KV Block Manager (KVBM)#
The Dynamo KV Block Manager (KVBM) is a scalable runtime component designed to handle memory allocation, management, and remote sharing of Key-Value (KV) blocks for inference tasks across heterogeneous and distributed environments. It acts as a unified memory layer for frameworks like vLLM and TensorRT-LLM.
KVBM offers:
A unified memory API spanning GPU memory, pinned host memory, remote RDMA-accessible memory, local/distributed SSDs, and remote file/object/cloud storage systems
Support for block lifecycles (allocate → register → match) with event-based state transitions
Integration with NIXL, a dynamic memory exchange layer for remote registration, sharing, and access of memory blocks
Get started: See the KVBM Guide for installation and deployment instructions.
When to Use KV Cache Offloading#
KV Cache offloading avoids expensive KV Cache recomputation, resulting in faster response times and better user experience. Providers benefit from higher throughput and lower cost per token, making inference services more scalable and efficient.
Offloading KV cache to CPU or storage is most effective when KV Cache exceeds GPU memory and cache reuse outweighs the overhead of transferring data. It is especially valuable in:
Scenario |
Benefit |
|---|---|
Long sessions and multi-turn conversations |
Preserves large prompt prefixes, avoids recomputation, improves first-token latency and throughput |
High concurrency |
Idle or partial conversations can be moved out of GPU memory, allowing active requests to proceed without hitting memory limits |
Shared or repeated content |
Reuse across users or sessions (system prompts, templates) increases cache hits, especially with remote or cross-instance sharing |
Memory- or cost-constrained deployments |
Offloading to RAM or SSD reduces GPU demand, allowing longer prompts or more users without adding hardware |
Feature Support Matrix#
Feature |
Support |
|
|---|---|---|
Backend |
Local |
✅ |
Kubernetes |
✅ |
|
LLM Framework |
vLLM |
✅ |
TensorRT-LLM |
✅ |
|
SGLang |
❌ |
|
Serving Type |
Aggregated |
✅ |
Disaggregated |
✅ |
Architecture#
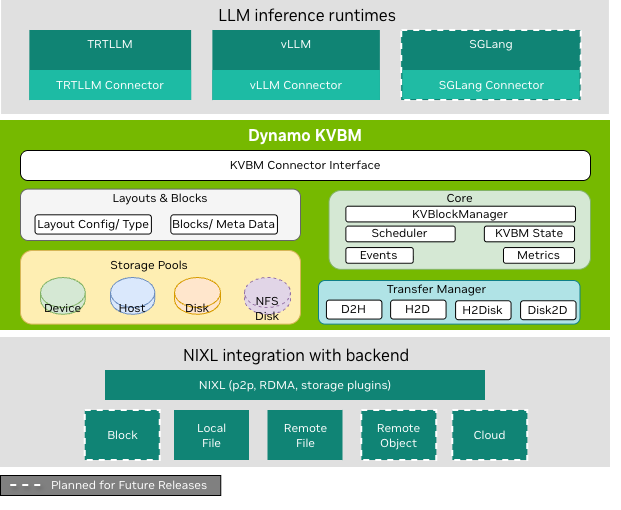 High-level layered architecture view of Dynamo KV Block Manager and how it interfaces with different components of the LLM inference ecosystem
High-level layered architecture view of Dynamo KV Block Manager and how it interfaces with different components of the LLM inference ecosystem
KVBM has three primary logical layers:
LLM Inference Runtime Layer — The top layer includes inference runtimes (TensorRT-LLM, vLLM) that integrate through dedicated connector modules to the Dynamo KVBM. These connectors act as translation layers, mapping runtime-specific operations and events into KVBM’s block-oriented memory interface. This decouples memory management from the inference runtime, enabling backend portability and memory tiering.
KVBM Logic Layer — The middle layer encapsulates core KV block manager logic and serves as the runtime substrate for managing block memory. The KVBM adapter normalizes representations and data layout for incoming requests across runtimes and forwards them to the core memory manager. This layer implements table lookups, memory allocation, block layout management, lifecycle state transitions, and block reuse/eviction policies.
NIXL Layer — The bottom layer provides unified support for all data and storage transactions. NIXL enables P2P GPU transfers, RDMA and NVLink remote memory sharing, dynamic block registration and metadata exchange, and provides a plugin interface for storage backends including block memory (GPU HBM, Host DRAM, Remote DRAM, Local SSD), local/remote filesystems, object stores, and cloud storage.
Learn more: See the KVBM Design Document for detailed architecture, components, and data flows.
Next Steps#
KVBM Guide — Installation, configuration, and deployment instructions
KVBM Design — Architecture deep dive, components, and data flows
LMCache Integration — Use LMCache with Dynamo vLLM backend
FlexKV Integration — Use FlexKV for KV cache management
SGLang HiCache — Enable SGLang’s hierarchical cache with NIXL
NIXL Documentation — NIXL communication library details