cudnn_cnn Library#
Data Type References#
These are the data type references in the cudnn_cnn library.
Struct Types#
These are the struct types in the cudnn_cnn library.
cudnnConvolutionBwdDataAlgoPerf_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnConvolutionBwdDataAlgoPerf_t is a structure containing performance results returned by cudnnFindConvolutionBackwardDataAlgorithm() or heuristic results returned by cudnnGetConvolutionBackwardDataAlgorithm_v7().
Data Members
cudnnConvolutionBwdDataAlgo_t algoThe algorithm runs to obtain the associated performance metrics.
cudnnStatus_t statusIf any error occurs during the workspace allocation or timing of cudnnConvolutionBackwardData(), this status will represent that error. Otherwise, this status will be the return status of cudnnConvolutionBackwardData().
CUDNN_STATUS_ALLOC_FAILEDif any error occurred during workspace allocation or if the provided workspace is insufficient.CUDNN_STATUS_INTERNAL_ERRORif any error occurred during timing calculations or workspace deallocation.Otherwise, this will be the return status of cudnnConvolutionBackwardData().
float timeThe execution time of cudnnConvolutionBackwardData() (in milliseconds).
size_t memoryThe workspace size (in bytes).
cudnnDeterminism_t determinismThe determinism of the algorithm.
cudnnMathType_t mathTypeThe math type provided to the algorithm.
int reserved[3]Reserved space for future properties.
cudnnConvolutionBwdFilterAlgoPerf_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnConvolutionBwdFilterAlgoPerf_t is a structure containing performance results returned by cudnnFindConvolutionBackwardFilterAlgorithm() or heuristic results returned by cudnnGetConvolutionBackwardFilterAlgorithm_v7().
Data Members
cudnnConvolutionBwdFilterAlgo_t algoThe algorithm runs to obtain the associated performance metrics.
cudnnStatus_t statusIf any error occurs during the workspace allocation or timing of cudnnConvolutionBackwardFilter(), this status will represent that error. Otherwise, this status will be the return status of cudnnConvolutionBackwardFilter().
CUDNN_STATUS_ALLOC_FAILEDif any error occurred during workspace allocation or if the provided workspace is insufficient.CUDNN_STATUS_INTERNAL_ERRORif any error occurred during timing calculations or workspace deallocation.Otherwise, this will be the return status of cudnnConvolutionBackwardFilter().
float timeThe execution time of cudnnConvolutionBackwardFilter() (in milliseconds).
size_t memoryThe workspace size (in bytes).
cudnnDeterminism_t determinismThe determinism of the algorithm.
cudnnMathType_t mathTypeThe math type provided to the algorithm.
int reserved[3]Reserved space for future properties.
cudnnConvolutionFwdAlgoPerf_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnConvolutionFwdAlgoPerf_t is a structure containing performance results returned by cudnnFindConvolutionForwardAlgorithm() or heuristic results returned by cudnnGetConvolutionForwardAlgorithm_v7().
Data Members
cudnnConvolutionFwdAlgo_t algoThe algorithm runs to obtain the associated performance metrics.
cudnnStatus_t statusIf any error occurs during the workspace allocation or timing of cudnnConvolutionForward(), this status will represent that error. Otherwise, this status will be the return status of cudnnConvolutionForward().
CUDNN_STATUS_ALLOC_FAILEDif any error occurred during workspace allocation or if the provided workspace is insufficient.CUDNN_STATUS_INTERNAL_ERRORif any error occurred during timing calculations or workspace deallocation.Otherwise, this will be the return status of cudnnConvolutionForward().
float timeThe execution time of cudnnConvolutionForward() (in milliseconds).
size_t memoryThe workspace size (in bytes).
cudnnDeterminism_t determinismThe determinism of the algorithm.
cudnnMathType_t mathTypeThe math type provided to the algorithm.
int reserved[3]Reserved space for future properties.
Pointer To Opaque Struct Types#
These are the pointers to the opaque struct types in the cudnn_cnn library.
cudnnConvolutionDescriptor_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnConvolutionDescriptor_t is a pointer to an opaque structure holding the description of a convolution operation. cudnnCreateConvolutionDescriptor() is used to create one instance, and cudnnSetConvolutionNdDescriptor() or cudnnSetConvolution2dDescriptor() must be used to initialize this instance.
cudnnFusedOpsConstParamPack_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnFusedOpsConstParamPack_t is a pointer to an opaque structure holding the description of the cudnnFusedOps constant parameters. Use the function cudnnCreateFusedOpsConstParamPack() to create one instance of this structure, and the function cudnnDestroyFusedOpsConstParamPack() to destroy a previously-created descriptor.
cudnnFusedOpsPlan_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnFusedOpsPlan_t is a pointer to an opaque structure holding the description of the cudnnFusedOpsPlan. This descriptor contains the plan information, including the problem type and size, which kernels should be run, and the internal workspace partition. Use the function cudnnCreateFusedOpsPlan() to create one instance of this structure, and the function cudnnDestroyFusedOpsPlan() to destroy a previously-created descriptor.
cudnnFusedOpsVariantParamPack_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnFusedOpsVariantParamPack_t is a pointer to an opaque structure holding the description of the cudnnFusedOps variant parameters. Use the function cudnnCreateFusedOpsVariantParamPack() to create one instance of this structure, and the function cudnnDestroyFusedOpsVariantParamPack() to destroy a previously-created descriptor.
Enumeration Types#
These are the enumeration types in the cudnn_cnn library.
cudnnFusedOps_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
The cudnnFusedOps_t type is an enumerated type to select a specific sequence of computations to perform in the fused operations.
Members and Descriptions
CUDNN_FUSED_SCALE_BIAS_ACTIVATION_CONV_BNSTATS = 0On a per-channel basis, it performs these operations in this order:
scale,add bias,activation,convolution, and generatebatchNormstatistics.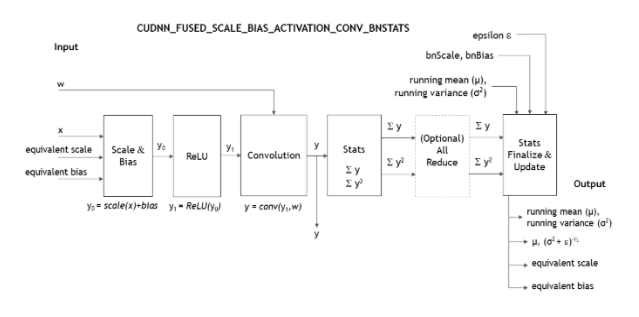
CUDNN_FUSED_SCALE_BIAS_ACTIVATION_WGRAD = 1On a per-channel basis, it performs these operations in this order:
scale,add bias,activation, convolution backward weights, and generatebatchNormstatistics.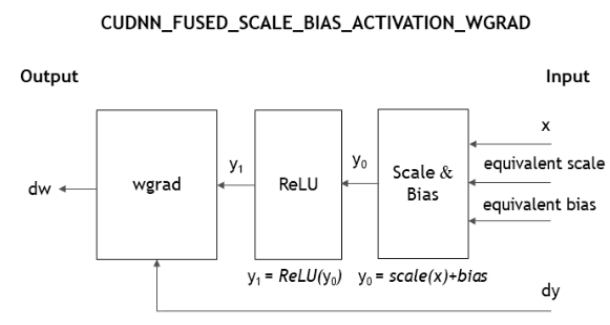
CUDNN_FUSED_BN_FINALIZE_STATISTICS_TRAINING = 2Computes the equivalent
scaleandbiasfromySum,ySqSum, learnedscale, andbias. Optionally, update running statistics and generate saved stats.CUDNN_FUSED_BN_FINALIZE_STATISTICS_INFERENCE = 3Computes the equivalent
scaleandbiasfrom the learned running statistics and the learnedscaleandbias.CUDNN_FUSED_CONV_SCALE_BIAS_ADD_ACTIVATION = 4On a per-channel basis, performs these operations in this order:
convolution,scale,add bias, element-wise addition with another tensor, andactivation.CUDNN_FUSED_SCALE_BIAS_ADD_ACTIVATION_GEN_BITMASK = 5On a per-channel basis, performs these operations in this order:
scaleandbiason one tensor,scaleandbiason a second tensor, element-wise addition of these two tensors, and on the resulting tensor performsactivationand generates activation bit mask.CUDNN_FUSED_DACTIVATION_FORK_DBATCHNORM = 6On a per-channel basis, performs these operations in this order: backward activation, fork (meaning, write out gradient for the residual branch), and backward batch norm.
cudnnFusedOpsConstParamLabel_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
The cudnnFusedOpsConstParamLabel_t is an enumerated type for the selection of the type of the cudnnFusedOps descriptor. For more information, refer to cudnnSetFusedOpsConstParamPackAttribute().
typedef enum { CUDNN_PARAM_XDESC = 0, CUDNN_PARAM_XDATA_PLACEHOLDER = 1, CUDNN_PARAM_BN_MODE = 2, CUDNN_PARAM_BN_EQSCALEBIAS_DESC = 3, CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER = 4, CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER = 5, CUDNN_PARAM_ACTIVATION_DESC = 6, CUDNN_PARAM_CONV_DESC = 7, CUDNN_PARAM_WDESC = 8, CUDNN_PARAM_WDATA_PLACEHOLDER = 9, CUDNN_PARAM_DWDESC = 10, CUDNN_PARAM_DWDATA_PLACEHOLDER = 11, CUDNN_PARAM_YDESC = 12, CUDNN_PARAM_YDATA_PLACEHOLDER = 13, CUDNN_PARAM_DYDESC = 14, CUDNN_PARAM_DYDATA_PLACEHOLDER = 15, CUDNN_PARAM_YSTATS_DESC = 16, CUDNN_PARAM_YSUM_PLACEHOLDER = 17, CUDNN_PARAM_YSQSUM_PLACEHOLDER = 18, CUDNN_PARAM_BN_SCALEBIAS_MEANVAR_DESC = 19, CUDNN_PARAM_BN_SCALE_PLACEHOLDER = 20, CUDNN_PARAM_BN_BIAS_PLACEHOLDER = 21, CUDNN_PARAM_BN_SAVED_MEAN_PLACEHOLDER = 22, CUDNN_PARAM_BN_SAVED_INVSTD_PLACEHOLDER = 23, CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER = 24, CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER = 25, CUDNN_PARAM_ZDESC = 26, CUDNN_PARAM_ZDATA_PLACEHOLDER = 27, CUDNN_PARAM_BN_Z_EQSCALEBIAS_DESC = 28, CUDNN_PARAM_BN_Z_EQSCALE_PLACEHOLDER = 29, CUDNN_PARAM_BN_Z_EQBIAS_PLACEHOLDER = 30, CUDNN_PARAM_ACTIVATION_BITMASK_DESC = 31, CUDNN_PARAM_ACTIVATION_BITMASK_PLACEHOLDER = 32, CUDNN_PARAM_DXDESC = 33, CUDNN_PARAM_DXDATA_PLACEHOLDER = 34, CUDNN_PARAM_DZDESC = 35, CUDNN_PARAM_DZDATA_PLACEHOLDER = 36, CUDNN_PARAM_BN_DSCALE_PLACEHOLDER = 37, CUDNN_PARAM_BN_DBIAS_PLACEHOLDER = 38, } cudnnFusedOpsConstParamLabel_t;
Short-Form Used |
Stands For |
|---|---|
Setter |
|
Getter |
|
|
|
|
Stands for |
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
Description |
Default Value After Creation |
|---|---|---|---|
|
In the setter, the |
Tensor descriptor describing the size, layout, and datatype of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes the mode of operation for the scale, bias and the statistics. As of cuDNN 7.6.0, only |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and datatype of the batchNorm equivalent scale and bias tensors. The shapes must match the mode specified in |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes the activation operation. As of 7.6.0, only activation modes of |
|
|
In the setter, the |
Describes the convolution operation. |
|
|
In the setter, the |
Filter descriptor describing the size, layout and datatype of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Tensor descriptor describing the size, layout and datatype of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Tensor descriptor describing the size, layout and datatype of the sum of |
|
|
In the setter, the |
Describes whether sum of |
|
|
In the setter, the |
Describes whether sum of |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
As of cuDNN 7.6.0, if the following conditions in the table are met, then the fully fused fast path will be triggered. Otherwise, a slower partially fused path will be triggered.
