

Planner DynoSim Benchmarking
This guide shows how to benchmark the Dynamo Planner against a recorded trace by running it inside DynoSim. Use it to compare agg vs disagg topologies, tune SLA targets, and study how deployment realities (engine startup time, worker counts) affect planner behavior — all without bringing up a live cluster.
For the general mechanics of DynoSim runs (input format, arrival speedup, router modes, synthetic workloads), see DynoSim Runs. This guide focuses on the --planner-config path.
1. Setup
Build
Install the Dynamo Python components and build the Rust runtime bindings. The
python -m dynamo.replay CLI is part of the Python components, and it imports the
runtime _core module from the bindings package:
The --release flag is strongly recommended. DynoSim execution is largely single-threaded and CPU-bound on the mocker engine core; a debug build can be 5–10× slower, which compounds across sweep runs.
Key Planner Config Knobs
Passed as JSON via --planner-config. Uses the same schema as the live planner. The fields most relevant to benchmarking:
Key Engine Arg Knobs
Passed as JSON via --extra-engine-args (agg) or --prefill-engine-args / --decode-engine-args (disagg). DynoSim uses the mocker engine, so “engine args” means the analytical perf model inputs:
Other fields follow the standard mocker engine protocol (see DynoSim Runs).
Planner Traffic Metrics From Replay
Planner-in-the-loop replay feeds the same traffic shape that the live planner consumes, but the observation source is the offline simulator instead of Prometheus. On planner traffic ticks, replay drains:
The planner treats KV hit rate and accept length as runtime metadata with last-value semantics. Missing accept-length samples leave the last valid value unchanged; without MTP metadata or without a prior valid sample, the effective accept length is 1.0. When MTP is enabled, the planner clamps accept length to [1.0, nextn + 1.0], where nextn comes from replay engine capabilities (aic_nextn) or the speculative_nextn planner fallback.
MTP changes decode capacity by discounting ITL, not by rewriting raw OSL. Accept length can be slightly below nextn + 1 when the final decode burst is partial; for example, nextn=2 with all draft tokens accepted over OSL=64 gives 64 / 22 = 2.91. With decode batch size 16 and raw per-forward wall time 40 ms:
The raw 64 output tokens still feed KV residency, context-length estimates, and request length. In agg capacity, raw OSL remains the request output length, but accept length also tightens the prefill/decode balance because faster decode egress requires more prefill admissions per forward. Decode ITL SLA checks and decode RPS use the discounted ITL.
For AIC-backed MTP replay, set aic_nextn on the agg engine args or on the disagg decode engine args, and set aic_nextn_accept_rates to control the mocker burst sampler. The planner bootstrap path asks AIC for raw forward iteration time with zero accept rates internally, so the regression is trained on undiscounted wall time and the planner applies the observed replay accept length exactly once.
2. Example: Agg vs Disagg On The Mooncake Agentic Trace
Download the trace:
Run agg (2 workers, TP=1):
Run disagg (1P1D, TP=1):
Each run prints the AIPerf summary table to stdout and writes an HTML diagnostics report to ./planner_reports/<report_filename>. For this trace with a long ISL and short OSL, agg is better than disagg, which gets slightly better ITL at the cost noticeably more GPU-hours.
3. Example: Cold-Start-Time Sweep
How sensitive is SLA attainment to engine startup time? Sweep startup_time from 0 to 300 seconds in 10-second steps and record TTFT/ITL/GPU-hours per run.
