cudnnStatus_t cudnnRNNSetClip_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t clipMode, cudnnNanPropagation_t clipNanOpt, double lclip, double rclip);
Parameters
rnnDescInput. A previously initialized RNN descriptor.
clipModeInput. Enables or disables the LSTM cell clipping. When
clipModeis set toCUDNN_RNN_CLIP_NONEno LSTM cell state clipping is performed. WhenclipModeisCUDNN_RNN_CLIP_MINMAXthe cell state activation to other units is clipped.clipNanOptInput. When set to
CUDNN_PROPAGATE_NAN(see the description for cudnnNanPropagation_t),NaNis propagated from the LSTM cell, or it can be set to one of the clipping range boundary values, instead of propagating.lclip,rclipInput. The range
[lclip, rclip]to which the LSTM cell clipping should be set.
Returns
CUDNN_STATUS_SUCCESSThe function completed successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found, for example:
rnnDescwasNULLlclip>rclipeither
lcliporrclipisNaN
cudnnRNNSetClip_v9()#
Sets the LSTM cell clipping mode. The LSTM clipping is disabled by default. When enabled, clipping is applied to all layers. This cudnnRNNSetClip_v8() function does not affect the work, reserve, and weight-space buffer sizes and may be called multiple times.
cudnnStatus_t cudnnRNNSetClip_v9( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t clipMode, double lclip, double rclip);
Parameters
rnnDescInput. A previously initialized RNN descriptor.
clipModeInput. Enables or disables the LSTM cell clipping. When
clipModeis set toCUDNN_RNN_CLIP_NONEno LSTM cell state clipping is performed. WhenclipModeisCUDNN_RNN_CLIP_MINMAXthe cell state activation to other units is clipped.lclip,rclipInput. The range
[lclip, rclip]to which the LSTM cell clipping should be set.
Returns
CUDNN_STATUS_SUCCESSThe function completed successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found, for example:
rnnDescwasNULLlclip>rclipeither
lcliporrclipisNaN
cudnnSetAttnDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function configures a multihead attention descriptor that was previously created using the cudnnCreateAttnDescriptor() function. The function sets attention parameters that are necessary to compute internal buffer sizes, dimensions of weight and bias tensors, or to select optimized code paths.
cudnnStatus_t cudnnSetAttnDescriptor( cudnnAttnDescriptor_t attnDesc, unsigned attnMode, int nHeads, double smScaler, cudnnDataType_t dataType, cudnnDataType_t computePrec, cudnnMathType_t mathType, cudnnDropoutDescriptor_t attnDropoutDesc, cudnnDropoutDescriptor_t postDropoutDesc, int qSize, int kSize, int vSize, int qProjSize, int kProjSize, int vProjSize, int oProjSize, int qoMaxSeqLength, int kvMaxSeqLength, int maxBatchSize, int maxBeamSize);
Input sequence data descriptors in cudnnMultiHeadAttnForward(), cudnnMultiHeadAttnBackwardData(), and cudnnMultiHeadAttnBackwardWeights() functions are checked against the configuration parameters stored in the attention descriptor. Some parameters must match exactly while max arguments such as maxBatchSize or qoMaxSeqLength establish upper limits for the corresponding dimensions.
The multihead attention model can be described by the following equations:
\(\textbf{h}_{i}=\left( \textbf{W}_{V,i} \textbf{V}\right)softmax\left( smScaler\left( \textbf{K}^{\textbf{T}}\mathrm{\textbf{W}}_{K,i}^{T} \right)\left( \textbf{W}_{Q,i} \textbf{q}\right) \right), for i=0 \cdots nHeads -1\)
\(MultiHeadAttn\left( \textbf{q},\textbf{K},\textbf{V},\textbf{W}_{Q},\textbf{W}_{K},\textbf{W}_{V},\textbf{W}_{O} \right)=\sum_{i=0}^{nHeads-1}\textbf{W}_{O,i}\textbf{h}_{i}\)
Where:
nHeadsis the number of independent attention heads that evaluate h i vectorsq is a primary input, a single query column vector
K, V are two matrices of
keyandvaluecolumn vectors
The lengths of query, key, and value vectors are defined by the qSize, kSize, and vSize arguments respectively.
For simplicity, the above equations are presented using a single embedding vector q but the cuDNN API can handle multiple q candidates in the beam search scheme, process q vectors from multiple sequences bundled into a batch, or automatically iterate through all embedding vectors (time-steps) of a sequence. Thus, in general, q, K, V inputs are tensors with additional pieces of information such as the active length of each sequence or how unused padding vectors should be saved.
