Running KVBM in vLLM#
This guide explains how to leverage KVBM (KV Block Manager) to manage KV cache and do KV offloading in vLLM.
To learn what KVBM is, please check here
Quick Start#
To use KVBM in vLLM, you can follow the steps below:
Docker Setup#
# Start up etcd for KVBM leader/worker registration and discovery
docker compose -f deploy/docker-compose.yml up -d
# Build a dynamo vLLM container (KVBM is built in by default)
./container/build.sh --framework vllm
# Launch the container
./container/run.sh --framework vllm -it --mount-workspace --use-nixl-gds
Aggregated Serving with KVBM#
cd $DYNAMO_HOME/examples/backends/vllm
./launch/agg_kvbm.sh
Disaggregated Serving with KVBM#
# 1P1D - one prefill worker and one decode worker
# NOTE: need at least 2 GPUs
cd $DYNAMO_HOME/examples/backends/vllm
./launch/disagg_kvbm.sh
# 2P2D - two prefill workers and two decode workers
# NOTE: need at least 4 GPUs
cd $DYNAMO_HOME/examples/backends/vllm
./launch/disagg_kvbm_2p2d.sh
Note
Configure or tune KVBM cache tiers (choose one of the following options):
# Option 1: CPU cache only (GPU -> CPU offloading)
# 4 means 4GB of pinned CPU memory would be used
export DYN_KVBM_CPU_CACHE_GB=4
# Option 2: Both CPU and Disk cache (GPU -> CPU -> Disk tiered offloading)
export DYN_KVBM_CPU_CACHE_GB=4
# 8 means 8GB of disk would be used
export DYN_KVBM_DISK_CACHE_GB=8
# [Experimental] Option 3: Disk cache only (GPU -> Disk direct offloading, bypassing CPU)
# NOTE: this option is only experimental and it might not give out the best performance.
# NOTE: disk offload filtering is not supported when using this option.
export DYN_KVBM_DISK_CACHE_GB=8
You can also use “DYN_KVBM_CPU_CACHE_OVERRIDE_NUM_BLOCKS” or “DYN_KVBM_DISK_CACHE_OVERRIDE_NUM_BLOCKS” to specify exact block counts instead of GB
Note
When disk offloading is enabled, to extend SSD lifespan, disk offload filtering would be enabled by default. The current policy is only offloading KV blocks from CPU to disk if the blocks have frequency equal or more than 2. Frequency is determined via doubling on cache hit (init with 1) and decrement by 1 on each time decay step.
To disable disk offload filtering, set DYN_KVBM_DISABLE_DISK_OFFLOAD_FILTER to true or 1.
Sample Request#
# Make a request to verify vLLM with KVBM is started up correctly
# NOTE: change the model name if served with a different one
curl localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{
"role": "user",
"content": "In the heart of Eldoria, an ancient land of boundless magic and mysterious creatures, lies the long-forgotten city of Aeloria. Once a beacon of knowledge and power, Aeloria was buried beneath the shifting sands of time, lost to the world for centuries. You are an intrepid explorer, known for your unparalleled curiosity and courage, who has stumbled upon an ancient map hinting at ests that Aeloria holds a secret so profound that it has the potential to reshape the very fabric of reality. Your journey will take you through treacherous deserts, enchanted forests, and across perilous mountain ranges. Your Task: Character Background: Develop a detailed background for your character. Describe their motivations for seeking out Aeloria, their skills and weaknesses, and any personal connections to the ancient city or its legends. Are they driven by a quest for knowledge, a search for lost familt clue is hidden."
}
],
"stream":false,
"max_tokens": 10
}'
Alternatively, can use vllm serve directly to use KVBM for aggregated serving:
vllm serve --kv-transfer-config '{"kv_connector":"DynamoConnector","kv_role":"kv_both", "kv_connector_module_path": "kvbm.vllm_integration.connector"}' Qwen/Qwen3-0.6B
Enable and View KVBM Metrics#
Follow below steps to enable metrics collection and view via Grafana dashboard:
