Overview
Welcome to the trial of NVIDIA AI Workflows on NVIDIA LaunchPad.
NVIDIA AI Workflows are available as part of NVIDIA AI Enterprise – an end-to-end, secure, cloud-native suite of AI software, enabling organizations to solve new challenges while increasing operational efficiency. Organizations start their AI journey by using the open, freely available NGC libraries and frameworks to experiment and pilot. When they’re ready to move from pilot to production, enterprises can easily transition to a fully managed and secure AI platform with an NVIDIA AI Enterprise subscription. This gives enterprises deploying business-critical AI the assurance of business continuity with NVIDIA Enterprise Support and access to NVIDIA AI experts.
Within this LaunchPad lab, you will gain experience with AI workflows that can accelerate your path to AI outcomes. These are packaged AI workflow examples that include NVIDIA SDKs, AI frameworks, and pre-trained models, as well as resources such as helm charts, Jupyter notebooks, and documentation to help you get started in building AI-based solutions. NVIDIA’s cloud-native AI workflows run as microservices that can be deployed on Kubernetes alone or with other microservices to create production-ready applications.
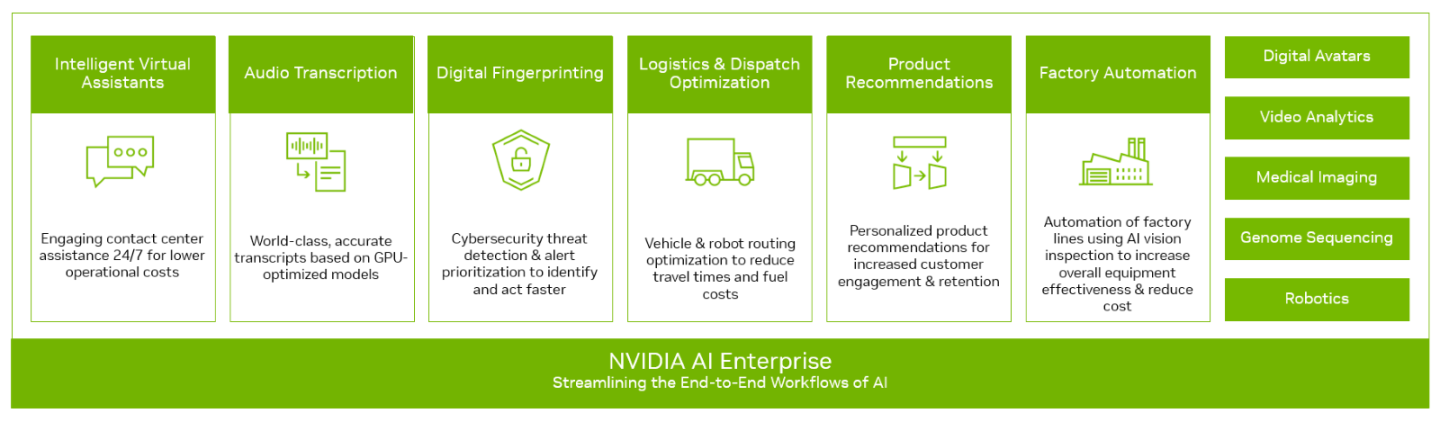
Key Benefits:
Reduce development time at a lower cost
Improve accuracy and performance
Gain confidence in outcomes by leveraging NVIDIA expertise
NVIDIA AI Workflows are intended to provide reference solutions for leveraging NVIDIA frameworks to build AI solutions for solving common use cases. These workflows guide fine-tuning and AI model creation to build upon NVIDIA frameworks. The pipelines to create applications are highlighted, as well as guidance on deploying customized applications and integrating them with various components typically found in enterprise environments, such as components for orchestration and management, storage, security, networking, etc.
NVIDIA AI Workflows are available on NVIDIA NGC for NVIDIA AI Enterprise software customers.
NVIDIA AI Workflows are deployed as a package containing the AI framework and tools for automating a cloud-native solution. AI Workflows also have packaged components that include enterprise-ready implementations with best practices that ensure reliability, security, performance, scalability, and interoperability while allowing a path for you to deviate.
