Megatron-FSDP#
✨ Overview#
Megatron-FSDP is an NVIDIA-developed distributed parallelism library written in native PyTorch that provides a high-performance implementation of Fully Sharded Data Parallelism (FSDP). It offers seamless cross-compatibility with various deep learning frameworks and parallelism libraries such as Megatron-Core, and is performance-optimized to support training and inference of extremely large PyTorch models at data-center scale on NVIDIA GPUs.
PyPI: https://pypi.org/project/megatron-fsdp/
Source Code: https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/core/distributed/fsdp/src
🧩 Compatibility#
💡 Features#
Performant & Scalable: Optimized for NVIDIA CUDA with efficient memory management and performance. Sports near-linear scaling up from single compute nodes to entire data-centers.
Multiple Algorithms in One: Supports sharding your choice of optimizer states, gradients, and model parameters (FSDP), including hierarchical data parallelism strategies such as Hybrid-Sharded Data Parallelism (HSDP) and Hybrid-FSDP (HFSDP / Fully-Sharded Optimizer State) for optimizing intra-node and inter-node memory, communication, and performance.
“Bring Your Own Parallelism”: Works seamlessly with PyTorch, Megatron-LM, Megatron-Bridge, and TransformerEngine, and can be plugged into other frameworks such as HuggingFace Transformers and TorchTitan.
Simple & Powerful: Similar to PyTorch FSDP, the
fully_shardAPI doesn’t depend on any complex training framework or distributed environment.
⏱️ Optimizations#
TransformerEngine Mixed-Precision & Fused Kernels: Native performance- and memory-optimal compatibility with MXFP8, NVFP4, and various other quantization recipes and fused kernels provided by TransformerEngine.
Advanced Bucketing:
dtype-customizable and precision-aware bucketing system to tune the memory overhead, numerical accuracy, and latency of collectives. Avoids redundantCOPYoperations before and after collectives, while remaining compatible with DTensor features such as Torch Distributed Checkpoint (DCP).Buffer Management: Efficient use of storage and NCCL User Buffer Registration enable direct communication into NCCL-managed memory, achieving true zero-
COPYdata movement. Introduced in NCCLv2.27, NCCL Symmetric Memory communications employ symmetric kernels that drastically reduce SM utilization and include networking optimizations such as high-precision (FP32) reduction over-the-wire.Optimized Communication & SM Utilization via SHARP: Leverages SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) to offload FSDP collectives to network switches (InfiniBand or NVLink-Switch) and significantly reduce utilization of GPU streaming multi-processors (SM) from 16-32 to 1-6 for Multi-Node NVLink (MNNVL) systems (Grace-Blackwell, Vera-Rubin, etc.), which lowers communication latency in large scaled-out workloads and frees up GPU-hosted processors for overlapped compute (GEMM) kernels. When FSDP sharding domains span both NVLink and InfiniBand, hierarchical SHARP collectives (NVL-SHARP and IB-SHARP) optimize communication paths across the entire system topology.
Hybrid-FSDP (HFSDP), a variation of Hybrid-Sharded Data Parallelism (HSDP) that further shards the optimizer state across intra- and inter-node data-parallel ranks, bridges the memory-communication trade-off between HSDP and FSDP, unlocking memory efficiency at minimal cost to performance.
🚀 Quick Start#
📦 Installation#
NeMo Framework Container#
Megatron-FSDP is pre-installed with Megatron-Core in the NVIDIA NeMo Framework Container.
Megatron-Core#
Megatron-FSDP is bundled with Megatron-Core, which can be installed via pip:
# Install via PyPI
pip install --no-build-isolation megatron-core[mlm,dev]
# Install from Source
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
pip install --no-build-isolation .[mlm,dev]
To import Megatron-FSDP in Python:
import megatron.core.distributed.fsdp.src.megatron_fsdp
PyPI#
To install Megatron-FSDP as a standalone package to use the fully_shard API:
pip install megatron-fsdp
To import Megatron-FSDP in Python:
import megatron_fsdp
🎛️ Megatron-FSDP fully_shard#
Megatron-FSDP supports a simple fully_shard API that seamlessly enables FSDP with very few lines of code.