Parameter |
Condition |
|---|---|
Device compute capability |
Needs to be one of |
|
|
|
|
|
|
|
|
|
|
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
Description |
Default Value After Creation |
|---|---|---|---|
|
In the setter, the |
Tensor descriptor describing the size, layout, and datatype of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes the mode of operation for the scale, bias and the statistics. As of cuDNN 7.6.0, only |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and datatype of the batchNorm equivalent scale and bias tensors. The shapes must match the mode specified in |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes the activation operation. As of 7.6.0, only activation modes of |
|
|
In the setter, the |
Describes the convolution operation. |
|
|
In the setter, the |
Filter descriptor describing the size, layout and datatype of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Tensor descriptor describing the size, layout and datatype of the |
|
|
In the setter, the |
Describes whether |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
As of cuDNN 7.6.0, if the following conditions in the table are met, then the fully fused fast path will be triggered. Otherwise, a slower partially fused path will be triggered.
Parameter |
Condition |
|---|---|
Device compute capability |
Needs to be one of |
|
|
|
|
|
|
|
|
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
Description |
Default Value After Creation |
|---|---|---|---|
|
In the setter, the |
Describes the mode of operation for the scale, bias and the statistics. As of cuDNN 7.6.0, only |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the sum of |
|
|
In the setter, the |
Describes whether sum of |
|
|
In the setter, the |
Describes whether sum of |
|
|
In the setter, the |
A common tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes whether |
|
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
Description |
Default Value After Creation |
|---|---|---|---|
|
In the setter, the |
Describes the mode of operation for the scale, bias, and the statistics. As of cuDNN 7.6.0, only |
|
|
In the setter, the |
A common tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether the |
|
|
In the setter, the |
Describes whether the |
|
The following operation performs the computation, where \(*\) denotes convolution operator: \(y=\alpha_{1}\left( w*x \right)+\alpha_{2}z+b\)
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
Description |
Default Value After Creation |
|---|---|---|---|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes the convolution operation. |
|
|
In the setter, the |
Filter descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the \(\alpha_{1}\) scale and bias tensors. The tensor should have shape (1,K,1,1), K is the number of output features. |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the \(\alpha_{2}\) tensor. If set to |
|
|
In the setter, the |
Describes whether |
|
|
In the setter, the |
Describes the activation operation. As of 7.6.0, only activation modes of |
|
|
In the setter, the |
Tensor descriptor describing the size, layout, and data type of the |
|
|
In the setter, the |
Describes whether |
|
cudnnFusedOpsPointerPlaceHolder_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
cudnnFusedOpsPointerPlaceHolder_t is an enumerated type used to select the alignment type of the cudnnFusedOps descriptor pointer.
Members and Descriptions
CUDNN_PTR_NULL = 0Indicates that the pointer to the tensor in the
variantPackwill beNULL.CUDNN_PTR_ELEM_ALIGNED = 1Indicates that the pointer to the tensor in the
variantPackwill not beNULL, and will have element alignment.CUDNN_PTR_16B_ALIGNED = 2Indicates that the pointer to the tensor in the
variantPackwill not beNULL, and will have 16 byte alignment.
cudnnFusedOpsVariantParamLabel_t#
This enumerated type is deprecated and is currently only used by deprecated APIs. Consider using replacements for the deprecated APIs that use this enumerated type.
The cudnnFusedOpsVariantParamLabel_t is an enumerated type that is used to set the buffer pointers. These buffer pointers can be changed in each iteration.
typedef enum { CUDNN_PTR_XDATA = 0, CUDNN_PTR_BN_EQSCALE = 1, CUDNN_PTR_BN_EQBIAS = 2, CUDNN_PTR_WDATA = 3, CUDNN_PTR_DWDATA = 4, CUDNN_PTR_YDATA = 5, CUDNN_PTR_DYDATA = 6, CUDNN_PTR_YSUM = 7, CUDNN_PTR_YSQSUM = 8, CUDNN_PTR_WORKSPACE = 9, CUDNN_PTR_BN_SCALE = 10, CUDNN_PTR_BN_BIAS = 11, CUDNN_PTR_BN_SAVED_MEAN = 12, CUDNN_PTR_BN_SAVED_INVSTD = 13, CUDNN_PTR_BN_RUNNING_MEAN = 14, CUDNN_PTR_BN_RUNNING_VAR = 15, CUDNN_PTR_ZDATA = 16, CUDNN_PTR_BN_Z_EQSCALE = 17, CUDNN_PTR_BN_Z_EQBIAS = 18, CUDNN_PTR_ACTIVATION_BITMASK = 19, CUDNN_PTR_DXDATA = 20, CUDNN_PTR_DZDATA = 21, CUDNN_PTR_BN_DSCALE = 22, CUDNN_PTR_BN_DBIAS = 23, CUDNN_SCALAR_SIZE_T_WORKSPACE_SIZE_IN_BYTES = 100, CUDNN_SCALAR_INT64_T_BN_ACCUMULATION_COUNT = 101, CUDNN_SCALAR_DOUBLE_BN_EXP_AVG_FACTOR = 102, CUDNN_SCALAR_DOUBLE_BN_EPSILON = 103, } cudnnFusedOpsVariantParamLabel_t;
Short-Form Used |
Stands For |
|---|---|
Setter |
|
Getter |
|
|
Stands for |
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
I/O Type |
Description |
Default Value |
|---|---|---|---|---|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to sum of |
|
|
|
input |
Pointer to sum of |
|
|
|
input |
Pointer to user allocated workspace on device. Can be |
|
|
|
input |
Pointer to a |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
I/O Type |
Description |
Default Value |
|---|---|---|---|---|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
output |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to user allocated workspace on device. Can be |
|
|
|
input |
Pointer to a |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
I/O Type |
Description |
Default Value |
|---|---|---|---|---|
|
|
input |
Pointer to sum of |
|
|
|
input |
Pointer to sum of |
|
|
|
input |
Pointer to sum of |
|
|
|
input |
Pointer to sum of |
|
|
|
output |
Pointer to sum of |
|
|
|
output |
Pointer to sum of |
|
|
|
input/output |
Pointer to sum of |
|
|
|
input/output |
Pointer to sum of |
|
|
|
output |
Pointer to |
|
|
|
output |
Pointer to |
|
|
|
input |
Pointer to a scalar value in |
|
|
|
input |
Pointer to a scalar value in double on host memory. Factor used in the moving average computation. Refer to |
|
|
|
input |
Pointer to a scalar value in double on host memory. A conditioning constant used in the batch normalization formula. Its value should be equal to or greater than the value defined for |
|
|
|
input |
Pointer to user allocated workspace on device. Can be |
|
|
|
input |
Pointer to a |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
I/O Type |
Description |
Default Value |
|---|---|---|---|---|
|
|
input |
Pointer to sum of |
|
|
|
input |
Pointer to sum of |
|
|
|
input/output |
Pointer to sum of |
|
|
|
input/output |
Pointer to sum of |
|
|
|
output |
Pointer to |
|
|
|
output |
Pointer to |
|
|
|
input |
Pointer to a scalar value in double on host memory. A conditioning constant used in the batch normalization formula. Its value should be equal to or greater than the value defined for |
|
|
|
input |
Pointer to user allocated workspace on device. Can be |
|
|
|
input |
Pointer to a |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
Attribute Key |
Expected Descriptor Type Passed in, in the Setter |
I/O Type |
Description |
Default Value |
|---|---|---|---|---|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
input |
Pointer to |
|
|
|
output |
Pointer to |
|
|
|
input |
Pointer to user allocated workspace on device. Can be |
|
|
|
input |
Pointer to a |
|
Note
If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_NULL, then the device pointer in theVariantParamPackneeds to beNULLas well.If the corresponding pointer placeholder in
ConstParamPackis set toCUDNN_PTR_ELEM_ALIGNEDorCUDNN_PTR_16B_ALIGNED, then the device pointer in theVariantParamPackmay not beNULLand need to be at least element-aligned or 16 bytes-aligned, respectively.
API Functions#
These are the API functions in the cudnn_cnn library.
cudnnCnnVersionCheck()#
Cross-library version checker. Each sublibrary has a version checker that checks whether its own version matches that of its dependencies.
Returns
CUDNN_STATUS_SUCCESSThe version check passed.
CUDNN_STATUS_SUBLIBRARY_VERSION_MISMATCHThe versions are inconsistent.
cudnnConvolutionBackwardBias()#
This function has been deprecated in cuDNN 9.0.
This function computes the convolution function gradient with respect to the bias, which is the sum of every element belonging to the same feature map across all of the images of the input tensor. Therefore, the number of elements produced is equal to the number of features maps of the input tensor.
cudnnStatus_t cudnnConvolutionBackwardBias( cudnnHandle_t handle, const void *alpha, const cudnnTensorDescriptor_t dyDesc, const void *dy, const void *beta, const cudnnTensorDescriptor_t dbDesc, void *db)
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
alpha,betaInput. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
dyDescInput. Handle to the previously initialized input tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
dyInput. Data pointer to GPU memory associated with the tensor descriptor
dyDesc.dbDescInput. Handle to the previously initialized output tensor descriptor.
dbOutput. Data pointer to GPU memory associated with the output tensor descriptor
dbDesc.
Returns
CUDNN_STATUS_SUCCESSThe operation was launched successfully.
CUDNN_STATUS_NOT_SUPPORTEDThe function does not support the provided configuration.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
One of the parameters
n,height, orwidthof the output tensor is not1.The numbers of feature maps of the input tensor and output tensor differ.
The
dataTypeof the two tensor descriptors is different.
cudnnConvolutionBackwardData()#
This function has been deprecated in cuDNN 9.0.
This function computes the convolution data gradient of the tensor dy, where y is the output of the forward convolution in cudnnConvolutionForward(). It uses the specified algo, and returns the results in the output tensor dx. Scaling factors alpha and beta can be used to scale the computed result or accumulate with the current dx.
cudnnStatus_t cudnnConvolutionBackwardData( cudnnHandle_t handle, const void *alpha, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionBwdDataAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *beta, const cudnnTensorDescriptor_t dxDesc, void *dx)
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
alpha,betaInput. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
wDescInput. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
wInput. Data pointer to GPU memory associated with the filter descriptor
wDesc.dyDescInput. Handle to the previously initialized input differential tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
dyInput. Data pointer to GPU memory associated with the input differential tensor descriptor
dyDesc.convDescInput. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
algoInput. Enumerant that specifies which backward data convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionBwdDataAlgo_t.
workSpaceInput. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be
NIL.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.dxDescInput. Handle to the previously initialized output tensor descriptor.
dxInput/Output. Data pointer to GPU memory associated with the output tensor descriptor
dxDescthat carries the result.
Supported Configurations
This function supports the following combinations of data types for wDesc, dyDesc, convDesc, and dxDesc.