A typical workflow may look like the following diagram:
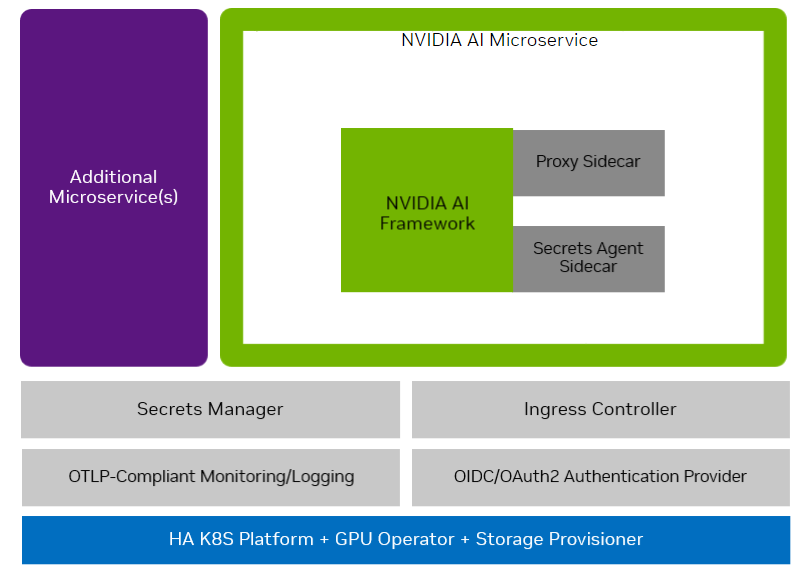
The components and instructions used in the workflow are intended to be used as examples for integration and may need to be sufficiently production-ready on their own, as stated. The workflow should be customized and integrated into one’s infrastructure, using the workflow as a reference. For example, all of the instructions in these workflows assume a single node infrastructure, whereas production deployments should be performed in a high availability (HA) environment.
This reference AI workflow for session-based next-item prediction shows how to use NVIDIA Merlin, an end-to-end framework for building high-performing recommender systems at scale. A session-based recommendation is the next-generation AI method that predicts the next action – it predicts preferences from contextual user interactions for first-time, early, or anonymous online users. One of the biggest challenges of building a recommender is the lack of historical interaction data. With session-based recommender systems, little or no online user historical data is required. By providing recommendations based on very recent user interactions from the current session, it is much easier to provide accurate predictions, solve user cold-start, comply with privacy restrictions, and address real-time trends.