In some publications, W O,i matrices are combined into one output projection matrix and h i vectors are merged explicitly into a single vector. This is an equivalent notation. In the cuDNN library, W O,i matrices are conceptually treated the same way as W Q,i, W K,i, or W V,i input projection weights. Refer to the description of the cudnnGetMultiHeadAttnWeights() function for more details.
Weight matrices W Q,i, W K,i, W V,i, and W O,i play similar roles, adjusting vector lengths in q, K, V inputs and in the multihead attention final output. The user can disable any or all projections by setting qProjSize, kProjSize, vProjSize, or oProjSize arguments to zero.
Embedding vector sizes in q, K, V and the vector lengths after projections need to be selected in such a way that matrix multiplications described above are feasible. Otherwise, CUDNN_STATUS_BAD_PARAM is returned by the cudnnSetAttnDescriptor() function. All four weight matrices are used when it is desirable to maintain rank deficiency \(\textbf{W}_{KQ,i}=\mathrm{\textbf{W}}_{K,i}^{T}\textbf{W}_{Q,i}\) or \(\textbf{W}_{OV,i}=\textbf{W}_{O,i}\textbf{W}_{V,i}\) of matrices to eliminate one or more dimensions during linear transformations in each head. This is a form of feature extraction. In such cases, the projected sizes are smaller than the original vector lengths.
For each attention head, weight matrix sizes are defined as follows:
W Q,i - size
[qProjSize x qSize],i = 0 .. nHeads-1W K,i - size
[kProjSize x kSize],i = 0 .. nHeads-1,kProjSize=qProjSizeW V,i - size
[vProjSize x vSize],i = 0 .. nHeads-1W O,i - size
[oProjSize x (vProjSize > 0 ? vProjSize : vSize)],i = 0 .. nHeads-1
When the output projection is disabled (oProjSize=0), the output vector length is nHeads * (vProjSize > 0 ? vProjSize : vSize), meaning, the output is a concatenation of all h i vectors. In the alternative interpretation, a concatenated matrix W O = [W O,0, W O,1, W O,2, …] forms the identity matrix.
Softmax is a normalized, exponential vector function that takes and outputs vectors of the same size. The multihead attention API utilizes softmax of the CUDNN_SOFTMAX_ACCURATE type to reduce the likelihood of the floating-point overflow.
The smScaler parameter is the softmax sharpening/smoothing coefficient. When smScaler=1.0, softmax uses the natural exponential function exp(x) or 2.7183*. When smScaler<1.0, for example smScaler=0.2, the function used by the softmax block will not grow as fast because exp(0.2*x) ≈ 1.2214 x.
The smScaler parameter can be adjusted to process larger ranges of values fed to softmax. When the range is too large (or smScaler is not sufficiently small for the given range), the output vector of the softmax block becomes categorical, meaning, one vector element is close to 1.0 and other outputs are zero or very close to zero. When this occurs, the Jacobian matrix of the softmax block is also close to zero so deltas are not back-propagated during training from output to input except through residual connections, if these connections are enabled. The user can set smScaler to any positive floating-point value or even zero. The smScaler parameter is not trainable.
The qoMaxSeqLength, kvMaxSeqLength, maxBatchSize, and maxBeamSize arguments declare the maximum sequence lengths, maximum batch size, and maximum beam size respectively, in the cudnnSeqDataDescriptor_t containers. The actual dimensions supplied to forward and backward (gradient) API functions should not exceed the max limits. The max arguments should be set carefully because too large values will result in excessive memory usage due to oversized work and reserve space buffers.
The attnMode argument is treated as a binary mask where various on/off options are set. These options can affect the internal buffer sizes, enforce certain argument checks, select optimized code execution paths, or enable attention variants that do not require additional numerical arguments. An example of such options is the inclusion of biases in input and output projections.
The attnDropoutDesc and postDropoutDesc arguments are descriptors that define two dropout layers active in the training mode. The first dropout operation defined by attnDropoutDesc, is applied directly to the softmax output. The second dropout operation, specified by postDropoutDesc, alters the multihead attention output, just before the point where residual connections are added.
