Triton Inference Server Overview
Now that you have has successfully trained and saved the model, the next step is to deploy the model to Triton Inference Server. Within this next section of the lab, you will become familiar with the key elements for successfully deploying trained models to Triton Inference Server for Sentiment Analysis. We are leveraging the same VM to train the model and run Triton Inference Server for this lab.
Triton Inference Server
Triton Inference Server simplifies the deployment of AI models by serving inference requests at scale in production. It lets teams deploy trained AI models from any framework (TensorFlow, NVIDIA® TensorRT, PyTorch, ONNX Runtime, or custom) in addition to any local storage or cloud platform GPU- or CPU-based infrastructure (cloud, data center, or edge).
Model Repository
The model repository is a directory where we store the models deployed by the Triton Inference Server for Inference. A model repository is a folder that has the structure below. For more information about the Triton model, repository format, see here.
With all the files explained below, the model repository has already been preloaded into the VM for the lab walkthrough.
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
Why use the RAPIDS tokenizer inside Triton Inference Server?
Within this lab, you will leverage the RAPIDS Tokenizer you created in the previous step. The GPU can pre-process and post-process the data before executing inference on Triton by using the tokenizer. With the latest NVIDIA GPUs and tokenization, inference performance for Deep learning models is quick.
RAPIDS and PyTorch Ensemble Inside Triton Inference Server
Since Triton has a Python backend, it makes deploying RAPIDS models on Triton easy. For our use case, the server will host three models in an ensemble fashion.
The RAPIDS tokenizer model
The PyTorch sentiment analysis model
The combined model 1 and 2
When Triton Inference Server receives text input from the user, the RAPIDS tokenizer gets the input, then tokenizes the input into input_ids and attention_masks which are explained in greater detail in the below section. These get passed to the BERT sentiment analysis model we trained above. The BERT model outputs the final user sentiment.
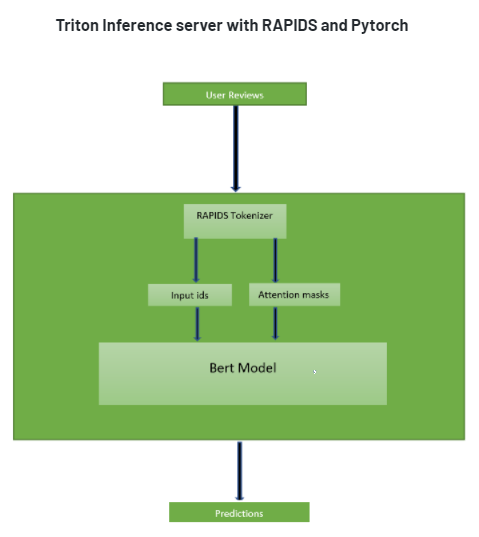
Sentiment Analysis Model Repository Format
Following the Triton Inference Server model repository format, the sentiment analysis model repository format is as follows.
models/
rapids_tokenizer/
config.pbtxt
1/
model.py
sentiment_analysis_model/
config.pbtxt
1/
model.py
end_to_end_model/
config.pbtxt
The contents of each file of the model are explained below. Let’s go through all the models in the model repository one by one.
The entire model repository code is available here.
Each model in a model repository must include a model configuration that provides required and optional information about the model. Typically, this configuration is provided in a config.pbtxt file specified as ModelConfig protobuf.
CONFIG.PBTXT
Config file for RAPIDS tokenizer model with the contents below:
name: "rapids_tokenizer"
backend: "python"
input [
{
name: "product_reviews"
data_type: TYPE_STRING
dims: [-1]
}
]
output [
{
name: "input_ids"
data_type: TYPE_INT32
dims: [ -1, 256]
},
{
name: "attention_mask"
data_type: TYPE_INT32
dims: [-1, 256]
},
{
name: "metadata"
data_type: TYPE_INT32
dims: [ -1, 3]
}
]
instance_group [{ kind: KIND_GPU }]
A minimum model configuration file should specify the input and output size the model expects and the backend type. In our case, the model expects an input of type string and size -1 which, means the size is defined at runtime.
The model gives three outputs; input_ids, attention_mask, and metadata.
Input_ids are the Input IDs are the indices corresponding to each token in our input sentence.