Data Type Configurations |
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Supported Algorithms
Specifying a separate algorithm can cause changes in performance, support and computation determinism. Refer to the following list of algorithm options, and their respective supported parameters and deterministic behavior.
The table below shows the list of the supported 2D and 3D convolutions. The 2D convolutions are described first, followed by the 3D convolutions.
For brevity, the short-form versions followed by > are used in the table below:
CUDNN_CONVOLUTION_BWD_DATA_ALGO_0>_ALGO_0
CUDNN_CONVOLUTION_BWD_DATA_ALGO_1>_ALGO_1
CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT>_FFT
CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT_TILING>_FFT_TILING
CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD>_WINOGRAD
CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD_NONFUSED>_WINOGRAD_NONFUSED
CUDNN_TENSOR_NCHW>_NCHW
CUDNN_TENSOR_NHWC>_NHWC
CUDNN_TENSOR_NCHW_VECT_C>_NCHW_VECT_C
Algo Name |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
NHWC HWC-packed |
NHWC HWC-packed |
|
Algo Name |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
No |
NCHW CHW-packed |
All except |
|
Dilation: Greater than |
|
Yes |
NCHW CHW-packed |
All except |
|
Dilation: Greater than |
|
Yes |
NCHW CHW-packed |
NCHW HW-packed |
|
Dilation: |
|
Yes |
NCHW CHW-packed |
NCHW HW-packed |
|
Dilation: |
|
Yes |
NCHW CHW-packed |
All except |
|
Dilation: |
|
Yes |
NCHW CHW-packed |
All except |
|
Dilation: |
Algo Name (3D Convolutions) |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
Yes |
NCDHW CDHW-packed |
All except |
|
Dilation: Greater than |
|
Yes |
NCDHW CDHW-packed |
NCDHW CDHW-packed |
|
Dilation: |
|
Yes |
NCDHW CDHW-packed |
NCDHW DHW-packed |
|
Dilation: |
Algo Name (3D Convolutions) |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
Yes |
NDHWC DHWC-packed |
NDHWC DHWC-packed |
|
Dilation: Greater than |
Returns
CUDNN_STATUS_SUCCESSThe operation was launched successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
At least one of the following is
NULL: handle,dyDesc,wDesc,convDesc,dxDesc,dy,w,dx,alpha, andbetawDescanddyDeschave a non-matching number of dimensionswDescanddxDeschave a non-matching number of dimensionswDeschas fewer than three number of dimensionswDesc,dxDesc, anddyDeschave a non-matching data typewDescanddxDeschave a non-matching number of input feature maps per image (or group in case of grouped convolutions)dyDescspatial sizes do not match with the expected size as determined by cudnnGetConvolutionNdForwardOutputDim()
CUDNN_STATUS_NOT_SUPPORTEDAt least one of the following conditions are met:
dyDescordxDeschave a negative tensor stridingdyDesc,wDesc, ordxDeschas a number of dimensions that is not4or5The chosen algo does not support the parameters provided; refer to the above tables for an exhaustive list of parameters that support each algo.
dyDescorwDescindicate an output channel count that isn’t a multiple of group count (if group count has been set inconvDesc)
CUDNN_STATUS_MAPPING_ERRORAn error occurs during the texture binding of texture object creation associated with the filter data or the input differential tensor data.
CUDNN_STATUS_EXECUTION_FAILEDThe function failed to launch on the GPU.
cudnnConvolutionBackwardFilter()#
This function has been deprecated in cuDNN 9.0.
This function computes the convolution weight (filter) gradient of the tensor dy, where y is the output of the forward convolution in cudnnConvolutionForward(). It uses the specified algo, and returns the results in the output tensor dw. Scaling factors alpha and beta can be used to scale the computed result or accumulate with the current dw.
cudnnStatus_t cudnnConvolutionBackwardFilter( cudnnHandle_t handle, const void *alpha, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionBwdFilterAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *beta, const cudnnFilterDescriptor_t dwDesc, void *dw)
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
alpha,betaInput. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
xDescInput. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
xInput. Data pointer to GPU memory associated with the tensor descriptor
xDesc.dyDescInput. Handle to the previously initialized input differential tensor descriptor.
dyInput. Data pointer to GPU memory associated with the backpropagation gradient tensor descriptor
dyDesc.convDescInput. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
algoInput. Enumerant that specifies which convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionBwdFilterAlgo_t.
workSpaceInput. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be
NIL.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.dwDescInput. Handle to a previously initialized filter gradient descriptor. For more information, refer to cudnnFilterDescriptor_t.
dwInput/Output. Data pointer to GPU memory associated with the filter gradient descriptor
dwDescthat carries the result.
Supported Configurations
This function supports the following combinations of data types for xDesc, dyDesc, convDesc, and dwDesc.
Data Type Configurations |
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Supported Algorithms
Specifying a separate algorithm can cause changes in performance, support, and computation determinism. Refer to the following table for an exhaustive list of algorithm options and their respective supported parameters and deterministic behavior.
The table below shows the list of the supported 2D and 3D convolutions. The 2D convolutions are described first, followed by the 3D convolutions.
For the following terms, the short-form versions shown in parentheses are used in the table below, for brevity:
For brevity, the short-form versions followed by > are used in the table below:
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0>_ALGO_0
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1>_ALGO_1
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_3>_ALGO_3
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT>_FFT
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT_TILING>_FFT_TILING
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_WINOGRAD_NONFUSED>_WINOGRAD_NONFUSED
CUDNN_TENSOR_NCHW>_NCHW
CUDNN_TENSOR_NHWC>_NHWC
CUDNN_TENSOR_NCHW_VECT_C>_NCHW_VECT_C
Algo Name |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
All except |
NHWC HWC-packed |
|
Algo Name |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
No |
All except |
NCHW CHW-packed |
|
Dilation: Greater than |
|
Yes |
All except |
NCHW CHW-packed |
|
Dilation: Greater than |
|
Yes |
NCHW CHW-packed |
NCHW CHW-packed |
|
Dilation: |
|
No |
All except |
NCHW CHW-packed |
|
Dilation: |
|
Yes |
All except |
NCHW CHW-packed |
|
Dilation: |
|
Yes |
NCHW CHW-packed |
NCHW CHW-packed |
|
Dilation: |
Algo Name (3D Convolutions) |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
No |
All except |
NCDHW CDHW-packed NCDHW W-packed NDHWC |
|
Dilation: Greater than |
|
No |
All except |
NCDHW CDHW-packed NCDHW W-packed NDHWC |
|
Dilation: Greater than |
|
No |
NCDHW fully-packed |
NCDHW fully-packed |
|
Dilation: Greater than |
Algo Name (3D Convolutions) |
Deterministic |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|---|
|
Yes |
NDHWC HWC-packed |
NDHWC HWC-packed |
|
Dilation: Greater than |
Returns
CUDNN_STATUS_SUCCESSThe operation was launched successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
At least one of the following is
NULL:handle,xDesc,dyDesc,convDesc,dwDesc,xData,dyData,dwData,alpha, orbetaxDescanddyDeschave a non-matching number of dimensionsxDescanddwDeschave a non-matching number of dimensionsxDeschas fewer than three number of dimensionsxDesc,dyDesc, anddwDeschave a non-matching data typexDescanddwDeschave a non-matching number of input feature maps per image (or group in case of grouped convolutions)yDescordwDescindicate an output channel count that isn’t a multiple of group count (if group count has been set in convDesc)
CUDNN_STATUS_NOT_SUPPORTEDAt least one of the following conditions are met:
xDescordyDeschave negative tensor stridingxDesc,dyDesc`,` or ``dwDeschas a number of dimensions that is not4or5The chosen
algodoes not support the parameters provided; see above for an exhaustive list of parameter support for eachalgo
CUDNN_STATUS_MAPPING_ERRORAn error occurs during the texture object creation associated with the filter data.
CUDNN_STATUS_EXECUTION_FAILEDThe function failed to launch on the GPU.
cudnnConvolutionBiasActivationForward()#
This function has been deprecated in cuDNN 9.0.
This function applies a bias and then an activation to the convolutions or cross-correlations of cudnnConvolutionForward(), returning results in y. The full computation follows the equation y = act (alpha1 * conv(x) + alpha2 * z + bias).
cudnnStatus_t cudnnConvolutionBiasActivationForward( cudnnHandle_t handle, const void *alpha1, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionFwdAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *alpha2, const cudnnTensorDescriptor_t zDesc, const void *z, const cudnnTensorDescriptor_t biasDesc, const void *bias, const cudnnActivationDescriptor_t activationDesc, const cudnnTensorDescriptor_t yDesc, void *y)
The routine cudnnGetConvolution2dForwardOutputDim() or cudnnGetConvolutionNdForwardOutputDim() can be used to determine the proper dimensions of the output tensor descriptor yDesc with respect to xDesc, convDesc, and wDesc.
Only the CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM algo is enabled with CUDNN_ACTIVATION_IDENTITY. In other words, in the cudnnActivationDescriptor_t structure of the input activationDesc, if the mode of the cudnnActivationMode_t field is set to the enum value CUDNN_ACTIVATION_IDENTITY, then the input cudnnConvolutionFwdAlgo_t of this function cudnnConvolutionBiasActivationForward() must be set to the enum value CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM. For more information, refer to cudnnSetActivationDescriptor().
Device pointer z and y may be pointing to the same buffer, however, x cannot point to the same buffer as z or y.
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
alpha1,alpha2Input. Pointers to scaling factors (in host memory) used to blend the computation result of convolution with
zand bias as follows:y = act (alpha1 * conv(x) + alpha2 * z + bias)
For more information, refer to Scaling Parameters.
xDescInput. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
xInput. Data pointer to GPU memory associated with the tensor descriptor
xDesc.wDescInput. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
wInput. Data pointer to GPU memory associated with the filter descriptor
wDesc.convDescInput. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
algoInput. Enumerant that specifies which convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionFwdAlgo_t.
workSpaceInput. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be
NIL.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.zDescInput. Handle to a previously initialized tensor descriptor.
zInput. Data pointer to GPU memory associated with the tensor descriptor zDesc.
biasDescInput. Handle to a previously initialized tensor descriptor.
biasInput. Data pointer to GPU memory associated with the tensor descriptor
biasDesc.activationDescInput. Handle to a previously initialized activation descriptor. For more information, refer to cudnnActivationDescriptor_t.
yDescInput. Handle to a previously initialized tensor descriptor.
yInput/Output. Data pointer to GPU memory associated with the tensor descriptor
yDescthat carries the result of the convolution.
For the convolution step, this function supports the specific combinations of data types for xDesc, wDesc, convDesc, and yDesc as listed in the documentation of cudnnConvolutionForward(). The following table specifies the supported combinations of data types for x, y, z, bias, alpha1, and alpha2.
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Returns
In addition to the error values listed by the documentation of cudnnConvolutionForward(), the possible error values returned by this function and their meanings are listed below.
CUDNN_STATUS_SUCCESSThe operation was launched successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
At least one of the following is
NULL: handle,xDesc,wDesc,convDesc,yDesc,zDesc,biasDesc,activationDesc,xData,wData,yData,zData,bias,alpha1, andalpha2.The number of dimensions of
xDesc,wDesc,yDesc, andzDescis not equal to the array length ofconvDesc+ 2.