Note
The
cudnnSetAttnDescriptor()function performs a shallow copy ofattnDropoutDescandpostDropoutDesc, meaning, the addresses of both dropout descriptors are stored in the attention descriptor and not the entire structure. Therefore, the user should keep dropout descriptors during the entire life of the attention descriptor.
Parameters
attnDescOutput. Attention descriptor to be configured.
attnModeInput. Enables various attention options that do not require additional numerical values. Refer to the table below for the list of supported flags. The user should assign a preferred set of bitwise
OR-edflags to this argument.nHeadsInput. Number of attention heads.
smScalerInput. Softmax smoothing (
1.0 >= smScaler >= 0.0) or sharpening (smScaler > 1.0) coefficient. Negative values are not accepted.dataTypeInput. Data type used to represent attention inputs, attention weights and attention outputs.
computePrecInput.Compute precision.
mathTypeInput. NVIDIA Tensor Core settings.
attnDropoutDescInput. Descriptor of the dropout operation applied to the softmax output. Refer to the table below for a list of unsupported features.
postDropoutDescInput. Descriptor of the dropout operation applied to the multihead attention output, just before the point where residual connections are added. Refer to the table below for a list of unsupported features.
qSize,kSize,vSizeInput. Q, K, V embedding vector lengths.
qProjSize,kProjSize,vProjSizeInput. Q, K, V embedding vector lengths after input projections. Use zero to disable the corresponding projection.
oProjSizeInput. The h i vector length after the output projection. Use zero to disable this projection.
qoMaxSeqLengthInput. Largest sequence length expected in sequence data descriptors related to Q, O, dQ, and dO inputs and outputs.
kvMaxSeqLengthInput. Largest sequence length expected in sequence data descriptors related to K, V, dK, and dV inputs and outputs.
maxBatchSizeInput. Largest batch size expected in any cudnnSeqDataDescriptor_t container.
maxBeamSizeInput. Largest beam size expected in any cudnnSeqDataDescriptor_t container.
Supported ``attnMode`` Flags
CUDNN_ATTN_QUERYMAP_ALL_TO_ONEForward declaration of mapping between Q and K, V vectors when the beam size is greater than one in the Q input. Multiple Q vectors from the same beam bundle map to the same K, V vectors. This means that beam sizes in the K, V sets are equal to one.
CUDNN_ATTN_QUERYMAP_ONE_TO_ONEForward declaration of mapping between Q and K, V vectors when the beam size is greater than one in the Q input. Multiple Q vectors from the same beam bundle map to different K, V vectors. This requires beam sizes in K, V sets to be the same as in the Q input.
CUDNN_ATTN_DISABLE_PROJ_BIASESUse no biases in the attention input and output projections.
CUDNN_ATTN_ENABLE_PROJ_BIASESUse extra biases in the attention input and output projections. In this case the projected \(\bar{\textbf{K}}\) vectors are computed as \(\bar{\textbf{K}}_{i}=\textbf{W}_{K,i}\textbf{K}+\textbf{b}\ast \left[ 1,1,\cdots ,1 \right]_{1xn}\), where n is the number of columns in the K matrix. In other words, the same column vector b is added to all columns of K after the weight matrix multiplication.
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
Unsupported Features
The
paddingFillargument in cudnnSeqDataDescriptor_t is currently ignored by all multihead attention functions.
Returns
CUDNN_STATUS_SUCCESSThe attention descriptor was configured successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was encountered. Some examples include:
post projection Q and K sizes were not equal
dataType,computePrec, ormathTypewere invalidone or more of the following arguments were either negative or zero:
nHeads,qSize,kSize,vSize,qoMaxSeqLength,kvMaxSeqLength,maxBatchSize,maxBeamSizeone or more of the following arguments were negative:
qProjSize,kProjSize,vProjSize,smScaler
CUDNN_STATUS_NOT_SUPPORTEDA requested option or a combination of input arguments is not supported.
cudnnSetCTCLossDescriptor()#
This function has been deprecated in cuDNN 9.0; use cudnnSetCTCLossDescriptor_v9() instead.