The attention_mask points out which tokens the model should pay attention to and which ones it should not (because they represent padding in this case). It is “1” if the corresponding input_ids are present and “0” if the input ids are padded to “0”.
The size of these two vectors is [-1,256], which means the batch size is determined at runtime, but the tensors themselves are 256 ints.
Metadata is “data that provides information about other data”, but not the content of the data, such as the text of a message or the image itself.
MODEL.PY
All the functions of the model.py file are explained below as well as in the code itself. Every Python Triton Inference Server model must have the same class name, ‘TritonPythonModel’. The class itself has three functions: initialize(), execute(), and finalize().
Initialize() is only called once when the model is being loaded. Implementing the initialize function is optional. This function allows the model to initialize any state associated with this model.
Execute() MUST be implemented in every Python model. The execute function receives a list of pb_utils.InferenceRequest is the only argument. This function is called when an inference request is made for the model. Depending on the batching configuration (e.g., DynamicBatching), requests may contain multiple requests. Every Python model must create one pb_utils.InferenceResponse for every pb_utils.InferenceRequest in requests. If there is an error, you can set the error argument when creating a pb_utils.InferenceResponse
Finalize() is only called once when the model is being unloaded. Implementing the finalize function is OPTIONAL. This function allows the model to perform any necessary clean-ups before exit.
The following contents exist in the model.py file.
import numpy as np
import sys
import json
from pathlib import Path
# triton_python_backend_utils is available in every Triton Python model. You
# need to use this module to create inference requests and responses. It also
# contains some utility functions for extracting information from model_config
# and converting Triton input/output types to numpy types.
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""Your Python model must use the same class name. Every Python model
that is created must have "TritonPythonModel" as the class name.
"""
def initialize(self, args):
"""`initialize` is called only once when the model is being loaded.
Implementing `initialize` function is optional. This function allows
the model to initialize any state associated with this model.
Parameters
----------
args : dict
Both keys and values are strings. The dictionary keys and values are:
* model_config: A JSON string containing the model configuration
* model_instance_kind: A string containing model instance kind
* model_instance_device_id: A string containing model instance device ID
* model_repository: Model repository path
* model_version: Model version
* model_name: Model name
"""
# You must parse model_config. JSON string is not parsed here
self.model_config = json.loads(args['model_config'])
self.model_instance_device_id = json.loads(args['model_instance_device_id'])
import numba.cuda as cuda
cuda.select_device(self.model_instance_device_id)
import cudf
from cudf.core.subword_tokenizer import SubwordTokenizer
# get vocab
v_p = Path(__file__).with_name('vocab_hash.txt')
self.cudf_tokenizer = SubwordTokenizer(v_p, do_lower_case=True)
self.cudf_lib = cudf
self.seq_len = 256
def execute(self, requests):
"""`execute` MUST be implemented in every Python model. `execute`
function receives a list of pb_utils.InferenceRequest as the only
argument. This function is called when an inference request is made
for this model. Depending on the batching configuration (e.g. Dynamic
Batching) used, `requests` may contain multiple requests. Every
Python model, must create one pb_utils.InferenceResponse for every
pb_utils.InferenceRequest in `requests`. If there is an error, you can
set the error argument when creating a pb_utils.InferenceResponse
Parameters
----------
requests : list
A list of pb_utils.InferenceRequest
Returns
-------
list
A list of pb_utils.InferenceResponse. The length of this list must
be the same as `requests`
"""
responses = []
# Every Python backend must iterate over everyone of the requests
# and create a pb_utils.InferenceResponse for each of them.
for request in requests:
# Get INPUT0
raw_strings = pb_utils.get_input_tensor_by_name(request, "product_reviews").as_numpy()
str_ls = [s.decode() for s in raw_strings]
str_series = self.cudf_lib.Series(str_ls)
### Use RAPIDS
cudf_output = self.cudf_tokenizer(str_series,
max_length=self.seq_len,
max_num_rows=len(str_series),
padding="max_length",
return_tensors="cp",
truncation=True,
add_special_tokens=False)