Building a recommendation system that suggests a next “item” for an end user (for example, suggesting a next workout on Peloton or suggesting the next advertisement to show on Snapchat) is much more complex than training a single model and deploying it. Full recommendation systems require a variety of components, and in this reference workflow, we implement the necessary pieces to build a session-based recommender system to serve user’s appropriate items.
This NVIDIA AI Workflow contains the following:
Training and inference pipelines based on NVIDIA Merlin and Triton Inference Server.
Integrated components for storage, authentication, logging, and monitoring the workflow.
Cloud Native deployable bundle packaged as helm charts.
Using the above assets, this NVIDIA AI Workflow provides a reference for you to build your own AI solution with minimal preparation and includes enterprise-ready implementation best practices which range from authentication, monitoring, reporting, and load balancing, helping you achieve the desired AI outcome faster while still allowing a path for you to deviate.
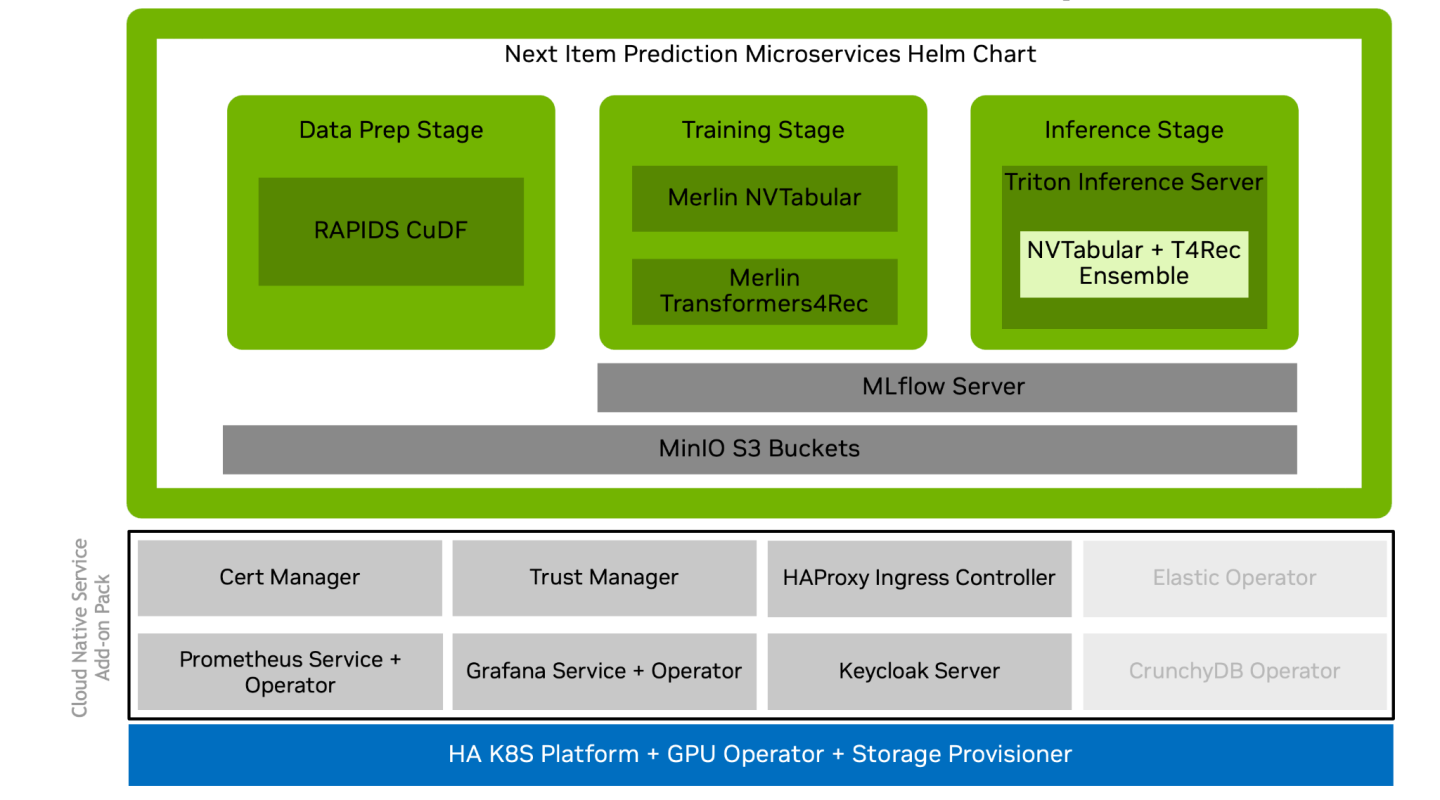
NVIDIA AI Workflows are designed as microservices. They can be deployed on Kubernetes alone or with other microservices to create a production-ready application for seamless scaling in your enterprise environment.
The following cloud-native Kubernetes services are used with this workflow:
NVIDIA Merlin
MLflow
Prometheus
Grafana
MinIO for S3 Compatible Object Storage
These components are used to build and deploy training and inference pipelines, integrated with the additional components as indicated in the below diagram:
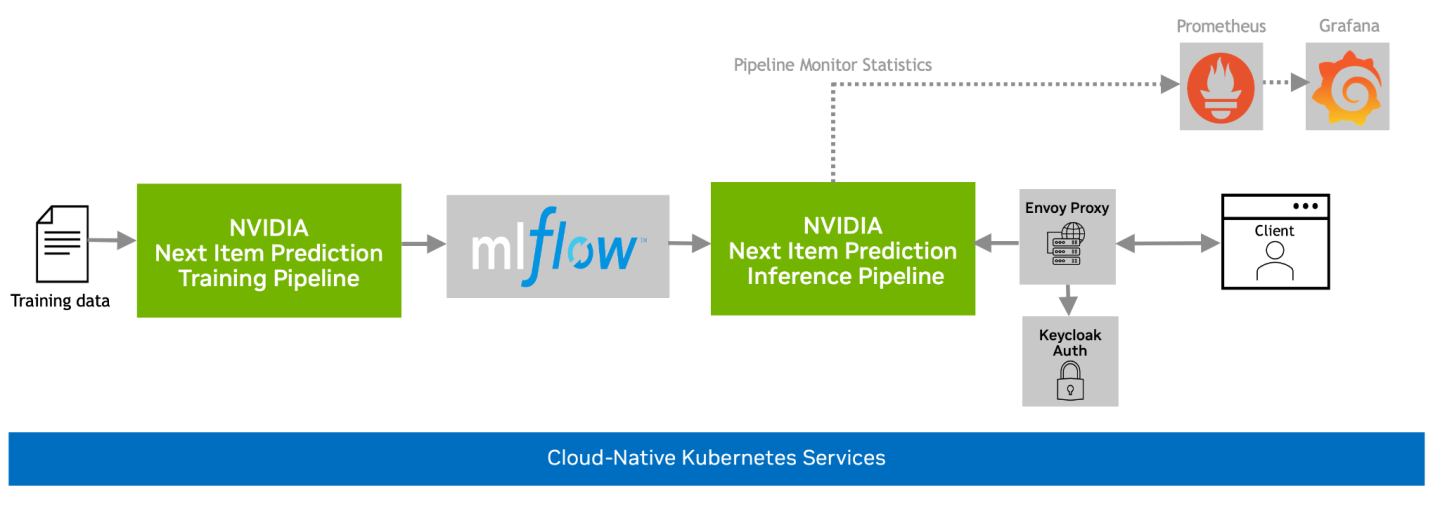
The following sections describe these NVIDIA AI components further.