This function sets a CTC loss function descriptor. Refer to the extended version cudnnSetCTCLossDescriptorEx() to set the input normalization mode.
cudnnStatus_t cudnnSetCTCLossDescriptor( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType)
When the extended version cudnnSetCTCLossDescriptorEx() is used with normMode set to CUDNN_LOSS_NORMALIZATION_NONE and the gradMode set to CUDNN_NOT_PROPAGATE_NAN, then it is the same as the current function cudnnSetCTCLossDescriptor(), meaning:
cudnnSetCtcLossDescriptor(*) = cudnnSetCtcLossDescriptorEx(*, normMode=CUDNN_LOSS_NORMALIZATION_NONE, gradMode=CUDNN_NOT_PROPAGATE_NAN)
Parameters
ctcLossDescOutput. CTC loss descriptor to be set.
compTypeInput. Compute type for this CTC loss function.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the input parameters passed is invalid.
cudnnSetCTCLossDescriptor_v8()#
This function has been deprecated in cuDNN 9.0; use cudnnSetCTCLossDescriptor_v9() instead.
Many CTC API functions are updated in v8 to support CUDA graphs. In order to do so, a new parameter is needed, maxLabelLength. Now that label and input data are assumed to be in GPU memory, this information is not otherwise readily available.
cudnnStatus_t cudnnSetCTCLossDescriptor_v8( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType, cudnnLossNormalizationMode_t normMode, cudnnNanPropagation_t gradMode, int maxLabelLength)
Parameters
ctcLossDescOutput. CTC loss descriptor to be set.
compTypeInput. Compute type for this CTC loss function.
normModeInput. Input normalization type for this CTC loss function. For more information, refer to cudnnLossNormalizationMode_t.
gradModeInput.
NaNpropagation type for this CTC loss function. ForLthe sequence length,Rthe number of repeated letters in the sequence, andTthe length of sequential data, the following applies: when a sample withL+R > Tis encountered during the gradient calculation, ifgradModeis set toCUDNN_PROPAGATE_NAN(refer to cudnnNanPropagation_t), then the CTC loss function does not write to the gradient buffer for that sample. Instead, the current values, even not finite, are retained. IfgradModeis set toCUDNN_NOT_PROPAGATE_NAN, then the gradient for that sample is set to zero. This guarantees a finite gradient.maxLabelLengthInput. The maximum label length from the labels data.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the input parameters passed is invalid.
cudnnSetCTCLossDescriptor_v9()#
This function sets a CTC loss function descriptor.
cudnnStatus_t cudnnSetCTCLossDescriptor_v9( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType, cudnnLossNormalizationMode_t normMode, cudnnCTCGradMode_t ctcGradMode, int maxLabelLength)
Parameters
ctcLossDescOutput. CTC loss descriptor to be set.
compTypeInput. Compute type for this CTC loss function.
normModeInput. Input normalization type for this CTC loss function. For more information, refer to cudnnLossNormalizationMode_t.
ctcGradModeBehavior for out of boundary (OOB) samples. OOB samples are samples where L+R > T is encountered during the gradient calculation.
If
ctcGradModeis set toCUDNN_CTC_SKIP_OOB_GRADIENTS, then the CTC loss function does not write to the gradient buffer for that sample. Instead, the current values, even not finite, are retained.If
ctcGradModeis set toCUDNN_CTC_ZERO_OOB_GRADIENTS, then the gradient for that sample is set to zero. This guarantees a finite gradient.
maxLabelLengthInput. The maximum label length from the labels data.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the input parameters passed is invalid.
cudnnSetCTCLossDescriptorEx()#
This function has been deprecated in cuDNN 9.0; use cudnnSetCTCLossDescriptor_v9() instead.
This function is an extension of cudnnSetCTCLossDescriptor(). This function provides an additional interface normMode to set the input normalization mode for the CTC loss function, and gradMode to control the NaN propagation type.
cudnnStatus_t cudnnSetCTCLossDescriptorEx( cudnnCTCLossDescriptor_t ctcLossDesc, cudnnDataType_t compType, cudnnLossNormalizationMode_t normMode, cudnnNanPropagation_t gradMode)
When this function cudnnSetCTCLossDescriptorEx() is used with normMode set to CUDNN_LOSS_NORMALIZATION_NONE and the gradMode set to CUDNN_NOT_PROPAGATE_NAN, then it is the same as cudnnSetCTCLossDescriptor(), meaning:
cudnnSetCtcLossDescriptor(*) = cudnnSetCtcLossDescriptorEx(*, normMode=CUDNN_LOSS_NORMALIZATION_NONE, gradMode=CUDNN_NOT_PROPAGATE_NAN)
Parameters
ctcLossDescOutput. CTC loss descriptor to be set.
compTypeInput. Compute type for this CTC loss function.
normModeInput. Input normalization type for this CTC loss function. For more information, refer to cudnnLossNormalizationMode_t.
gradModeInput. NaN propagation type for this CTC loss function. For
Lthe sequence length,Rthe number of repeated letters in the sequence, andTthe length of sequential data, the following applies: when a sample withL+R > Tis encountered during the gradient calculation, ifgradModeis set toCUDNN_PROPAGATE_NAN(refer to cudnnNanPropagation_t), then the CTC loss function does not write to the gradient buffer for that sample. Instead, the current values, even not finite, are retained. IfgradModeis set toCUDNN_NOT_PROPAGATE_NAN, then the gradient for that sample is set to zero. This guarantees a finite gradient.