CUDNN_STATUS_NOT_SUPPORTEDThe function does not support the provided configuration. Some examples of non-supported configurations include:
The
modeofactivationDescis notCUDNN_ACTIVATION_RELUorCUDNN_ACTIVATION_IDENTITY.The
reluNanOptofactivationDescis notCUDNN_NOT_PROPAGATE_NAN.The second stride of
biasDescis not equal to1.The first dimension of
biasDescis not equal to1.The second dimension of
biasDescand the first dimension offilterDescare not equal.The data type of
biasDescdoes not correspond to the data type ofyDescas listed in the above data type tables.zDescanddestDescdo not match.
CUDNN_STATUS_EXECUTION_FAILEDThe function failed to launch on the GPU.
cudnnConvolutionForward()#
This function has been deprecated in cuDNN 9.0.
This function executes convolutions or cross-correlations over x using filters specified with w, returning results in y. Scaling factors alpha and beta can be used to scale the input tensor and the output tensor respectively.
cudnnStatus_t cudnnConvolutionForward( cudnnHandle_t handle, const void *alpha, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnConvolutionDescriptor_t convDesc, cudnnConvolutionFwdAlgo_t algo, void *workSpace, size_t workSpaceSizeInBytes, const void *beta, const cudnnTensorDescriptor_t yDesc, void *y)
The routine cudnnGetConvolution2dForwardOutputDim() or cudnnGetConvolutionNdForwardOutputDim() can be used to determine the proper dimensions of the output tensor descriptor yDesc with respect to xDesc, convDesc, and wDesc.
Parameters
handleInput. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
alpha,betaInput. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
xDescInput. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
xInput. Data pointer to GPU memory associated with the tensor descriptor
xDesc.wDescInput. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
wInput. Data pointer to GPU memory associated with the filter descriptor
wDesc.convDescInput. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
algoInput. Enumerant that specifies which convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionFwdAlgo_t.
workSpaceInput. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be
NIL.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.yDescInput. Handle to a previously initialized tensor descriptor.
yInput/Output. Data pointer to GPU memory associated with the tensor descriptor
yDescthat carries the result of the convolution.
Supported Configurations
This function supports the following combinations of data types for xDesc, wDesc, convDesc, and yDesc.
Data Type Configurations |
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Supported Algorithms
For this function, all algorithms perform deterministic computations. Specifying a separate algorithm can cause changes in performance and support.
The following table shows the list of the supported 2D and 3D convolutions. The 2D convolutions are described first, followed by the 3D convolutions.
For brevity, the short-form versions followed by > are used in the table below:
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMM>_IMPLICIT_GEMM
CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM>_IMPLICIT_PRECOMP_GEMM
CUDNN_CONVOLUTION_FWD_ALGO_GEMM>_GEMM
CUDNN_CONVOLUTION_FWD_ALGO_DIRECT>_DIRECT
CUDNN_CONVOLUTION_FWD_ALGO_FFT>_FFT
CUDNN_CONVOLUTION_FWD_ALGO_FFT_TILING>_FFT_TILING
CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD>_WINOGRAD
CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED>_WINOGRAD_NONFUSED
CUDNN_TENSOR_NCHW>_NCHW
CUDNN_TENSOR_NHWC>_NHWC
CUDNN_TENSOR_NCHW_VECT_C>_NCHW_VECT_C
Algo Name |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|
|
All except |
All except |
|
Dilation: Greater than |
|
All except |
All except |
|
Dilation: |
|
All except |
All except |
|
Dilation: |
|
NCHW HW-packed |
NCHW HW-packed |
|
Dilation: |
|
NCHW HW-packed |
NCHW HW-packed |
|
Dilation: |
|
All except |
All except |
|
Dilation: |
|
All except |
All except |
|
Dilation: |
|
Currently, not implemented in cuDNN. |
Currently, not implemented in cuDNN. |
Currently, not implemented in cuDNN. |
Currently, not implemented in cuDNN. |
Algo Name |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|
|
All except |
All except |
|
Dilation: |
|
All except |
All except |
|
Dilation: |
Algo Name |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|
|
NHWC fully-packed |
NHWC fully-packed |
|
Dilation: |
|
NHWC HWC-packed |
NHWC HWC-packed NCHW CHW-packed |
|
|
Algo Name |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|
|
All except |
All except |
|
Dilation: Greater than |
|
NCDHW DHW-packed |
NCDHW DHW-packed |
|
Dilation: |
Algo Name |
Tensor Formats Supported for |
Tensor Formats Supported for |
Data Type Configurations Supported |
Important |
|---|---|---|---|---|
|
NDHWC DHWC-packed |
NDHWC DHWC-packed |
|
Dilation: Greater than |
Tensors can be converted to and from CUDNN_TENSOR_NCHW_VECT_C with cudnnTransformTensor().
Returns
CUDNN_STATUS_SUCCESSThe operation was launched successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
At least one of the following is
NULL:handle,xDesc,wDesc,convDesc,yDesc,xData,w,yData,alpha, andbetaxDescandyDeschave a non-matching number of dimensionsxDescandwDeschave a non-matching number of dimensionsxDeschas fewer than three number of dimensionsxDescnumber of dimensions is not equal toconvDescarray length + 2xDescandwDeschave a non-matching number of input feature maps per image (or group in case of grouped convolutions)yDescorwDescindicate an output channel count that isn’t a multiple of group count (if group count has been set inconvDesc)xDesc,wDesc, andyDeschave a non-matching data typeFor some spatial dimension,
wDeschas a spatial size that is larger than the input spatial size (including zero-padding size)
CUDNN_STATUS_NOT_SUPPORTEDAt least one of the following conditions are met:
xDescoryDeschave negative tensor stridingxDesc,wDesc, oryDeschas a number of dimensions that is not4or5yDescspatial sizes do not match with the expected size as determined by cudnnGetConvolutionNdForwardOutputDim()The chosen algo does not support the parameters provided; see above for an exhaustive list of parameters supported for each algo
CUDNN_STATUS_MAPPING_ERRORAn error occurs during the texture object creation associated with the filter data.
CUDNN_STATUS_EXECUTION_FAILEDThe function failed to launch on the GPU.
cudnnCreateConvolutionDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function creates a convolution descriptor object by allocating the memory needed to hold its opaque structure. For more information, refer to cudnnConvolutionDescriptor_t.
cudnnStatus_t cudnnCreateConvolutionDescriptor( cudnnConvolutionDescriptor_t *convDesc)
Returns
CUDNN_STATUS_SUCCESSThe object was created successfully.
CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
cudnnCreateFusedOpsConstParamPack()#
This function has been deprecated in cuDNN 9.0.
This function creates an opaque structure to store the various problem size information, such as the shape, layout and the type of tensors, and the descriptors for convolution and activation, for the selected sequence of cudnnFusedOps computations.
cudnnStatus_t cudnnCreateFusedOpsConstParamPack( cudnnFusedOpsConstParamPack_t *constPack, cudnnFusedOps_t ops);
Parameters
constPackInput. The opaque structure that is created by this function. For more information, refer to cudnnFusedOpsConstParamPack_t.
opsInput. The specific sequence of computations to perform in the
cudnnFusedOpscomputations, as defined in the enumerant type cudnnFusedOps_t.
Returns
CUDNN_STATUS_BAD_PARAMIf either
constPackoropsisNULL.CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
CUDNN_STATUS_SUCCESSIf the descriptor is created successfully.
cudnnCreateFusedOpsPlan()#
This function has been deprecated in cuDNN 9.0.
This function creates the plan descriptor for the cudnnFusedOps computation. This descriptor contains the plan information, including the problem type and size, which kernels should be run, and the internal workspace partition.
cudnnStatus_t cudnnCreateFusedOpsPlan( cudnnFusedOpsPlan_t *plan, cudnnFusedOps_t ops);
Parameters
planInput. A pointer to the instance of the descriptor created by this function.
opsInput. The specific sequence of fused operations computations for which this plan descriptor should be created. For more information, refer to cudnnFusedOps_t.
Returns
CUDNN_STATUS_BAD_PARAMIf either the input
*planisNULLor theopsinput is not a validcudnnFusedOpenum.CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
CUDNN_STATUS_SUCCESSThe plan descriptor is created successfully.
cudnnCreateFusedOpsVariantParamPack()#
This function has been deprecated in cuDNN 9.0.
This function creates the variant pack descriptor for the cudnnFusedOps computation.
cudnnStatus_t cudnnCreateFusedOpsVariantParamPack( cudnnFusedOpsVariantParamPack_t *varPack, cudnnFusedOps_t ops);
Parameters
varPackInput. Pointer to the descriptor created by this function. For more information, refer to cudnnFusedOpsVariantParamPack_t.
opsInput. The specific sequence of fused operations computations for which this descriptor should be created.
Returns
CUDNN_STATUS_SUCCESSThe descriptor was destroyed successfully.
CUDNN_STATUS_ALLOC_FAILEDThe resources could not be allocated.
CUDNN_STATUS_BAD_PARAMIf any input is invalid.
cudnnDestroyConvolutionDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function destroys a previously created convolution descriptor object.
cudnnStatus_t cudnnDestroyConvolutionDescriptor( cudnnConvolutionDescriptor_t convDesc)
Returns
CUDNN_STATUS_SUCCESSThe descriptor was destroyed successfully.
cudnnDestroyFusedOpsConstParamPack()#
This function has been deprecated in cuDNN 9.0.
This function destroys a previously-created cudnnFusedOpsConstParamPack_t structure.
cudnnStatus_t cudnnDestroyFusedOpsConstParamPack( cudnnFusedOpsConstParamPack_t constPack);
Parameters
constPackInput. The cudnnFusedOpsConstParamPack_t structure that should be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe descriptor was destroyed successfully.
CUDNN_STATUS_INTERNAL_ERRORThe
opsenum value is either not supported or is invalid.
cudnnDestroyFusedOpsPlan()#
This function has been deprecated in cuDNN 9.0.
This function destroys the plan descriptor provided.
cudnnStatus_t cudnnDestroyFusedOpsPlan( cudnnFusedOpsPlan_t plan);
Parameters
planInput. The descriptor that should be destroyed by this function.
Returns
CUDNN_STATUS_SUCCESSEither the plan descriptor is
NULLor the descriptor was successfully destroyed.
cudnnDestroyFusedOpsVariantParamPack()#
This function has been deprecated in cuDNN 9.0.
This function destroys a previously-created descriptor for cudnnFusedOps constant parameters.
cudnnStatus_t cudnnDestroyFusedOpsVariantParamPack( cudnnFusedOpsVariantParamPack_t varPack);
Parameters
varPackInput. The descriptor that should be destroyed.
Returns
CUDNN_STATUS_SUCCESSThe descriptor was successfully destroyed.
cudnnFindConvolutionBackwardDataAlgorithm()#
This function has been deprecated in cuDNN 9.0.
This function attempts all algorithms available for cudnnConvolutionBackwardData(). It will attempt both the provided convDesc mathType and CUDNN_DEFAULT_MATH (assuming the two differ).
cudnnStatus_t cudnnFindConvolutionBackwardDataAlgorithm( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdDataAlgoPerf_t *perfResults)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdDataAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardDataAlgorithmMaxCount().
Note
This function is host blocking.
It is recommended to run this function prior to allocating layer data; doing otherwise may needlessly inhibit some algorithm options due to resource usage.
Parameters
handleInput. Handle to a previously created cuDNN context.
wDescInput. Handle to a previously initialized filter descriptor.
dyDescInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dxDescInput. Handle to the previously initialized output tensor descriptor.
requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
handleis not allocated properlywDesc,dyDesc, ordxDescis not allocated properlywDesc,dyDesc, ordxDeschas fewer than1dimensionEither
returnedCountorperfResultsisNILrequestedCountis less than1
CUDNN_STATUS_ALLOC_FAILEDThis function was unable to allocate memory to store sample input, filters, and output.