Data Preparation
In this workflow, you will use a dataset with similar characteristics to the yoochoose dataset from the 2015 Recsys Challenge. More information is available about the dataset on Kaggle here.
We use a script to generate 1,000,000 user/item interactions per day for an 85 day period. The columns in the generated data set are:
Session ID - the id of the session. In one session there are one or many buying events. Could be represented as an integer number.
Timestamp - the time when the buy occurred. Format of YYYY-MM-DDThh:mm:ss.SSSZ
Item ID - the unique identifier of item that has been bought.
Category - the context of the click. This could be an item category i.e.
sport.
Training the Recommendation System
The next-item prediction training pipeline includes both preprocessing with Merlin NVTabular and model training with Merlin Transformers4Rec. Both the preprocessing workflow and the trained model are stored within a model repository using MLflow, which will be used later for inference.
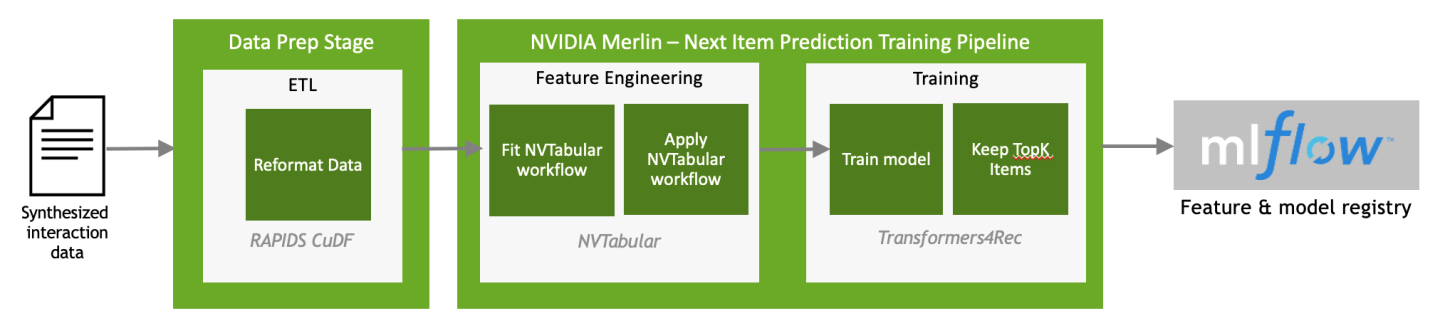
- Data Preprocessing
- Training
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems. The preprocessing and feature engineering pipeline (ETL) is executed using NVTabular.
Merlin Transformers4Rec is designed to make state-of-the-art session-based recommendations available for recommender systems. It leverages HuggingFace’s Transformers NLP library to make it easy to use cutting-edge implementations of the latest NLP Transformer architectures in your recommendation systems. A session-based recommendation model is trained with a Transformer architecture (XLNET) with masked language modeling (MLM) using Merlin’s Transformers4Rec library.