Returns
CUDNN_STATUS_SUCCESSThe function returned successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the input parameters passed is invalid.
cudnnSetRNNDataDescriptor()#
This function initializes a previously created RNN data descriptor object. This data structure is intended to support the unpacked (padded) layout for input and output of extended RNN inference and training functions. A packed (unpadded) layout is also supported for backward compatibility.
cudnnStatus_t cudnnSetRNNDataDescriptor( cudnnRNNDataDescriptor_t RNNDataDesc, cudnnDataType_t dataType, cudnnRNNDataLayout_t layout, int maxSeqLength, int batchSize, int vectorSize, const int seqLengthArray[], void *paddingFill);
Parameters
RNNDataDescInput/Output. A previously created RNN descriptor. For more information, refer to cudnnRNNDataDescriptor_t.
dataTypeInput. The datatype of the RNN data tensor. For more information, refer to cudnnDataType_t.
layoutInput. The memory layout of the RNN data tensor.
maxSeqLengthInput. The maximum sequence length within this RNN data tensor. In the unpacked (padded) layout, this should include the padding vectors in each sequence. In the packed (unpadded) layout, this should be equal to the greatest element in
seqLengthArray.batchSizeInput. The number of sequences within the mini-batch.
vectorSizeInput. The vector length (embedding size) of the input or output tensor at each time-step.
seqLengthArrayInput. An integer array with
batchSizenumber of elements. Describes the length (number of time-steps) of each sequence. Each element inseqLengthArraymust be greater than or equal to 0 but less than or equal tomaxSeqLength. In the packed layout, the elements should be sorted in descending order, similar to the layout required by the non-extended RNN compute functions.paddingFillInput. A user-defined symbol for filling the padding position in RNN output. This is only effective when the descriptor is describing the RNN output, and the unpacked layout is specified. The symbol should be in the host memory, and is interpreted as the same data type as that of the RNN data tensor. If a
NULLpointer is passed in, then the padding position in the output will be undefined.
Returns
CUDNN_STATUS_SUCCESSThe object was set successfully.
CUDNN_STATUS_NOT_SUPPORTEDAny one of these have occurred:
dataTypeis not one ofCUDNN_DATA_HALF,CUDNN_DATA_FLOAT,CUDNN_DATA_DOUBLE.maxSeqLengthis larger than 65535 (0xffff).
CUDNN_STATUS_BAD_PARAMAny one of these have occurred:
RNNDataDescisNULL.Any one of
maxSeqLength,batchSize, orvectorSizeis less than or equal to zero.An element of
seqLengthArrayis less than zero or greater thanmaxSeqLength.Layout is not one of
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED,CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED, orCUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED.
CUDNN_STATUS_ALLOC_FAILEDThe allocation of internal array storage has failed.
cudnnSetRNNDescriptor_v8()#
This function initializes a previously created RNN descriptor object. The RNN descriptor configured by cudnnSetRNNDescriptor_v8() was enhanced to store all information needed to compute the total number of adjustable weights/biases in the RNN model.
cudnnStatus_t cudnnSetRNNDescriptor_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNAlgo_t algo, cudnnRNNMode_t cellMode, cudnnRNNBiasMode_t biasMode, cudnnDirectionMode_t dirMode, cudnnRNNInputMode_t inputMode, cudnnDataType_t dataType, cudnnDataType_t mathPrec, cudnnMathType_t mathType, int32_t inputSize, int32_t hiddenSize, int32_t projSize, int32_t numLayers, cudnnDropoutDescriptor_t dropoutDesc, uint32_t auxFlags);
Parameters
rnnDescInput. A previously initialized RNN descriptor.
