Overview#
The NVIDIA DGX SuperPOD™ is a multi-user system designed to run large AI and HPC applications efficiently. Although a DGX SuperPOD is composed of many different components, it should be thought of as an entity that can manage simultaneous use by many users, provide advanced access controls for queuing, and schedule resources fairly to ensure maximum performance. It also provides the tools for collaboration between users and security controls to protect data and limit interaction between users where necessary. The management tools are designed to treat the multiple components as a single system. For more details about the physical architecture, refer to the NVIDIA DGX SuperPOD Reference Architecture.
This document discusses the range of features and tasks that are supported on the DGX SuperPOD. The constituent elements that make up a DGX SuperPOD, both in hardware and software, support a superset of features compared to the DGX SuperPOD solution. Contact the NVIDIA Technical Account Manager (TAM) if clarification is needed on what functionality is supported by the DGX SuperPOD product.
Important
NVIDIA DGX SuperPOD only supports Slurm and Kubernetes with RunAI.
System Design#
A logical depiction of the DGX SuperPOD is shown in Figure 1.
Figure 1. DGX SuperPOD logical design
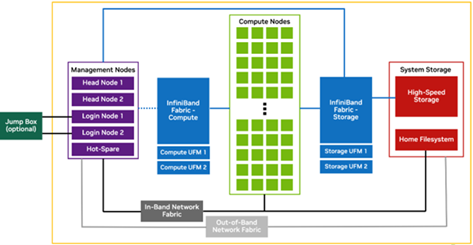
Table 1 describes the components shown in Figure 1.
DGX SuperPOD Component |
Description |
|---|---|
Jump box/entry point |
The Jump Box/Entry Point is the gateway into the DGX SuperPOD intended to provide a single entry-point into the cluster and additional security when required. It is not actually a part of the DGX SuperPOD, but of the corporate IT environment. This function is defined and provided by local IT requirements. |
Compute nodes |
The compute nodes are where the user work gets done on the system. Each compute node is an individual DGX server |
Management nodes |
The management nodes provide the services necessary to support operation and monitoring of the DGX SuperPOD. Services, configured in high availability (HA) mode where needed, provide the highest system availability. See Table 2 for details of each node and its function. |
High-speed storage |
High-speed storage provides shared storage to all nodes in the DGX SuperPOD. This is where datasets, checkpoints, and other large files should be stored. High-speed storage typically holds large datasets that are being actively operated on by the DGX SuperPOD jobs. Data on the high-speed storage is a subset of all data housed in a data lake outside of the DGX SuperPOD. |
Shared storage |
Shared storage on a network file system (NFS) is allocated for user home directories as well for cluster services. |
InfiniBand fabric—compute |
The Compute InfiniBand Fabric is the high-speed network fabric connecting all compute nodes together to allow high-bandwidth and low-latency communication between the compute nodes. |
InfiniBand fabric—storage |
The Storage InfiniBand Fabric is the high-speed network fabric dedicated for storage traffic. Storage traffic is dedicated to its own fabric to remove interference with the node-to-node application traffic that can degrade overall performance. |
In-band network fabric |
The In-band Network Fabric provides fast Ethernet connectivity between all nodes in the DGX SuperPOD. The In-band fabric is used for TCP/IP-based communication and services. |
Out-of-band network fabric |
The out-of-band Ethernet network is used for system management using the BMC and provides connectivity to manage all networking equipment. |
Management Servers#
Table 2 details the function and services running on the management servers.
Server Function |
Services |
|---|---|
Head Node |
Head nodes serve various functions:
|
Login |
Entry point to the DGX SuperPOD for users. CPU only node that is a Slurm client and has filesystems mounted to support development, job submission, job monitoring, and file management. Multiple nodes are included for redundancy and supporting user workloads. These hosts can also be used for container caching. |
UFM Appliance |
NVIDIA Unified Fabric Manager (UFM) for both storage and compute. |