Deploying the Recommendation System
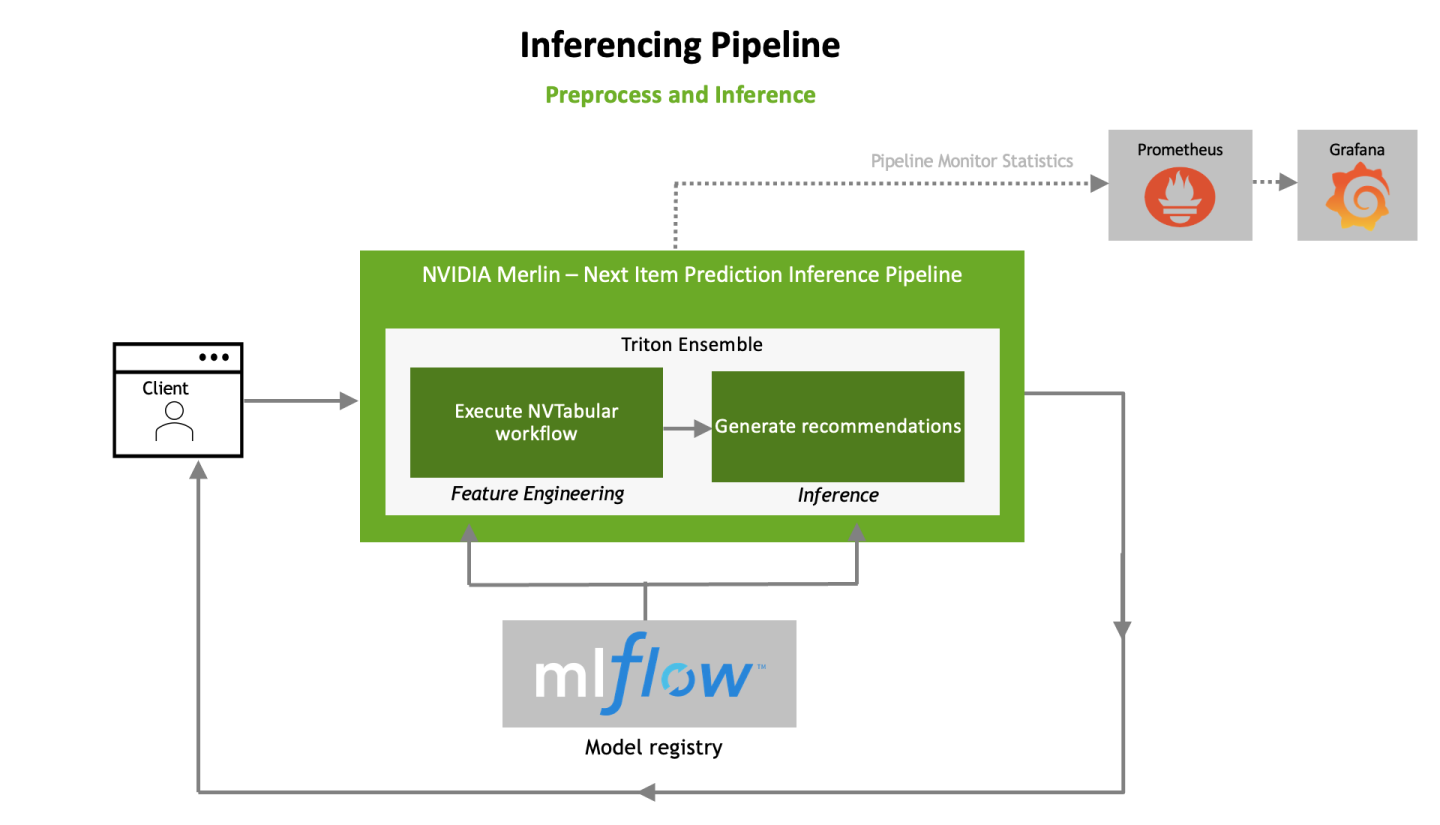
- Data Processing and Inference
- Post-Process
Merlin simplifies the deployment of recommender systems to the Triton Inference Server. Both the pre-processing workflow and trained model are deployed to Nvidia’s Triton Inference server as an ensemble, so features can be transformed in real-time during inference requests. Not only does deployment become simpler, but Triton also maximizes the throughput of requests through the configuration of latency and GPU utilization.
The Transformers4Rec library comes with utility functions to use not only during training, but also in inference pipelines (for example, viewing the top-k recommendations for easy parsing of results).
For more information about all of these components built for the workflow, please review the Next Item Prediction Development Guide. Proceed to the next section to begin running through this workflow.
To assist you in your LaunchPad journey, there are a couple of important links on the left-hand navigation pane of this page. The lab steps in the next few sections will reference these links.