algoInput. RNN algo (
CUDNN_RNN_ALGO_STANDARD,CUDNN_RNN_ALGO_PERSIST_STATIC,CUDNN_RNN_ALGO_PERSIST_DYNAMIC, orCUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H).cellModeInput. Specifies the RNN cell type in the entire model (
CUDNN_RNN_RELU,CUDNN_RNN_TANH,CUDNN_RNN_LSTM,CUDNN_RNN_GRU).biasModeInput. Sets the number of bias vectors (
CUDNN_RNN_NO_BIAS,CUDNN_RNN_SINGLE_INP_BIAS,CUDNN_RNN_SINGLE_REC_BIAS,CUDNN_RNN_DOUBLE_BIAS). The two single bias settings are functionally the same forRELU,TANH, andLSTMcell types. For differences in GRU cells, refer to the description ofCUDNN_GRUin the cudnnRNNMode_t enumerated type.CUDNN_RNN_ALGO_STANDARDaccepts all bias modes. The remaining RNN algorithms work withCUDNN_RNN_DOUBLE_BIASonly.dirModeInput. Specifies the recurrence pattern:
CUDNN_UNIDIRECTIONALorCUDNN_BIDIRECTIONAL. In bidirectional RNNs, the hidden states passed between physical layers are concatenations of forward and backward hidden states.inputModeInput. Specifies how the input to the RNN model is processed by the first layer. When
inputModeisCUDNN_LINEAR_INPUT, original input vectors of sizeinputSizeare multiplied by the weight matrix to obtain vectors ofhiddenSize. WheninputModeisCUDNN_SKIP_INPUT, the original input vectors to the first layer are used as is without multiplying them by the weight matrix.dataTypeInput. Specifies data type for RNN weights/biases and input and output data.
mathPrecInput. This parameter is used to control the compute math precision in the RNN model. The following applies:
For the input/output in FP16, the parameter
mathPreccan beCUDNN_DATA_HALForCUDNN_DATA_FLOAT.For the input/output in FP32, the parameter
mathPreccan only beCUDNN_DATA_FLOAT.For the input/output in FP64, double type, the parameter
mathPreccan only beCUDNN_DATA_DOUBLE.
mathTypeInput. Sets the preferred option to use NVIDIA Tensor Cores accelerators on Volta (SM 7.0) or higher GPUs.
When
dataTypeisCUDNN_DATA_HALF, themathTypeparameter can beCUDNN_DEFAULT_MATHorCUDNN_TENSOR_OP_MATH. TheALLOW_CONVERSIONsetting is treated the same asCUDNN_TENSOR_OP_MATHfor this data type.When
dataTypeisCUDNN_DATA_FLOAT, themathTypeparameter can beCUDNN_DEFAULT_MATHorCUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION. When the latter settings are used, original weights and intermediate results will be down-converted toCUDNN_DATA_HALFbefore they are used in another recursive iteration.When
dataTypeisCUDNN_DATA_DOUBLE, themathTypeparameter can beCUDNN_DEFAULT_MATH.
This option has an advisory status meaning Tensor Cores may not be always utilized, for example, due to specific GEMM dimensions restrictions.
inputSizeInput. Size of the input vector in the RNN model. When the
inputMode=CUDNN_SKIP_INPUT, theinputSizeshould match thehiddenSizevalue.hiddenSizeInput. Size of the hidden state vector in the RNN model. The same hidden size is used in all RNN layers.
projSizeInput. The size of the LSTM cell output after the recurrent projection. When the LSTM projection is enabled, this value should be smaller than
hiddenSize. When the LSTM projection is disabled, and for all other RNN cell types (CUDNN_RNN_RELU,CUDNN_RNN_TANH, andCUDNN_RNN_GRU),projSizemust be equal tohiddenSize. The recurrent projection is an additional matrix multiplication in the LSTM cell to project (compress) hidden state vectors h t into smaller vectors r t = W r h t, where W r is a rectangular matrix withprojSizerows andhiddenSizecolumns. When the recurrent projection is enabled, the output of the LSTM cell (both to the next layer and unrolled in-time) is r t instead of h t. The recurrent projection can be enabled for LSTM cells andCUDNN_RNN_ALGO_STANDARDonly.numLayersInput. Number of stacked, physical layers in the deep RNN model. When
dirMode= CUDNN_BIDIRECTIONAL, the physical layer consists of two pseudo-layers corresponding to forward and backward directions.dropoutDescInput. Handle to a previously created and initialized dropout descriptor. Dropout operation will be applied between physical layers. A single layer network will have no dropout applied. Dropout is used in the training mode only.
auxFlagsInput. This argument is used to pass miscellaneous switches that do not require additional numerical values to configure the corresponding feature. In future cuDNN releases, this parameter will be used to extend the RNN functionality without adding new API functions (applicable options should be bitwise
OR-ed). Currently, this parameter is used to enable or disable padded input/output (CUDNN_RNN_PADDED_IO_DISABLED,CUDNN_RNN_PADDED_IO_ENABLED). When the padded I/O is enabled, layoutsCUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKEDandCUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKEDare permitted in RNN data descriptors.