CUDNN_STATUS_INTERNAL_ERRORAt least one of the following conditions are met:
The function was unable to allocate necessary timing objects
The function was unable to deallocate necessary timing objects
The function was unable to deallocate sample input, filters, and output
cudnnFindConvolutionBackwardDataAlgorithmEx()#
This function has been deprecated in cuDNN 9.0.
This function attempts all algorithms available for cudnnConvolutionBackwardData(). It will attempt both the provided convDesc mathType and CUDNN_DEFAULT_MATH (assuming the two differ).
cudnnStatus_t cudnnFindConvolutionBackwardDataAlgorithmEx( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, void *dx, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdDataAlgoPerf_t *perfResults, void *workSpace, size_t workSpaceSizeInBytes)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdDataAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardDataAlgorithmMaxCount().
Note
This function is host blocking.
Parameters
handleInput. Handle to a previously created cuDNN context.
wDescInput. Handle to a previously initialized filter descriptor.
wInput. Data pointer to GPU memory associated with the filter descriptor
wDesc.dyDescInput. Handle to the previously initialized input differential tensor descriptor.
dyInput. Data pointer to GPU memory associated with the filter descriptor
dyDesc.convDescInput. Previously initialized convolution descriptor.
dxDescInput. Handle to the previously initialized output tensor descriptor.
dxInput/Output. Data pointer to GPU memory associated with the tensor descriptor
dxDesc. The content of this tensor will be overwritten with arbitrary values.requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
workSpaceInput. Data pointer to GPU memory is a necessary workspace for some algorithms. The size of this workspace will determine the availability of algorithms. A
NILpointer is considered aworkSpaceof0bytes.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
handleis not allocated properlywDesc,dyDesc, ordxDescis not allocated properlywDesc,dyDesc, ordxDeschas fewer than1dimensionEither
returnedCountorperfResultsisNILrequestedCountis less than1
CUDNN_STATUS_INTERNAL_ERRORAt least one of the following conditions are met:
The function was unable to allocate necessary timing objects
The function was unable to deallocate necessary timing objects
The function was unable to deallocate sample input, filters, and output
cudnnFindConvolutionBackwardFilterAlgorithm()#
This function has been deprecated in cuDNN 9.0.
This function attempts all algorithms available for cudnnConvolutionBackwardFilter(). It will attempt both the provided convDesc mathType and CUDNN_DEFAULT_MATH (assuming the two differ).
cudnnStatus_t cudnnFindConvolutionBackwardFilterAlgorithm( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdFilterAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardFilterAlgorithmMaxCount().
Note
This function is host blocking.
It is recommended to run this function prior to allocating layer data; doing otherwise may needlessly inhibit some algorithm options due to resource usage.
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
dyDescInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dwDescInput. Handle to a previously initialized filter descriptor.
requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
handleis not allocated properlyxDesc,dyDesc, ordwDescare not allocated properlyxDesc,dyDesc, ordwDeschas fewer than1dimensionEither
returnedCountorperfResultsisNILrequestedCountis less than1
CUDNN_STATUS_ALLOC_FAILED
This function was unable to allocate memory to store sample input, filters and output.
CUDNN_STATUS_INTERNAL_ERROR
At least one of the following conditions are met:
The function was unable to allocate necessary timing objects.
The function was unable to deallocate necessary timing objects.
The function was unable to deallocate sample input, filters, and output.
cudnnFindConvolutionBackwardFilterAlgorithmEx()#
This function has been deprecated in cuDNN 9.0.
This function attempts all algorithms available for cudnnConvolutionBackwardFilter(). It will attempt both the provided convDesc mathType and CUDNN_DEFAULT_MATH (assuming the two differ).
cudnnStatus_t cudnnFindConvolutionBackwardFilterAlgorithmEx( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnTensorDescriptor_t dyDesc, const void *dy, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, void *dw, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults, void *workSpace, size_t workSpaceSizeInBytes)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdFilterAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardFilterAlgorithmMaxCount().
Note
This function is host blocking.
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
xInput. Data pointer to GPU memory associated with the filter descriptor
xDesc.dyDescInput. Handle to the previously initialized input differential tensor descriptor.
dyInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dwDescInput. Handle to a previously initialized filter descriptor.
dwInput/Output. Data pointer to GPU memory associated with the filter descriptor
dwDesc. The content of this tensor will be overwritten with arbitrary values.requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
workSpaceInput. Data pointer to GPU memory is a necessary workspace for some algorithms. The size of this workspace will determine the availability of algorithms. A
NILpointer is considered aworkSpaceof0bytes.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
handleis not allocated properlyxDesc,dyDesc, ordwDescare not allocated properlyxDesc,dyDesc, ordwDeschas fewer than1dimensionx,dy, ordwisNILEither
returnedCountorperfResultsisNILrequestedCountis less than1
CUDNN_STATUS_INTERNAL_ERROR
At least one of the following conditions are met:
The function was unable to allocate necessary timing objects.
The function was unable to deallocate necessary timing objects.
The function was unable to deallocate sample input, filters, and output.
cudnnFindConvolutionForwardAlgorithm()#
This function has been deprecated in cuDNN 9.0.
This function attempts all algorithms available for cudnnConvolutionForward(). It will attempt both the provided convDesc mathType and CUDNN_DEFAULT_MATH (assuming the two differ).
cudnnStatus_t cudnnFindConvolutionForwardAlgorithm( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionFwdAlgoPerf_t *perfResults)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionFwdAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionForwardAlgorithmMaxCount().
Note
This function is host blocking.
It is recommended to run this function prior to allocating layer data; doing otherwise may needlessly inhibit some algorithm options due to resource usage.
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
wDescInput. Handle to a previously initialized filter descriptor.
convDescInput. Previously initialized convolution descriptor.
yDescInput. Handle to the previously initialized output tensor descriptor.
requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
handleis not allocated properlyxDesc,dyDesc, ordwDescare not allocated properlyxDesc,dyDesc, ordwDeschas fewer than1dimensionEither
returnedCountorperfResultsisNILrequestedCountis less than1
CUDNN_STATUS_ALLOC_FAILEDThis function was unable to allocate memory to store sample input, filters, and output.
CUDNN_STATUS_INTERNAL_ERROR
At least one of the following conditions are met:
The function was unable to allocate necessary timing objects.
The function was unable to deallocate necessary timing objects.
The function was unable to deallocate sample input, filters, and output.
cudnnFindConvolutionForwardAlgorithmEx()#
This function has been deprecated in cuDNN 9.0.
This function attempts all algorithms available for cudnnConvolutionForward(). It will attempt both the provided convDesc mathType and CUDNN_DEFAULT_MATH (assuming the two differ).
cudnnStatus_t cudnnFindConvolutionForwardAlgorithmEx( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const void *x, const cudnnFilterDescriptor_t wDesc, const void *w, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, void *y, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionFwdAlgoPerf_t *perfResults, void *workSpace, size_t workSpaceSizeInBytes)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionFwdAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionForwardAlgorithmMaxCount().
Note
This function is host blocking.
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
xInput. Data pointer to GPU memory associated with the tensor descriptor
xDesc.wDescInput. Handle to a previously initialized filter descriptor.
wInput. Data pointer to GPU memory associated with the filter descriptor
wDesc.convDescInput. Previously initialized convolution descriptor.
yDescInput. Handle to the previously initialized output tensor descriptor.
yInput/Output. Data pointer to GPU memory associated with the tensor descriptor
yDesc. The content of this tensor will be overwritten with arbitrary values.requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
workSpaceInput. Data pointer to GPU memory is a necessary workspace for some algorithms. The size of this workspace will determine the availability of algorithms. A
NILpointer is considered aworkSpaceof0bytes.workSpaceSizeInBytesInput. Specifies the size in bytes of the provided
workSpace.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
handleis not allocated properlyxDesc,dyDesc, ordwDescare not allocated properlyxDesc,dyDesc, ordwDeschas fewer than1dimensionx,w, oryisNILEither
returnedCountorperfResultsisNILrequestedCountis less than1
CUDNN_STATUS_INTERNAL_ERROR
At least one of the following conditions are met:
The function was unable to allocate necessary timing objects.
The function was unable to deallocate necessary timing objects.
The function was unable to deallocate sample input, filters, and output.
cudnnFusedOpsExecute()#
This function executes the sequence of cudnnFusedOps operations.
cudnnStatus_t cudnnFusedOpsExecute( cudnnHandle_t handle, const cudnnFusedOpsPlan_t plan, cudnnFusedOpsVariantParamPack_t varPack);
Parameters
handleInput. Pointer to the cuDNN library context.
planInput. Pointer to a previously-created and initialized plan descriptor.
varPackInput. Pointer to the descriptor to the variant parameters pack.
Returns
CUDNN_STATUS_BAD_PARAMIf the type of cudnnFusedOps_t in the plan descriptor is unsupported.
cudnnGetConvolution2dDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function queries a previously initialized 2D convolution descriptor object.
cudnnStatus_t cudnnGetConvolution2dDescriptor( const cudnnConvolutionDescriptor_t convDesc, int *pad_h, int *pad_w, int *u, int *v, int *dilation_h, int *dilation_w, cudnnConvolutionMode_t *mode, cudnnDataType_t *computeType)
Parameters
convDescInput/Output. Handle to a previously created convolution descriptor.
pad_hOutput. Zero-padding height: number of rows of zeros implicitly concatenated onto the top and onto the bottom of input images.
pad_wOutput. Zero-padding width: number of columns of zeros implicitly concatenated onto the left and onto the right of input images.
uOutput. Vertical filter stride.
vOutput. Horizontal filter stride.
dilation_hOutput. Filter height dilation.
dilation_wOutput. Filter width dilation.
modeOutput. Convolution mode.
computeTypeOutput. Compute precision.
Returns
CUDNN_STATUS_SUCCESSThe operation was successful.
CUDNN_STATUS_BAD_PARAMThe parameter
convDescisNIL.
cudnnGetConvolution2dForwardOutputDim()#
This function has been deprecated in cuDNN 9.0.
This function returns the dimensions of the resulting 4D tensor of a 2D convolution, given the convolution descriptor, the input tensor descriptor and the filter descriptor. This function can help to set up the output tensor and allocate the proper amount of memory prior to launching the actual convolution.
cudnnStatus_t cudnnGetConvolution2dForwardOutputDim( const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t inputTensorDesc, const cudnnFilterDescriptor_t filterDesc, int *n, int *c, int *h, int *w)
Each dimension h and w of the output images is computed as follows:
outputDim = 1 + ( inputDim + 2*pad - (((filterDim-1)*dilation)+1) )/convolutionStride;Note
The dimensions provided by this routine must be strictly respected when calling cudnnConvolutionForward() or cudnnConvolutionBackwardBias(). Providing a smaller or larger output tensor is not supported by the convolution routines.
Parameters
convDescInput. Handle to a previously created convolution descriptor.
inputTensorDescInput. Handle to a previously initialized tensor descriptor.
filterDescInput. Handle to a previously initialized filter descriptor.
nOutput. Number of output images.
cOutput. Number of output feature maps per image.
hOutput. Height of each output feature map.
wOutput. Width of each output feature map.
Returns
CUDNN_STATUS_BAD_PARAMOne or more of the descriptors has not been created correctly or there is a mismatch between the feature maps of
inputTensorDescandfilterDesc.CUDNN_STATUS_SUCCESSThe object was set successfully.
cudnnGetConvolutionBackwardDataAlgorithm_v7()#
This function has been deprecated in cuDNN 9.0.
