Step #1: Training Pipeline
Before the AI pipeline can be run for the first time, an initial training job must be run.
Open the SSH console using the link in the left pane under the LaunchPad section.
Run the following command:
kubectl -n morpheus create job train --from=cronjob/dfp-training
You should then see a training pod running within the namespace. Run the command below to check the pod status. Wait for this train pod to show a Completed status before proceeding. This should only take a few minutes.
kubectl -n morpheus get pods

After this initial command, training jobs are submitted as a cronjob on a regular schedule, set by default to Sundays at 3 am. This value can be modified in the values.yaml of the helm chart for the workflow.
This training session consists of two pipelines that run in parallel. One pipeline trains a generic model, and the other trains per-user models, where custom models are trained per detected user ID. The trained models and associated information are stored in MLflow.
MLflow can be accessed using the link provided in the left pane.
Looking more closely at the training pipeline. Before executing training, there is a pre-processing stage. The following graphic highlights the multiple stages within the pipeline:
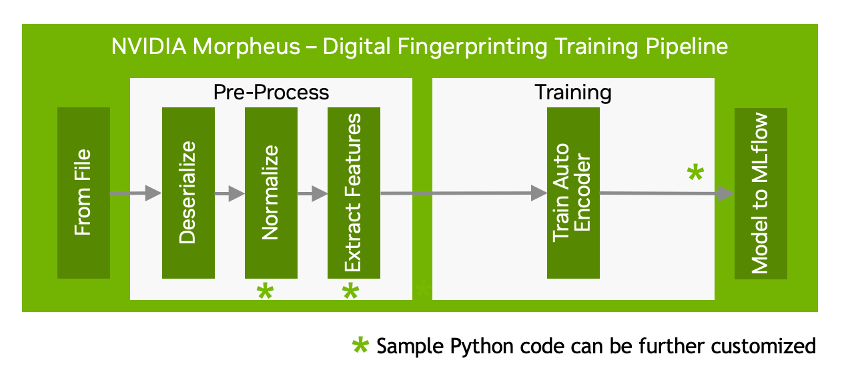
Within this digital fingerprinting workflow, sample Python code is deployed as a part of the training pipeline to run the pre-processing stages below. This sample code is also available as source code which can be further customized by the developer.
NVIDIA AI Enterprise licensing is required for accessing AI Workflow resources, including source code.
Normalize
Extract Features