Returns
CUDNN_STATUS_SUCCESSThe RNN descriptor was configured successfully.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was detected.
CUDNN_STATUS_NOT_SUPPORTEDAn incompatible or unsupported combination of input arguments was detected.
cudnnSetSeqDataDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function initializes a previously created sequence data descriptor object. In the most simplified view, this descriptor defines dimensions (dimA) and the data layout (axes) of a four-dimensional tensor.
cudnnStatus_t cudnnSetSeqDataDescriptor( cudnnSeqDataDescriptor_t seqDataDesc, cudnnDataType_t dataType, int nbDims, const int dimA[], const cudnnSeqDataAxis_t axes[], size_t seqLengthArraySize, const int seqLengthArray[], void *paddingFill);
All four dimensions of the sequence data descriptor have unique identifiers that can be used to index the dimA[] array:
CUDNN_SEQDATA_TIME_DIM CUDNN_SEQDATA_BATCH_DIM CUDNN_SEQDATA_BEAM_DIM CUDNN_SEQDATA_VECT_DIM
For example, to express information that vectors in our sequence data buffer are five elements long, we need to assign dimA[CUDNN_SEQDATA_VECT_DIM]=5 in the dimA[] array.
The number of active dimensions in the dimA[] and axes[] arrays is defined by the nbDims argument. Currently, the value of this argument should be four. The actual size of the dimA[] and axes[] arrays should be declared using the CUDNN_SEQDATA_DIM_COUNT macro.
The cudnnSeqDataDescriptor_t container is treated as a collection of fixed length vectors that form sequences, similarly to words (vectors of characters) constructing sentences. The TIME dimension spans the sequence length. Different sequences are bundled together in a batch. A BATCH may be a group of individual sequences or beams. A BEAM is a cluster of alternative sequences or candidates. When thinking about the beam, consider a translation task from one language to another. You may want to keep around and experiment with several translated versions of the original sentence before selecting the best one. The number of candidates kept around is the BEAM size.
Every sequence can have a different length, even within the same beam, so vectors toward the end of the sequence can be just padding. The paddingFill argument specifies how the padding vectors should be written in output sequence data buffers. The paddingFill argument points to one value of type dataType that should be copied to all elements in padding vectors. Currently, the only supported value for paddingFill is NULL which means this option should be ignored. In this case, elements of the padding vectors in output buffers will have undefined values.
It is assumed that a non-empty sequence always starts from the time index zero. The seqLengthArray[] must specify all sequence lengths in the container so the total size of this array should be dimA[CUDNN_SEQDATA_BATCH_DIM] * dimA[CUDNN_SEQDATA_BEAM_DIM]. Each element of the seqLengthArray[] array should have a non-negative value, less than or equal to dimA[CUDNN_SEQDATA_TIME_DIM]; the maximum sequence length. Elements in seqLengthArray[] are always arranged in the same batch-major order, meaning, when considering BEAM and BATCH dimensions, BATCH is the outer or the slower changing index when we traverse the array in ascending order of the addresses. Using a simple example, the seqLengthArray[] array should hold sequence lengths in the following order:
{batch_idx=0, beam_idx=0} {batch_idx=0, beam_idx=1} {batch_idx=1, beam_idx=0} {batch_idx=1, beam_idx=1} {batch_idx=2, beam_idx=0} {batch_idx=2, beam_idx=1}
When dimA[CUDNN_SEQDATA_BATCH_DIM]=3 and dimA[CUDNN_SEQDATA_BEAM_DIM]=2.
Data stored in the cudnnSeqDataDescriptor_t container must comply with the following constraints:
All data is fully packed. There are no unused spaces or gaps between individual vector elements or consecutive vectors.
The most inner dimension of the container is the vector. In other words, the first contiguous group of
dimA[CUDNN_SEQDATA_VECT_DIM]elements belongs to the first vector, followed by elements of the second vector, and so on.