Each run emits the AIPerf metrics table (parse TTFT / ITL avg / p90) and its HTML report (grep GPU hours: <float>). Plotting those against startup_time gives:
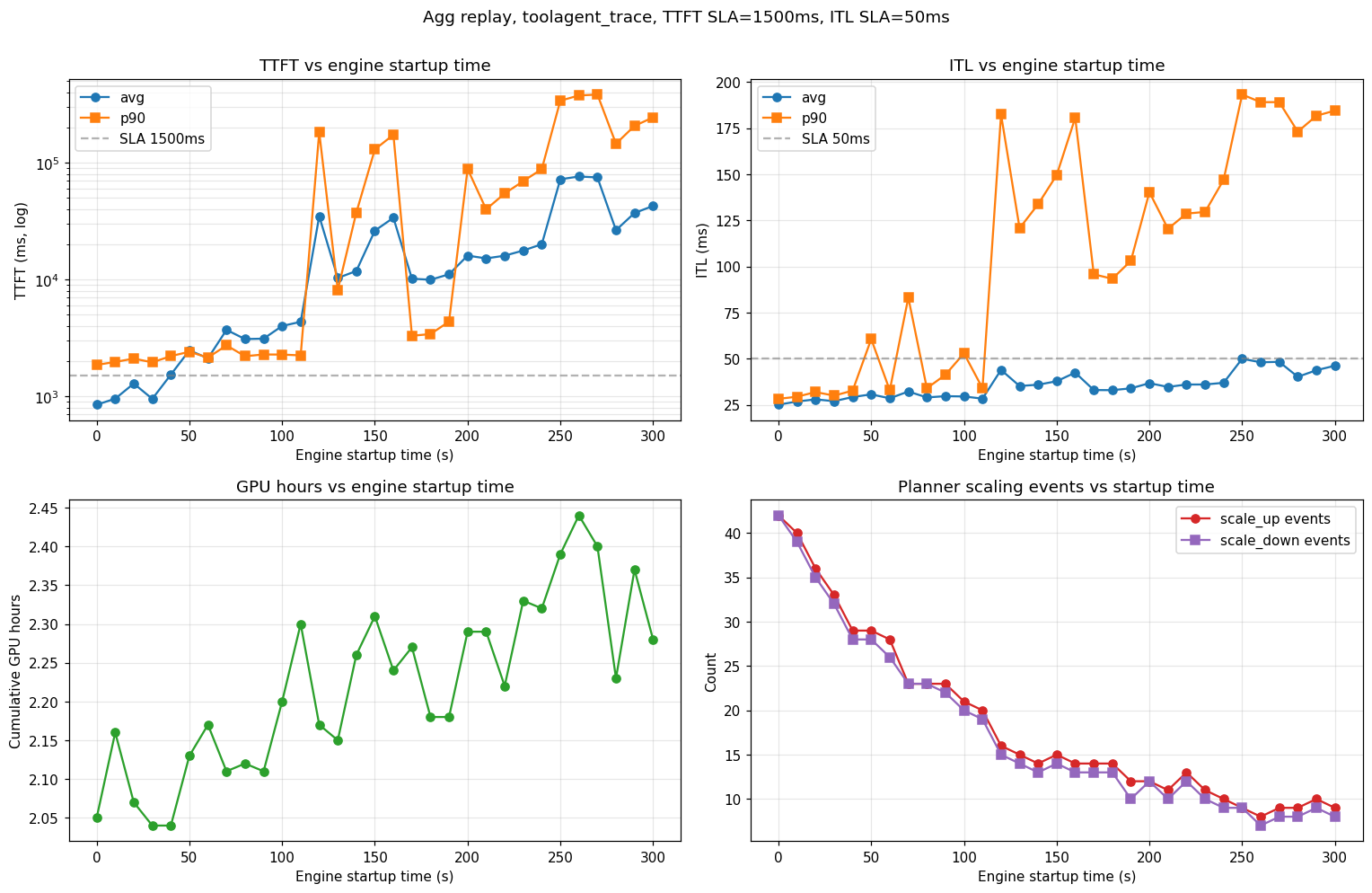
Observations from this sweep (agg, TTFT SLA 1,500 ms, ITL SLA 50 ms, H200-SXM, Llama-3.1-8B-FP8, TP=1):
- SLA cliff near 100–120 s. Below that, the planner scales up fast enough to hold TTFT; above it, p99 TTFT diverges and the system stays perpetually backlogged.
- Scaling-event count drops monotonically (42 → 8) as startup grows — long-startup runs require load planner to wait for stabilization before the next scaling decision.
- ITL is less sensitive than TTFT until the queue saturates. Below the cliff, ITL rises modestly (25 → 30 ms avg); above it, p90 ITL jumps to ~200 ms as decode requests starve.