import torch
from megatron_fsdp import (
fully_shard_model,
fully_shard_optimizer,
)
# Initialize Torch Distributed.
torch.distributed.init_process_group()
torch.cuda.set_device(torch.distributed.get_rank())
# Fully-shard the model.
model = torch.nn.Transformer()
fsdp_model = fully_shard_model(
module=model,
fsdp_unit_modules=[
torch.nn.TransformerEncoder,
torch.nn.TransformerDecoder
]
)
# Fully-shard the optimizer.
toy_adam = torch.optim.AdamW(params=fsdp_model.parameters(), lr=0.01)
optimizer = fully_shard_optimizer(optimizer=toy_adam)
# Forward pass.
inp = torch.randn(1, 512, 512).to("cuda")
tgt = torch.randn(1, 512, 512).to("cuda")
output = fsdp_model(inp, inp)
# Backward pass.
torch.nn.functional.mse_loss(output, tgt).backward()
# Optimizer step.
optimizer.step()
optimizer.zero_grad()
# Checkpoint the model and optimizer.
torch.distributed.checkpoint.save({
"model": fsdp_model.state_dict(),
"optimizer": optimizer.state_dict(),
}, checkpoint_id="ckpt/")
# Load the saved checkpoint.
ckpt = {
"model": fsdp_model.state_dict(),
"optimizer": optimizer.state_dict(),
}
torch.distributed.checkpoint.load(state_dict=ckpt, checkpoint_id="ckpt/")
fsdp_model.load_state_dict(ckpt["model"], strict=False)
optimizer.load_state_dict(ckpt["optimizer"])
ℹ️
fully_shardis an experimental API. Please check back for updates as we fine-tune our user experience! For more examples usingfully_shardfor Megatron-FSDP, refer to our suite of unit tests:tests/unit_tests/distributed/megatron_fsdp/test_mfsdp_fully_shard.py
🤖 Megatron-LM#
Megatron-FSDP is deeply integrated into Megatron-Core. To enable FSDP (where optimizer states, gradients, and compute parameters are sharded) in Megatron, use the following arguments:
# Train models in Megatron-LM using Megatron-FSDP.
--use-megatron-fsdp
--data-parallel-sharding-strategy {no_shard, optim, optim_grads, optim_grads_params}
--ckpt-format fsdp_dtensor
Complete Llama-8B and DeepSeek-V3 training scripts using Megatron-FSDP with recommended settings can be found in Megatron-LM/examples/megatron_fsdp.
Recommended Configuration for Megatron-LM#
Frequently-used options use with Megatron-FSDP include:
# Un-set CUDA_DEVICE_MAX_CONNECTIONS to ensure stream independence / full-parallelization of FSDP computation and communication. May slightly affect TP and CP performance though.
unset CUDA_DEVICE_MAX_CONNECTIONS
# Meta-Device Initialization - Load large model onto CUDA devices in shards to avoid OOM.
--init-model-with-meta-device
# Per-Token Loss / No Gradient Scaling - Deactivate DP scaling during gradient reduction, which can be a drain on SM resources.
--calculate-per-token-loss
# Decrease gradient reduction and accumulation precision to recommended data-types based on the precision of the model parameters, usually BF16. Reduces communication volume during the backwards pass. Can be further customized with `--megatron-fsdp-main-grads-dtype` and `--megatron-fsdp-grad-comm-dtype`, which are enabled by this argument.
--grad-reduce-in-bf16
# Register NCCL user buffers and Megatron-FSDP double buffers to enable zero-copy symmetric kernels and low-SM utilization via SHARP. Improves overall performance but increases memory overhead due to double-buffering and is NOT compatible with `PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True`.
--use-nccl-ub
--fsdp-double-buffer
--fsdp-manual-registration
🤖 Megatron-Core#
Megatron-FSDP has a lower-level FullyShardedDataParallel class API that can be used with a simplified version of Megatron-LM’s training loop.