The axes argument in the cudnnSeqDataDescriptor_t function is a bit more complicated. This array should have the same capacity as dimA[]. The axes[] array specifies the actual data layout in the GPU memory. In this function, the layout is described in the following way: as we move from one element of a vector to another in memory by incrementing the element pointer, what is the order of VECT, TIME, BATCH, and BEAM dimensions that we encounter. Let us assume that we want to define the following data layout:
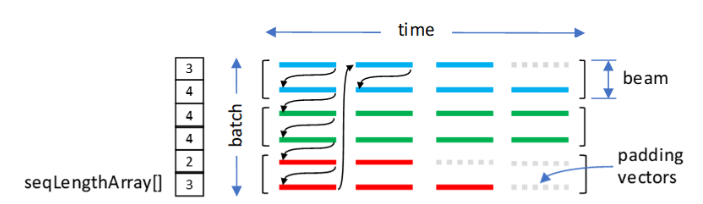
That corresponds to tensor dimensions:
int dimA[CUDNN_SEQDATA_DIM_COUNT]; dimA[CUDNN_SEQDATA_TIME_DIM] = 4; dimA[CUDNN_SEQDATA_BATCH_DIM] = 3; dimA[CUDNN_SEQDATA_BEAM_DIM] = 2; dimA[CUDNN_SEQDATA_VECT_DIM] = 5;
Now, let’s initialize the axes[] array. Note that the most inner dimension is described by the last active element of axes[]. There is only one valid configuration here as we always traverse a full vector first. Thus, we need to write CUDNN_SEQDATA_VECT_DIM in the last active element of axes[].
cudnnSeqDataAxis_t axes[CUDNN_SEQDATA_DIM_COUNT]; axes[3] = CUDNN_SEQDATA_VECT_DIM; // 3 = nbDims-1
Now, let’s work on the remaining three elements of axes[]. When we reach the end of the first vector, we jump to the next BEAM, therefore:
axes[2] = CUDNN_SEQDATA_BEAM_DIM;
When we approach the end of the second vector, we move to the next batch, therefore:
axes[1] = CUDNN_SEQDATA_BATCH_DIM;
The last (outermost) dimension is TIME:
axes[0] = CUDNN_SEQDATA_TIME_DIM;
The four values of the axes[] array fully describe the data layout depicted in the figure.
The sequence data descriptor allows the user to select 3! = 6 different data layouts or permutations of BEAM, BATCH, and TIME dimensions. The multihead attention API supports all six layouts.
Parameters
seqDataDescOutput. Pointer to a previously created sequence data descriptor.
dataTypeInput. Data type of the sequence data buffer (
CUDNN_DATA_HALF,CUDNN_DATA_FLOAT, orCUDNN_DATA_DOUBLE).nbDimsInput. Must be 4. The number of active dimensions in
dimA[]andaxes[]arrays. Both arrays should be declared to contain at leastCUDNN_SEQDATA_DIM_COUNTelements.dimA[]Input. Integer array specifying sequence data dimensions. Use the cudnnSeqDataAxis_t enumerated type to index all active
dimA[]elements.axes[]Input. Array of cudnnSeqDataAxis_t that defines the layout of sequence data in memory. The first
nbDimselements ofaxes[]should be initialized with the outermost dimension inaxes[0]and the innermost dimension inaxes[nbDims-1].seqLengthArraySizeInput. Number of elements in the sequence length array,
seqLengthArray[].seqLengthArray[]Input. An integer array that defines all sequence lengths of the container.
paddingFillInput. Must be
NULL. Pointer to a value ofdataTypethat is used to fill up output vectors beyond the valid length of each sequence orNULLto ignore this setting.
Returns
CUDNN_STATUS_SUCCESSAll input arguments were validated and the sequence data descriptor was successfully updated.
CUDNN_STATUS_BAD_PARAMAn invalid input argument was found. Some examples include:
seqDataDesc=NULLdateTypewas not a valid type of cudnnDataType_tnbDimswas negative or zeroseqLengthArraySizedid not match the expected lengthsome elements of
seqLengthArray[]were invalid
CUDNN_STATUS_NOT_SUPPORTEDAn unsupported input argument was encountered. Some examples include:
nbDimsis not equal to 4paddingFillis notNULL
CUDNN_STATUS_ALLOC_FAILEDFailed to allocate storage for the sequence data descriptor object.