# Start the basic services (etcd & natsd), along with Prometheus and Grafana
docker compose -f deploy/docker-observability.yml up -d
# Set env var DYN_KVBM_METRICS to true, when launch via dynamo
# Optionally set DYN_KVBM_METRICS_PORT to choose the /metrics port (default: 6880).
# NOTE: update launch/disagg_kvbm.sh or launch/disagg_kvbm_2p2d.sh as needed
DYN_KVBM_METRICS=true \
DYN_KVBM_CPU_CACHE_GB=20 \
python -m dynamo.vllm \
--model Qwen/Qwen3-0.6B \
--enforce-eager \
--connector kvbm
# Optional, if firewall blocks KVBM metrics ports to send prometheus metrics
sudo ufw allow 6880/tcp
View grafana metrics via http://localhost:3000 (default login: dynamo/dynamo) and look for KVBM Dashboard
KVBM currently provides following types of metrics out of the box:
kvbm_matched_tokens: The number of matched tokenskvbm_offload_blocks_d2h: The number of offload blocks from device to hostkvbm_offload_blocks_h2d: The number of offload blocks from host to diskkvbm_offload_blocks_d2d: The number of offload blocks from device to disk (bypassing host memory)kvbm_onboard_blocks_d2d: The number of onboard blocks from disk to devicekvbm_onboard_blocks_h2d: The number of onboard blocks from host to devicekvbm_host_cache_hit_rate: Host cache hit rate (0.0-1.0) from sliding windowkvbm_disk_cache_hit_rate: Disk cache hit rate (0.0-1.0) from sliding window
Troubleshooting#
If enabling KVBM does not show any TTFT perf gain or even perf degradation, one potential reason is not enough prefix cache hit on KVBM to reuse offloaded KV blocks. To confirm, please enable KVBM metrics as mentioned above and check the grafana dashboard
Onboard Blocks - Host to DeviceandOnboard Blocks - Disk to Device. If observed large number of onboarded KV blocks as the example below, we can rule out this cause: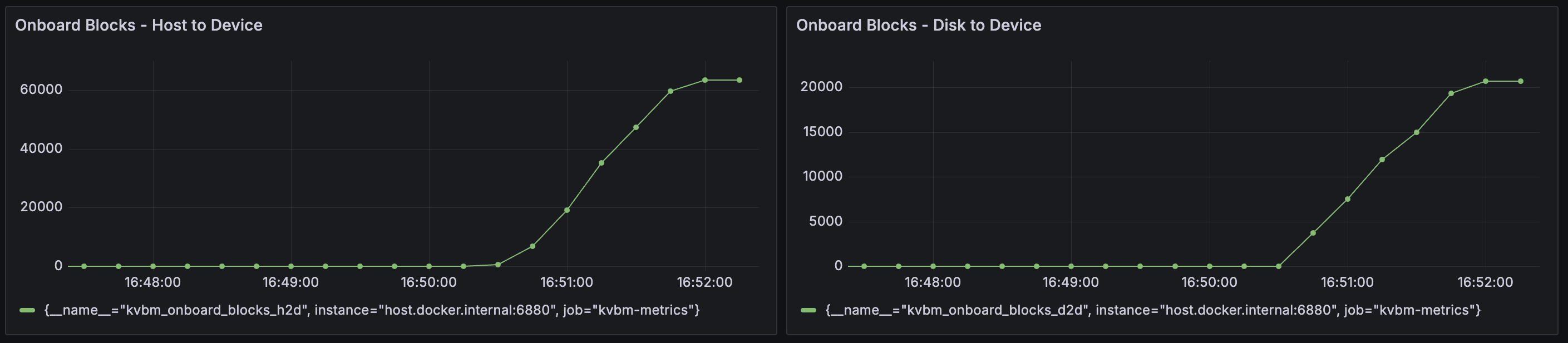
Allocating large memory and disk storage can take some time and lead to KVBM worker initialization timeout. To avoid it, please set a longer timeout (default 1800 seconds) for leader–worker initialization.
# 3600 means 3600 seconds timeout
export DYN_KVBM_LEADER_WORKER_INIT_TIMEOUT_SECS=3600
When offloading to disk is enabled, KVBM could fail to start up if fallocate is not supported to create the files. To bypass the issue, please use disk zerofill fallback.
# Set to true to enable fallback behavior when disk operations fail (e.g. fallocate not available)
export DYN_KVBM_DISK_ZEROFILL_FALLBACK=true
Benchmark KVBM#
Once the model is loaded ready, follow below steps to use LMBenchmark to benchmark KVBM performance:
git clone https://github.com/LMCache/LMBenchmark.git
# Show case of running the synthetic multi-turn chat dataset.
# We are passing model, endpoint, output file prefix and qps to the sh script.
cd LMBenchmark/synthetic-multi-round-qa
./long_input_short_output_run.sh \
"Qwen/Qwen3-0.6B" \
"http://localhost:8000" \
"benchmark_kvbm" \
1
# Average TTFT and other perf numbers would be in the output from above cmd
More details about how to use LMBenchmark could be found here.
NOTE: if metrics are enabled as mentioned in the above section, you can observe KV offloading, and KV onboarding in the grafana dashboard.
To compare, you can run vllm serve Qwen/Qwen3-0.6B to turn KVBM off as the baseline.
Developing Locally#
Inside the Dynamo container, after changing KVBM related code (Rust and/or Python), to test or use it:
cd /workspace/lib/bindings/kvbm
uv pip install maturin[patchelf]
maturin build --release --out /workspace/dist
uv pip install --upgrade --force-reinstall --no-deps /workspace/dist/kvbm*.whl