# Create output tensors. You need pb_utils.Tensor
# objects to create pb_utils.InferenceResponse.
### Wont need .get() conversion in newer releases
### see PR https://github.com/triton-inference-server/python_backend/pull/62
out_tensor_0 = pb_utils.Tensor("input_ids", cudf_output['input_ids'].get().astype(np.int32))
out_tensor_1 = pb_utils.Tensor("attention_mask", cudf_output['attention_mask'].get().astype(np.int32))
out_tensor_2 = pb_utils.Tensor("metadata", cudf_output['metadata'].get().astype(np.int32))
# Create InferenceResponse. You can set an error here in case
# there was a problem with handling this inference request.
# Below is an example of how you can set errors in inference
# response:
#
# pb_utils.InferenceResponse(
# output_tensors=..., TritonError("An error occured"))
inference_response = pb_utils.InferenceResponse(
output_tensors=[out_tensor_0, out_tensor_1,out_tensor_2])
responses.append(inference_response)
# You should return a list of pb_utils.InferenceResponse. Length
# of this list must match the length of `requests` list.
return responses
def finalize(self):
"""`finalize` is called only once when the model is being unloaded.
Implementing `finalize` function is OPTIONAL. This function allows
the model to perform any necessary clean ups before exit.
"""
print('Cleaning up...')
CONFIG.PBTXT
The config file for the Sentiment Analysis model with the contents below.
name: "sentiment_analysis_model"
backend: "python"
input [
{
name: "input_ids"
data_type: TYPE_INT32
dims: [ -1, 256]
},
{
name: "attention_mask"
data_type: TYPE_INT32
dims: [-1, 256]
}
]
output [
{
name: "preds"
data_type: TYPE_INT64
dims: [ -1]
}
]
instance_group [{ kind: KIND_GPU }]
The config.pbtxt file contains a few entries. The name of the model. The type of the model and the input and output parameters. A minimum model configuration file should also specify the input and output size the model expects and the backend type. In our case, the model expects an input of type string and size -1, which means the size is defined at runtime.
The sentiment analysis model receives the input_ids and attention_mask as inputs which are the outputs of the previous rapids_tokenizer model. The sizes remain the same as the last model output size, i.e., [-1, 256]. The sentiment analysis model outputs the prediction, an output of two-class classification, i.e., negative or positive sentiment.
MODEL.PY
All the functions of the model.py file are explained below in the code itself. Every Python Triton inference server model must have the same class name, TritonPythonModel. The class itself has three functions: initialize(), execute(), and finalize().
Initialize() is called only once when the model is being loaded. Implementing the initialize function is optional. This function allows the model to initialize any state associated with this model.
Execute() MUST be implemented in every Python model. The execute function receives a list of pb_utils.InferenceRequest as the only argument. This function is called when an inference request is made for this model. Depending on the batching configuration (e.g., DynamicBatching), requests may contain multiple requests. EveryPython model must create one pb_utils.InferenceResponse for every pb_utils.InferenceRequest in requests. If there is an error, you can set the error argument when creating a pb_utils.InferenceResponse
Finalize() is called only once when the model is being unloaded. Implementing the finalize function is OPTIONAL. This function allows the model to perform any necessary cleanups before exit.
We define the BERT_Arch the same way we defined it in the Training Jupiter Notebook, which is loaded in the initialize step of the TritonPythonmodel class.
import json
from torch import nn
import torch
import triton_python_backend_utils as pb_utils
from pathlib import Path
from transformers import BertModel
class BERT_Arch(nn.Module):
def __init__(self):
super(BERT_Arch, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.dropout = nn.Dropout(0.1)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(768,512)
self.fc2 = nn.Linear(512,2)
self.softmax = nn.LogSoftmax(dim=1)
#define the forward pass
def forward(self, sent_id, mask):
#pass the inputs to the model
_, cls_hs = self.bert(sent_id, attention_mask=mask, return_dict=False)
x = self.fc1(cls_hs)
x = self.relu(x)
x = self.dropout(x)
# output layer
x = self.fc2(x)
# apply softmax activation
x = self.softmax(x)
return x
class TritonPythonModel:
"""Your Python model must use the same class name. Every Python model
that is created must have "TritonPythonModel" as the class name.
"""
def initialize(self, args):
"""`initialize` is called only once when the model is being loaded.
Implementing `initialize` function is optional. This function allows
the model to initialize any state associated with this model.