This function serves as a heuristic for obtaining the best suited algorithm for cudnnConvolutionBackwardData() for the given layer specifications. This function will return all algorithms (including CUDNN_TENSOR_OP_MATH and CUDNN_DEFAULT_MATH versions of algorithms where CUDNN_TENSOR_OP_MATH may be available) sorted by expected (based on internal heuristic) relative performance with the fastest being index 0 of perfResults. For an exhaustive search for the fastest algorithm, use cudnnFindConvolutionBackwardDataAlgorithm(). The total number of resulting algorithms can be queried through the returnedAlgoCount variable.
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithm_v7( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdDataAlgoPerf_t *perfResults)
Parameters
handleInput. Handle to a previously created cuDNN context.
wDescInput. Handle to a previously initialized filter descriptor.
dyDescInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dxDescInput. Handle to the previously initialized output tensor descriptor.
requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
One of the parameters
handle,wDesc,dyDesc,convDesc,dxDesc,perfResults, orreturnedAlgoCountisNULL.The numbers of feature maps of the input tensor and output tensor differ.
The
dataTypeof the two tensor descriptors or the filters are different.requestedAlgoCountis less than or equal to0.
cudnnGetConvolutionBackwardDataAlgorithmMaxCount()#
This function has been deprecated in cuDNN 9.0.
This function returns the maximum number of algorithms which can be returned from cudnnFindConvolutionBackwardDataAlgorithm() and cudnnGetConvolutionForwardAlgorithm_v7(). This is the sum of all algorithms plus the sum of all algorithms with Tensor Core operations supported for the current device.
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithmMaxCount( cudnnHandle_t handle, int *count)
Parameters
handleInput. Handle to a previously created cuDNN context.
countOutput. The resulting maximum number of algorithms.
Returns
CUDNN_STATUS_SUCCESSThe function was successful.
CUDNN_STATUS_BAD_PARAMThe provided handle is not allocated properly.
cudnnGetConvolutionBackwardDataWorkspaceSize()#
This function has been deprecated in cuDNN 9.0.
This function returns the amount of GPU memory workspace the user needs to allocate to be able to call cudnnConvolutionBackwardData() with the specified algorithm. The workspace allocated will then be passed to the routine cudnnConvolutionBackwardData(). The specified algorithm can be the result of the call to cudnnGetConvolutionBackwardDataAlgorithm_v7() or can be chosen arbitrarily by the user. Note that not every algorithm is available for every configuration of the input tensor and/or every configuration of the convolution descriptor.
cudnnStatus_t cudnnGetConvolutionBackwardDataWorkspaceSize( cudnnHandle_t handle, const cudnnFilterDescriptor_t wDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t dxDesc, cudnnConvolutionBwdDataAlgo_t algo, size_t *sizeInBytes)
Parameters
handleInput. Handle to a previously created cuDNN context.
wDescInput. Handle to a previously initialized filter descriptor.
dyDescInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dxDescInput. Handle to the previously initialized output tensor descriptor.
algoInput. Enumerant that specifies the chosen convolution algorithm.
sizeInBytesOutput. Amount of GPU memory needed as workspace to be able to execute a forward convolution with the specified
algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The numbers of feature maps of the input tensor and output tensor differ.
The
dataTypeof the two tensor descriptors or the filter are different.
CUDNN_STATUS_NOT_SUPPORTEDThe combination of the tensor descriptors, filter descriptor, and convolution descriptor is not supported for the specified algorithm.
cudnnGetConvolutionBackwardFilterAlgorithm_v7()#
This function has been deprecated in cuDNN 9.0.
This function serves as a heuristic for obtaining the best suited algorithm for cudnnConvolutionBackwardFilter() for the given layer specifications. This function will return all algorithms (including CUDNN_TENSOR_OP_MATH and CUDNN_DEFAULT_MATH versions of algorithms where CUDNN_TENSOR_OP_MATH may be available) sorted by expected (based on internal heuristic) relative performance with the fastest being index 0 of perfResults. For an exhaustive search for the fastest algorithm, use cudnnFindConvolutionBackwardFilterAlgorithm(). The total number of resulting algorithms can be queried through the returnedAlgoCount variable.
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithm_v7( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults)
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
dyDescInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dwDescInput. Handle to a previously initialized filter descriptor.
requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
One of the parameters
handle,xDesc,dyDesc,convDesc,dwDesc,perfResults, orreturnedAlgoCountisNULL.The numbers of feature maps of the input tensor and output tensor differ.
The
dataTypeof the two tensor descriptors or the filter are different.requestedAlgoCountis less than or equal to0.
cudnnGetConvolutionBackwardFilterAlgorithmMaxCount()#
This function has been deprecated in cuDNN 9.0.
This function returns the maximum number of algorithms which can be returned from cudnnFindConvolutionBackwardFilterAlgorithm() and cudnnGetConvolutionForwardAlgorithm_v7(). This is the sum of all algorithms plus the sum of all algorithms with Tensor Core operations supported for the current device.
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithmMaxCount( cudnnHandle_t handle, int *count)
Parameters
handleInput. Handle to a previously created cuDNN context.
countOutput. The resulting maximum count of algorithms.
Returns
CUDNN_STATUS_SUCCESSThe function was successful.
CUDNN_STATUS_BAD_PARAMThe provided handle is not allocated properly.
cudnnGetConvolutionBackwardFilterWorkspaceSize()#
This function has been deprecated in cuDNN 9.0.
This function returns the amount of GPU memory workspace the user needs to allocate to be able to call cudnnConvolutionBackwardFilter() with the specified algorithm. The workspace allocated will then be passed to the routine cudnnConvolutionBackwardFilter(). The specified algorithm can be the result of the call to cudnnGetConvolutionBackwardFilterAlgorithm_v7() or can be chosen arbitrarily by the user. Note that not every algorithm is available for every configuration of the input tensor and/or every configuration of the convolution descriptor.
cudnnStatus_t cudnnGetConvolutionBackwardFilterWorkspaceSize( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, cudnnConvolutionBwdFilterAlgo_t algo, size_t *sizeInBytes)
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
dyDescInput. Handle to the previously initialized input differential tensor descriptor.
convDescInput. Previously initialized convolution descriptor.
dwDescInput. Handle to a previously initialized filter descriptor.
algoInput. Enumerant that specifies the chosen convolution algorithm.
sizeInBytesOutput. Amount of GPU memory needed as workspace to be able to execute a forward convolution with the specified
algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The numbers of feature maps of the input tensor and output tensor differ.
The
dataTypeof the two tensor descriptors or the filter are different.
CUDNN_STATUS_NOT_SUPPORTEDThe combination of the tensor descriptors, filter descriptor and convolution descriptor is not supported for the specified algorithm.
cudnnGetConvolutionForwardAlgorithm_v7()#
This function has been deprecated in cuDNN 9.0.
This function serves as a heuristic for obtaining the best suited algorithm for cudnnConvolutionForward() for the given layer specifications. This function will return all algorithms (including CUDNN_TENSOR_OP_MATH and CUDNN_DEFAULT_MATH versions of algorithms where CUDNN_TENSOR_OP_MATH may be available) sorted by expected (based on internal heuristic) relative performance with the fastest being index 0 of perfResults. For an exhaustive search for the fastest algorithm, use cudnnFindConvolutionForwardAlgorithm(). The total number of resulting algorithms can be queried through the returnedAlgoCount variable.
cudnnStatus_t cudnnGetConvolutionForwardAlgorithm_v7( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionFwdAlgoPerf_t *perfResults)
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized input tensor descriptor.
wDescInput. Handle to a previously initialized convolution filter descriptor.
convDescInput. Previously initialized convolution descriptor.
yDescInput. Handle to the previously initialized output tensor descriptor.
requestedAlgoCountInput. The maximum number of elements to be stored in
perfResults.returnedAlgoCountOutput. The number of output elements stored in
perfResults.perfResultsOutput. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
One of the parameters
handle,xDesc,wDesc,convDesc,yDesc,perfResults, orreturnedAlgoCountisNULL.Either
yDescorwDeschave different dimensions fromxDesc.The data types of tensors
xDesc,yDesc, orwDescare not all the same.The number of feature maps in
xDescandwDescdiffers.The tensor
xDeschas a dimension smaller than3.requestedAlgoCountis less than or equal to0.
cudnnGetConvolutionForwardAlgorithmMaxCount()#
This function has been deprecated in cuDNN 9.0.
This function returns the maximum number of algorithms which can be returned from cudnnFindConvolutionForwardAlgorithm() and cudnnGetConvolutionForwardAlgorithm_v7(). This is the sum of all algorithms plus the sum of all algorithms with Tensor Core operations supported for the current device.
cudnnStatus_t cudnnGetConvolutionForwardAlgorithmMaxCount( cudnnHandle_t handle, int *count)
Parameters
handleInput. Handle to a previously created cuDNN context.
countOutput. The resulting maximum number of algorithms.
Returns
CUDNN_STATUS_SUCCESSThe function was successful.
CUDNN_STATUS_BAD_PARAMThe provided handle is not allocated properly.
cudnnGetConvolutionForwardWorkspaceSize()#
This function has been deprecated in cuDNN 9.0.
This function returns the amount of GPU memory workspace the user needs to allocate to be able to call cudnnConvolutionForward() with the specified algorithm. The workspace allocated will then be passed to the routine cudnnConvolutionForward(). The specified algorithm can be the result of the call to cudnnGetConvolutionForwardAlgorithm_v7() or can be chosen arbitrarily by the user. Note that not every algorithm is available for every configuration of the input tensor and/or every configuration of the convolution descriptor.
cudnnStatus_t cudnnGetConvolutionForwardWorkspaceSize( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t yDesc, cudnnConvolutionFwdAlgo_t algo, size_t *sizeInBytes)
Parameters
handleInput. Handle to a previously created cuDNN context.
xDescInput. Handle to the previously initialized
xtensor descriptor.wDescInput. Handle to a previously initialized filter descriptor.
convDescInput. Previously initialized convolution descriptor.
yDescInput. Handle to the previously initialized
ytensor descriptor.algoInput. Enumerant that specifies the chosen convolution algorithm.
sizeInBytesOutput. Amount of GPU memory needed as workspace to be able to execute a forward convolution with the specified
algo.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
One of the parameters
handle,xDesc,wDesc,convDesc, oryDescisNULL.The tensor
yDescorwDescare not of the same dimension asxDesc.The tensor
xDesc,yDesc, orwDescare not of the same data type.The numbers of feature maps of the tensor
xDescandwDescdiffer.The tensor
xDeschas a dimension smaller than3.
CUDNN_STATUS_NOT_SUPPORTEDThe combination of the tensor descriptors, filter descriptor, and convolution descriptor is not supported for the specified algorithm.
cudnnGetConvolutionGroupCount()#
This function has been deprecated in cuDNN 9.0.
This function returns the group count specified in the given convolution descriptor.
cudnnStatus_t cudnnGetConvolutionGroupCount( cudnnConvolutionDescriptor_t convDesc, int *groupCount)
Returns
CUDNN_STATUS_SUCCESSThe group count was returned successfully.
CUDNN_STATUS_BAD_PARAMAn invalid convolution descriptor was provided.
cudnnGetConvolutionMathType()#
This function has been deprecated in cuDNN 9.0.
This function returns the math type specified in a given convolution descriptor.
cudnnStatus_t cudnnGetConvolutionMathType( cudnnConvolutionDescriptor_t convDesc, cudnnMathType_t *mathType)
Returns
CUDNN_STATUS_SUCCESSThe math type was returned successfully.
