Kubernetes
Kubernetes is an open source container orchestration platform that makes the job of a devops engineer easier. Applications can be deployed on Kubernetes as logical units which are easy to manage, upgrade and deploy with zero downtime (rolling upgrades) and high availability using replication. NVIDIA AI Enterprise applications are available as containers and can be deployed in a cloud native way on Kubernetes. Deploying Triton Inference Server on Kubernetes offers these same benefits to AI in the Enterprise. In order to easily manage GPU resources in the cluster, the NVIDIA GPU operator is leveraged.
The GPU Operator allows administrators of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster. The AI practitioner doesn’t concern themselves with installation of the GPU operator and it is done by the dev ops admin maintaining the cluster. So, for this lab the GPU operator has been automatically installed on your cluster.
Since Kubernetes does not run containers directly it wraps one or more containers into a higher level called Pods. A Kubernetes Pod is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. Pods are also typically managed by a layer of abstraction, the Deployment. Using a Deployment you don’t have to deal with pods manually, it can create and destroy Pods dynamically. A Kubernetes Deployment manages a set of pods as a replica set.
Multiple replicas of the same pod can be used to provide high availability. Using Kubernetes to deploy a Triton Inference Server offers these same benefits to AI in the Enterprise. Because the deployment has replication, if one of the Triton inference server pods fails, other replica pods which are part of the deployment can still serve the end user. Rolling updates allows Deployment updates to take place, such as upgrading an application, with zero downtime.
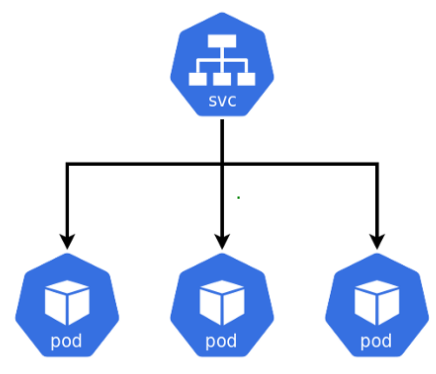
Each Pod gets its own IP address. However in a Deployment, the set of Pods running in one moment in time could be different from the set of Pods running that application a moment later. Because pods/containers fail all the time, Kubernetes will bring them up with a different IP. This leads to a problem: if some set of Pods (call them “backends”) provides functionality to other Pods (call them “frontends”) inside your cluster, how do the frontends find out and keep track of which IP address to connect to, so that the frontend can use the backend part of the workload?
We do that through services. The services inside a Kubernetes cluster maintain static IPs so you can always point to them and they will relay the request to the pods.
An application deployed on Kubernetes can have multiple types of pods, services, deployments objects (micro services). For example this lab has a training Jupyter notebook pod, a Triton inference server pod and a client application pod, There are services for each of the pods, objects for Ingress, NGC secrets and so on. All these individual parts of an application can be neatly packaged into a Helm chart and can be deployed on a Kubernetes cluster as a single click install. A helm chart to Kubernetes is what an apt package is to Ubuntu. For this lab, the helm chart has already been installed for you on top of the Openshift cluster. The clean up section in Next Steps part of the lab shows you how you can delete and install the lab helm chart.