Parameters
----------
args : dict
Both keys and values are strings. The dictionary keys and values are:
* model_config: A JSON string containing the model configuration
* model_instance_kind: A string containing model instance kind
* model_instance_device_id: A string containing model instance device ID
* model_repository: Model repository path
* model_version: Model version
* model_name: Model name
"""
# You must parse model_config. JSON string is not parsed here
self.model_config = model_config = json.loads(args['model_config'])
self.model_instance_device_id = json.loads(args['model_instance_device_id'])
self.device = torch.device("cuda:{}".format(self.model_instance_device_id) if torch.cuda.is_available() else "cpu")
model = BERT_Arch()
# Load saved model
m_p = Path(__file__).with_name('model.pt')
model.load_state_dict(torch.load(m_p))
model = model.eval()
self.model = model.to(self.device)
def execute(self, requests):
"""`execute` must be implemented in every Python model. `execute`
function receives a list of pb_utils.InferenceRequest as the only
argument. This function is called when an inference is requested
for this model. Depending on the batching configuration (e.g. Dynamic
Batching) used, `requests` may contain multiple requests. Every
Python model, must create one pb_utils.InferenceResponse for every
pb_utils.InferenceRequest in `requests`. If there is an error, you can
set the error argument when creating a pb_utils.InferenceResponse.
Parameters
----------
requests : list
A list of pb_utils.InferenceRequest
Returns
-------
list
A list of pb_utils.InferenceResponse. The length of this list must
be the same as `requests`
"""
responses = []
# Every Python backend must iterate over everyone of the requests
# and create a pb_utils.InferenceResponse for each of them.
for request in requests:
# Get INPUT0
input_ids = pb_utils.get_input_tensor_by_name(request, "input_ids")
attention_mask = pb_utils.get_input_tensor_by_name(request, "attention_mask")
### Wont Need below conversion in newer releases
### see PR https://github.com/triton-inference-server/python_backend/pull/62
input_ids = torch.Tensor(input_ids.as_numpy()).long().to(self.device)
attention_mask = torch.Tensor(attention_mask.as_numpy()).long().to(self.device)
with torch.no_grad():
outputs = self.model(input_ids, attention_mask)
conf, preds = torch.max(outputs, dim=1)
# Create output tensors. You need pb_utils.Tensor
# objects to create pb_utils.InferenceResponse.
out_tensor_0 = pb_utils.Tensor("preds", preds.cpu().numpy())
# Create InferenceResponse. You can set an error here in case
# there was a problem with handling this inference request.
# Below is an example of how you can set errors in inference
# response:
#
# pb_utils.InferenceResponse(
# output_tensors=..., TritonError("An error occured"))
inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor_0])
responses.append(inference_response)
# You should return a list of pb_utils.InferenceResponse. Length
# of this list must match the length of `requests` list.
return responses
def finalize(self):
"""`finalize` is called only once when the model is being unloaded.
Implementing `finalize` function is optional. This function allows
the model to perform any necessary clean ups before exit.
"""
print('Cleaning up...')
CONFIG.PBTXT
The end-to-end model config.pbtxt file is the culmination of both the models we defined earlier, which takes input as the input of the rapids_tokenizer(product_reviews) and output as the output from sentiment_analysis_model(preds). We also define the regular entries name, platform, etc. Here the platform is defined as an ensemble because it uses both the rapids_tokenzier and sentiment_analysis_model in a pipeline fashion. This is defined in the ensemble_scheduling part of the config.pbtxt file below.
name: "end_to_end_model"
platform: "ensemble"
max_batch_size: 128
input [
{
name: "product_reviews"
data_type: TYPE_STRING
dims: [ -1 ]
}
]
output [
{
name: "preds"
data_type: TYPE_INT64
dims: [ -1]
}
]
ensemble_scheduling {
step [
{
model_name: "rapids_tokenizer"
model_version: 1
input_map { key: "product_reviews"
value: "product_reviews"
}
output_map { key: "input_ids"
value: "input_ids"
}
output_map { key: "attention_mask"
value: "attention_mask"
}
},
{
model_name: "sentiment_analysis_model"
model_version: 1
input_map {
key: "input_ids"
value: "input_ids"
}
input_map {
key: "attention_mask"
value: "attention_mask"
}
output_map {
key: "preds"
value: "preds"
}
}
]
}