CUDNN_STATUS_BAD_PARAMAn invalid convolution descriptor was provided.
cudnnGetConvolutionNdDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function queries a previously initialized convolution descriptor object.
cudnnStatus_t cudnnGetConvolutionNdDescriptor( const cudnnConvolutionDescriptor_t convDesc, int arrayLengthRequested, int *arrayLength, int padA[], int filterStrideA[], int dilationA[], cudnnConvolutionMode_t *mode, cudnnDataType_t *dataType)
Parameters
convDescInput/Output. Handle to a previously created convolution descriptor.
arrayLengthRequestedInput. Dimension of the expected convolution descriptor. It is also the minimum size of the arrays
padA,filterStrideA, anddilationAin order to be able to hold the resultsarrayLengthOutput. Actual dimension of the convolution descriptor.
padAOutput. Array of dimension of at least
arrayLengthRequestedthat will be filled with the padding parameters from the provided convolution descriptor.filterStrideAOutput. Array of dimension of at least
arrayLengthRequestedthat will be filled with the filter stride from the provided convolution descriptor.dilationAOutput. Array of dimension of at least
arrayLengthRequestedthat will be filled with the dilation parameters from the provided convolution descriptor.modeOutput. Convolution mode of the provided descriptor.
datatypeOutput. Datatype of the provided descriptor.
Returns
CUDNN_STATUS_SUCCESSThe query was successful.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The descriptor
convDescisNIL.The
arrayLengthRequestis negative.
CUDNN_STATUS_NOT_SUPPORTEDThe
arrayLengthRequestedis greater thanCUDNN_DIM_MAX-2.
cudnnGetConvolutionNdForwardOutputDim()#
This function has been deprecated in cuDNN 9.0.
This function returns the dimensions of the resulting Nd tensor of a nbDims-2-D convolution, given the convolution descriptor, the input tensor descriptor and the filter descriptor This function can help to setup the output tensor and allocate the proper amount of memory prior to launch the actual convolution.
cudnnStatus_t cudnnGetConvolutionNdForwardOutputDim( const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t inputTensorDesc, const cudnnFilterDescriptor_t filterDesc, int nbDims, int tensorOuputDimA[])
Each dimension of the (nbDims-2)-D images of the output tensor is computed as follows:
outputDim = 1 + ( inputDim + 2*pad - (((filterDim-1)*dilation)+1) )/convolutionStride;
The dimensions provided by this routine must be strictly respected when calling cudnnConvolutionForward() or cudnnConvolutionBackwardBias(). Providing a smaller or larger output tensor is not supported by the convolution routines.
Parameters
convDescInput. Handle to a previously created convolution descriptor.
inputTensorDescInput. Handle to a previously initialized tensor descriptor.
filterDescInput. Handle to a previously initialized filter descriptor.
nbDimsInput. Dimension of the output tensor
tensorOuputDimAOutput. Array of dimensions
nbDimsthat contains on exit of this routine the sizes of the output tensor
Returns
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
One of the parameters
convDesc,inputTensorDesc, andfilterDescisNIL.The dimension of the filter descriptor
filterDescis different from the dimension of input tensor descriptorinputTensorDesc.The dimension of the convolution descriptor is different from the dimension of input tensor descriptor
inputTensorDesc-2.The features map of the filter descriptor
filterDescis different from the one of input tensor descriptorinputTensorDesc.The size of the dilated filter
filterDescis larger than the padded sizes of the input tensor.The dimension
nbDimsof the output array is negative or greater than the dimension of input tensor descriptorinputTensorDesc.
CUDNN_STATUS_SUCCESSThe routine exited successfully.
cudnnGetConvolutionReorderType()#
This function has been deprecated in cuDNN 9.0.
This function retrieves the convolution reorder type from the given convolution descriptor.
cudnnStatus_t cudnnGetConvolutionReorderType( cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t *reorderType);
Parameters
convDescInput. The convolution descriptor from which the reorder type should be retrieved.
reorderTypeOutput. The retrieved reorder type. For more information, refer to cudnnReorderType_t.
Returns
CUDNN_STATUS_BAD_PARAMOne of the inputs to this function is not valid.
CUDNN_STATUS_SUCCESSThe reorder type is retrieved successfully.
cudnnGetFoldedConvBackwardDataDescriptors()#
This function calculates folding descriptors for backward data gradients. It takes as input the data descriptors along with the convolution descriptor and computes the folded data descriptors and the folding transform descriptors. These can then be used to do the actual folding transform.
cudnnStatus_t cudnnGetFoldedConvBackwardDataDescriptors(const cudnnHandle_t handle, const cudnnFilterDescriptor_t filterDesc, const cudnnTensorDescriptor_t diffDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t gradDesc, const cudnnTensorFormat_t transformFormat, cudnnFilterDescriptor_t foldedFilterDesc, cudnnTensorDescriptor_t paddedDiffDesc, cudnnConvolutionDescriptor_t foldedConvDesc, cudnnTensorDescriptor_t foldedGradDesc, cudnnTensorTransformDescriptor_t filterFoldTransDesc, cudnnTensorTransformDescriptor_t diffPadTransDesc, cudnnTensorTransformDescriptor_t gradFoldTransDesc, cudnnTensorTransformDescriptor_t gradUnfoldTransDesc) ;
Parameters
handleInput. Handle to a previously created cuDNN context.
filterDescInput. Filter descriptor before folding.
diffDescInput.
Diffdescriptor before folding.convDescInput. Convolution descriptor before folding.
gradDescInput. Gradient descriptor before folding.
transformFormatInput. Transform format for folding.
foldedFilterDescOutput. Folded filter descriptor.
paddedDiffDescOutput. Padded
Diffdescriptor.foldedConvDescOutput. Folded convolution descriptor.
foldedGradDescOutput. Folded gradient descriptor.
filterFoldTransDescOutput. Folding transform descriptor for filter.
diffPadTransDescOutput. Folding transform descriptor for
Desc.gradFoldTransDescOutput. Folding transform descriptor for gradient.
gradUnfoldTransDescOutput. Unfolding transform descriptor for folded gradient.
Returns
CUDNN_STATUS_SUCCESSFolded descriptors were computed successfully.
CUDNN_STATUS_BAD_PARAMIf any of the input parameters is
NULLor if the input tensor has more than 4 dimensions.CUDNN_STATUS_EXECUTION_FAILEDComputing the folded descriptors failed.
cudnnGetFusedOpsConstParamPackAttribute()#
This function retrieves the values of the descriptor pointed to by the param pointer input. The type of the descriptor is indicated by the enum value of paramLabel input.
cudnnStatus_t cudnnGetFusedOpsConstParamPackAttribute( const cudnnFusedOpsConstParamPack_t constPack, cudnnFusedOpsConstParamLabel_t paramLabel, void *param, int *isNULL);
Parameters
constPackInput. The opaque cudnnFusedOpsConstParamPack_t structure that contains the various problem size information, such as the shape, layout, and the type of tensors, and the descriptors for convolution and activation, for the selected sequence of cudnnFusedOps_t computations.
paramLabelInput. Several types of descriptors can be retrieved by this getter function. The
paraminput points to the descriptor itself, and this input indicates the type of the descriptor pointed to by theparaminput. The cudnnFusedOpsConstParamLabel_t enumerant type enables the selection of the type of the descriptor. Refer to theparamdescription below.paramInput. Data pointer to the host memory associated with the descriptor that should be retrieved. The type of this descriptor depends on the value of
paramLabel. For the givenparamLabel, if the associated value inside theconstPackis set toNULLor by defaultNULL, then cuDNN will copy the value or the opaque structure in theconstPackto the host memory buffer pointed to byparam. For more information, refer to the table in cudnnFusedOpsConstParamLabel_t.isNULLInput/Output. Users must pass a pointer to an integer in the host memory in this field. If the value in the
constPackassociated with the givenparamLabelis by defaultNULLor previously set by the user toNULL, then cuDNN will write a non-zero value to the location pointed byisNULL.
Returns
CUDNN_STATUS_SUCCESSThe descriptor values are retrieved successfully.
CUDNN_STATUS_BAD_PARAMIf either
constPack,param, orisNULLisNULL; or ifparamLabelis invalid.
cudnnGetFusedOpsVariantParamPackAttribute()#
This function retrieves the settings of the variable parameter pack descriptor.
cudnnStatus_t cudnnGetFusedOpsVariantParamPackAttribute( const cudnnFusedOpsVariantParamPack_t varPack, cudnnFusedOpsVariantParamLabel_t paramLabel, void *ptr);
Parameters
varPackInput. Pointer to the
cudnnFusedOpsvariant parameter pack (varPack) descriptor.paramLabelInput. Type of the buffer pointer parameter (in the
varPackdescriptor). For more information, refer to cudnnFusedOpsConstParamLabel_t. The retrieved descriptor values vary according to this type.ptrOutput. Pointer to the host or device memory where the retrieved value is written by this function. The data type of the pointer, and the host/device memory location, depend on the
paramLabelinput selection. For more information, refer to cudnnFusedOpsVariantParamLabel_t.
Returns
CUDNN_STATUS_SUCCESSThe descriptor values are retrieved successfully.
CUDNN_STATUS_BAD_PARAMIf either
varPackorptrisNULL, or ifparamLabelis set to invalid value.
cudnnIm2Col()#
This function has been deprecated in cuDNN 9.0.
This function constructs the A matrix necessary to perform a forward pass of GEMM convolution.
cudnnStatus_t cudnnIm2Col( cudnnHandle_t handle, cudnnTensorDescriptor_t srcDesc, const void *srcData, cudnnFilterDescriptor_t filterDesc, cudnnConvolutionDescriptor_t convDesc, void *colBuffer)
This A matrix has a height of batch_size*y_height*y_width and width of input_channels*filter_height*filter_width, where:
batch_sizeissrcDescfirst dimension
y_height/y_widthare computed from cudnnGetConvolutionNdForwardOutputDim()input_channels is
srcDescsecond dimension (when in NCHW layout)
filter_height/filter_widtharewDescthird and fourth dimension
The A matrix is stored in format HW fully-packed in GPU memory.
Parameters
handleInput. Handle to a previously created cuDNN context.
srcDescInput. Handle to a previously initialized tensor descriptor.
srcDataInput. Data pointer to GPU memory associated with the input tensor descriptor.
filterDescInput. Handle to a previously initialized filter descriptor.
convDescInput. Handle to a previously initialized convolution descriptor.
colBufferOutput. Data pointer to GPU memory storing the output matrix.
Returns
CUDNN_STATUS_BAD_PARAMsrcDataorcolBufferisNULL.CUDNN_STATUS_NOT_SUPPORTEDAny of
srcDesc,filterDesc,convDeschasdataTypeofCUDNN_DATA_INT8,CUDNN_DATA_INT8x4,CUDNN_DATA_INT8, orCUDNN_DATA_INT8x4convDeschasgroupCountlarger than1.CUDNN_STATUS_EXECUTION_FAILEDThe CUDA kernel execution was unsuccessful.
CUDNN_STATUS_SUCCESSThe output data array is successfully generated.
cudnnMakeFusedOpsPlan()#
This function has been deprecated in cuDNN 9.0.
This function determines the optimum kernel to execute, and the workspace size the user should allocate, prior to the actual execution of the fused operations by cudnnFusedOpsExecute().
cudnnStatus_t cudnnMakeFusedOpsPlan( cudnnHandle_t handle, cudnnFusedOpsPlan_t plan, const cudnnFusedOpsConstParamPack_t constPack, size_t *workspaceSizeInBytes);
Parameters
handleInput. Pointer to the cuDNN library context.
planInput. Pointer to a previously-created and initialized plan descriptor.
constPackInput. Pointer to the descriptor to the const parameters pack.
workspaceSizeInBytesOutput. The amount of workspace size the user should allocate for the execution of this plan.
Returns
CUDNN_STATUS_BAD_PARAMIf any of the inputs is
NULL, or if the type of cudnnFusedOps_t in theconstPackdescriptor is unsupported.CUDNN_STATUS_SUCCESSThe function executed successfully.
cudnnReorderFilterAndBias()#
This function has been deprecated in cuDNN 9.0.
This function reorders the filter and bias values for tensors with data type CUDNN_DATA_INT8x32 and tensor format CUDNN_TENSOR_NCHW_VECT_C. It can be used to enhance the inference time by separating the reordering operation from convolution.
cudnnStatus_t cudnnReorderFilterAndBias( cudnnHandle_t handle, const cudnnFilterDescriptor_t filterDesc, cudnnReorderType_t reorderType, const void *filterData, void *reorderedFilterData, int reorderBias, const void *biasData, void *reorderedBiasData);
Filter and bias tensors with data type CUDNN_DATA_INT8x32 (also implying tensor format CUDNN_TENSOR_NCHW_VECT_C) requires permutation of output channel axes in order to take advantage of the Tensor Core IMMA instruction. This is done in every cudnnConvolutionForward() and cudnnConvolutionBiasActivationForward() call when the reorder type attribute of the convolution descriptor is set to CUDNN_DEFAULT_REORDER. Users can avoid the repeated reordering kernel call by first using this call to reorder the filter and bias tensor and call the convolution forward APIs with reorder type set to CUDNN_NO_REORDER.
For example, convolutions in a neural network of multiple layers can require reordering of kernels at every layer, which can take up a significant fraction of the total inference time. Using this function, the reordering can be done one time on the filter and bias data. This is followed by the convolution operations at the multiple layers, which enhance the inference time.
Parameters
handleInput. Handle to a previously created cuDNN context.
filterDescInput. Descriptor for the kernel dataset.
reorderTypeInput. Setting to either perform reordering or not. For more information, refer to cudnnReorderType_t.
filterDataInput. Pointer to the filter (kernel) data location in the device memory.
reorderedFilterDataOutput. Pointer to the location in the device memory where the reordered filter data will be written to, by this function. This tensor has the same dimensions as
filterData.reorderBiasInput. If > 0, then reorders the
biasDataalso. If <= 0 then does not perform reordering operations on thebiasData.biasDataInput. Pointer to the bias data location in the device memory.
reorderedBiasDataOutput. Pointer to the location in the device memory where the reordered
biasDatawill be written to, by this function. This tensor has the same dimensions asbiasData.
Returns
CUDNN_STATUS_SUCCESSReordering was successful.
CUDNN_STATUS_EXECUTION_FAILEDEither the reordering of the filter data or of the
biasDatafailed.CUDNN_STATUS_BAD_PARAMThe handle, filter descriptor, filter data, or reordered data is
NULL. Or, if the bias reordering is requested (reorderBias > 0), thebiasDataor reorderedbiasDataisNULL. This status can also be returned if the filter dimension size is not4.CUDNN_STATUS_NOT_SUPPORTEDFilter descriptor data type is not
CUDNN_DATA_INT8x32; the filter descriptor tensor is not in a vectorized layout (CUDNN_TENSOR_NCHW_VECT_C).
cudnnSetConvolution2dDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function initializes a previously created convolution descriptor object into a 2D correlation. This function assumes that the tensor and filter descriptors correspond to the forward convolution path and checks if their settings are valid. That same convolution descriptor can be reused in the backward path provided it corresponds to the same layer.
cudnnStatus_t cudnnSetConvolution2dDescriptor( cudnnConvolutionDescriptor_t convDesc, int pad_h, int pad_w, int u, int v, int dilation_h, int dilation_w, cudnnConvolutionMode_t mode, cudnnDataType_t computeType)
Parameters
convDescInput/Output. Handle to a previously created convolution descriptor.
pad_hInput. Zero-padding height: number of rows of zeros implicitly concatenated onto the top and onto the bottom of input images.
pad_wInput. Zero-padding width: number of columns of zeros implicitly concatenated onto the left and onto the right of input images.
uInput. Vertical filter stride.
vInput. Horizontal filter stride.
dilation_hInput. Filter height dilation.
dilation_wInput. Filter width dilation.
modeInput. Selects between
CUDNN_CONVOLUTIONandCUDNN_CROSS_CORRELATION.computeTypeInput. compute precision.
Returns
CUDNN_STATUS_SUCCESSThe object was set successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The descriptor
convDescisNIL.One of the parameters
pad_h,pad_wis strictly negative.One of the parameters
u,vis negative or zero.One of the parameters
dilation_h,dilation_wis negative or zero.The parameter mode has an invalid enumerant value.
cudnnSetConvolutionGroupCount()#
This function has been deprecated in cuDNN 9.0.
This function allows the user to specify the number of groups to be used in the associated convolution.
cudnnStatus_t cudnnSetConvolutionGroupCount( cudnnConvolutionDescriptor_t convDesc, int groupCount)
Returns
CUDNN_STATUS_SUCCESSThe group count was set successfully.
CUDNN_STATUS_BAD_PARAMAn invalid convolution descriptor was provided.
cudnnSetConvolutionMathType()#
This function has been deprecated in cuDNN 9.0.
This function allows the user to specify whether or not the use of tensor op is permitted in the library routines associated with a given convolution descriptor.
cudnnStatus_t cudnnSetConvolutionMathType( cudnnConvolutionDescriptor_t convDesc, cudnnMathType_t mathType)
Returns
CUDNN_STATUS_SUCCESSThe math type was set successfully.
CUDNN_STATUS_BAD_PARAMEither an invalid convolution descriptor was provided or an invalid math type was specified.
cudnnSetConvolutionNdDescriptor()#
This function has been deprecated in cuDNN 9.0.
This function initializes a previously created generic convolution descriptor object into a Nd correlation. That same convolution descriptor can be reused in the backward path provided it corresponds to the same layer. The convolution computation will be done in the specified dataType, which can be potentially different from the input/output tensors.
cudnnStatus_t cudnnSetConvolutionNdDescriptor( cudnnConvolutionDescriptor_t convDesc, int arrayLength, const int padA[], const int filterStrideA[], const int dilationA[], cudnnConvolutionMode_t mode, cudnnDataType_t dataType)
Parameters
convDescInput/Output. Handle to a previously created convolution descriptor.
arrayLengthInput. Dimension of the convolution.
padAInput. Array of dimension
arrayLengthcontaining the zero-padding size for each dimension. For every dimension, the padding represents the number of extra zeros implicitly concatenated at the start and at the end of every element of that dimension.filterStrideAInput. Array of dimension
arrayLengthcontaining the filter stride for each dimension. For every dimension, the filter stride represents the number of elements to slide to reach the next start of the filtering window of the next point.dilationAInput. Array of dimension
arrayLengthcontaining the dilation factor for each dimension.modeInput. Selects between
CUDNN_CONVOLUTIONandCUDNN_CROSS_CORRELATION.datatypeInput. Selects the data type in which the computation will be done.
Note
CUDNN_DATA_HALFincudnnSetConvolutionNdDescriptor()withHALF_CONVOLUTION_BWD_FILTERis not recommended as it is known to not be useful for any practical use case for training and will be considered to be blocked in a future cuDNN release. The use ofCUDNN_DATA_HALFfor input tensors in cudnnSetTensorNdDescriptor() andCUDNN_DATA_FLOATincudnnSetConvolutionNdDescriptor()withHALF_CONVOLUTION_BWD_FILTERis recommended and is used with the automatic mixed precision (AMP) training in many well known deep learning frameworks.
Returns
CUDNN_STATUS_SUCCESSThe object was set successfully.
CUDNN_STATUS_BAD_PARAMAt least one of the following conditions are met:
The descriptor
convDescisNIL.The
arrayLengthRequestis negative.The enumerant mode has an invalid value.
The enumerant
datatypehas an invalid value.One of the elements of
padAis strictly negative.One of the elements of
strideAis negative or zero.One of the elements of
dilationAis negative or zero.
CUDNN_STATUS_NOT_SUPPORTEDAt least one of the following conditions are met:
The
arrayLengthRequestis greater thanCUDNN_DIM_MAX.
cudnnSetConvolutionReorderType()#
This function has been deprecated in cuDNN 9.0.
This function sets the convolution reorder type for the given convolution descriptor.
cudnnStatus_t cudnnSetConvolutionReorderType( cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t reorderType);
Parameters
convDescInput. The convolution descriptor for which the reorder type should be set.
reorderTypeInput. Set the reorder type to this value. For more information, refer to cudnnReorderType_t.
Returns
CUDNN_STATUS_BAD_PARAMThe reorder type supplied is not supported.
CUDNN_STATUS_SUCCESSReorder type is set successfully.
cudnnSetFusedOpsConstParamPackAttribute()#
This function has been deprecated in cuDNN 9.0.
This function sets the descriptor pointed to by the param pointer input. The type of the descriptor to be set is indicated by the enum value of the paramLabel input.
cudnnStatus_t cudnnSetFusedOpsConstParamPackAttribute( cudnnFusedOpsConstParamPack_t constPack, cudnnFusedOpsConstParamLabel_t paramLabel, const void *param);
Parameters
constPackInput. The opaque cudnnFusedOpsConstParamPack_t structure that contains the various problem size information, such as the shape, layout and the type of tensors, the descriptors for convolution and activation, and settings for operations such as convolution and activation.
paramLabelInput. Several types of descriptors can be set by this setter function. The
paraminput points to the descriptor itself, and this input indicates the type of the descriptor pointed to by theparaminput. The cudnnFusedOpsConstParamPack_t enumerant type enables the selection of the type of the descriptor.paramInput. Data pointer to the host memory, associated with the specific descriptor. The type of the descriptor depends on the value of
paramLabel. For more information, refer to the table in cudnnFusedOpsConstParamPack_t.If this pointer is set to
NULL, then the cuDNN library will record as such. If not, then the values pointed to by this pointer (meaning, the value or the opaque structure underneath) will be copied into theconstPackduringcudnnSetFusedOpsConstParamPackAttribute()operation.
Returns
CUDNN_STATUS_SUCCESSThe descriptor is set successfully.
CUDNN_STATUS_BAD_PARAMIf
constPackisNULL, or ifparamLabelor the ops setting forconstPackis invalid.
cudnnSetFusedOpsVariantParamPackAttribute()#
This function has been deprecated in cuDNN 9.0.
This function sets the variable parameter pack descriptor.
cudnnStatus_t cudnnSetFusedOpsVariantParamPackAttribute( cudnnFusedOpsVariantParamPack_t varPack, cudnnFusedOpsVariantParamLabel_t paramLabel, void *ptr);
Parameters
varPackInput. Pointer to the
cudnnFusedOpsvariant parameter pack (varPack) descriptor.paramLabelInput. Type to which the buffer pointer parameter (in the
varPackdescriptor) is set by this function. For more information, refer to cudnnFusedOpsConstParamLabel_t.ptrInput. Pointer to the host or device memory, to the value to which the descriptor parameter is set. The data type of the pointer, and the host/device memory location, depend on the
paramLabelinput selection. For more information, refer to cudnnFusedOpsVariantParamLabel_t.
Returns
CUDNN_STATUS_BAD_PARAMIf
varPackisNULLor ifparamLabelis set to an unsupported value.CUDNN_STATUS_SUCCESSThe descriptor is set successfully.
Footnotes