# Initialize model and optimizer.
ddp_config.use_megatron_fsdp = True
# Megatron-FSDP Base Sharding Strategies:
# no_shard, optim, optim_grads, optim_grads_params
ddp_config.data_parallel_sharding_strategy = "optim_grads_params"
model = GPTModel(transformer_config)
model = FullyShardedDataParallel(
transformer_config,
model,
ddp_config,
fsdp_unit_modules = [TransformerLayer, LanguageModelEmbedding],
)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
optimizer = DistributedOptimizer(optimizer, [model], [model.param_and_grad_buffer])
# Training loop
def train_step(inputs, labels):
optimizer.zero_grad()
for mbs_input, mbs_label in zip(inputs, labels):
outputs = model(mbs_input)
loss = loss_fn(outputs, mbs_label)
loss.backward()
optimizer.step()
# Save and load model and optimizer state dict
def model_and_optimizer_state_dict():
state_dict = {
"model": model.sharded_state_dict(),
"optimizer": optimizer.sharded_state_dict(),
}
return state_dict
def load_model_and_optimizer_state_dict(state_dict):
model.load_state_dict(state_dict["model"])
optimizer.load_state_dict(state_dict["optimizer"])
🔁 Checkpoint Conversion#
Megatron-FSDP checkpointing supports PyTorch Distributed Checkpoint (DCP). In Megatron-LM, this is the --ckpt-format fsdp_dtensor checkpointing format.
Converting Torch DCP to Torch Save (Non-Distributed) Checkpoints#
PyTorch has utilities to convert Torch DCP checkpoints to and from regular Torch checkpoints:
python -m torch.distributed.checkpoint.format_utils --help
usage: format_utils.py [-h] {torch_to_dcp,dcp_to_torch} src dst
positional arguments:
{torch_to_dcp,dcp_to_torch}
Conversion mode
src Path to the source model
dst Path to the destination model
options:
-h, --help show this help message and exit
For example:
python -m torch.distributed.checkpoint.format_utils dcp_to_torch dcp_ckpt/ torch_ckpt.pt
or:
from torch.distributed.checkpoint.format_utils import (
dcp_to_torch_save,
torch_save_to_dcp,
)
# Convert DCP model checkpoint to torch.save format.
dcp_to_torch_save(CHECKPOINT_DIR, TORCH_SAVE_CHECKPOINT_PATH)
# Convert torch.save model checkpoint back to DCP format.
torch_save_to_dcp(TORCH_SAVE_CHECKPOINT_PATH, f"{CHECKPOINT_DIR}_new")
Torch Save checkpoints can then be converted into HuggingFace SafeTensors or other checkpoint formats for distribution.
ℹ️ Megatron-FSDP checkpoints have a
module.prefix pre-pended to all model parameter names in the state dictionary, and converting a Torch Save checkpoint to a Megatron-FSDP Torch DCP checkpoint requires testing. Work-in-progress!
Converting N-D Parallel (torch_dist) to Megatron-FSDP (fsdp_dtensor) Checkpoints#
As a pre-requisite for checkpoint conversion, dump the parameter group mapping when training with 3D-parallel (DDP, TP, PP) and/or EP:
--dump-param-to-param-group-map /path/to/param_to_param_group_map
and convert the map to a param_to_param_group_map.json JSON file in the /path/to/param_to_param_group_map directory:
python tools/checkpoint/checkpoint_inspector.py print-torch-dcp-in-json /path/to/param_to_param_group_map
ℹ️ If you already have a
torch_distcheckpoint, simply specify the--dump-param-to-param-group-map /path/to/param_to_param_group_mapflag and run a trivial training or checkpointing experiment to create theparam_to_param_group_mapyou need without full pretraining.
Finally, convert your torch_dist checkpoint to the fsdp_dtensor format using the param_to_param_group_map.json:
torchrun --nproc_per_node=8 --nnodes=1 \
tools/checkpoint/checkpoint_inspector.py \
convert-torch-dist-to-fsdp-dtensor (--swiglu) \ # --swiglu for specific models.
/path/to/input_torch_dist_checkpoint/ \
/path/to/output_fsdp_dtensor_checkpoint/ \
--param-to-param-group-map-json /path/to/param_to_param_group_map.json
ℹ️ For multi-node conversion tasks, please refer to the DeepSeek-V3 example script (
sbatch_checkpoint_convert.sh) in Megatron-LM/examples/megatron_fsdp.
Megatron-FSDP Feature Guide & API#
Optimization |
Description |
|
|
|---|---|---|---|
Megatron-FSDP |
Use Megatron-FSDP in Megatron-LM. |
|
|
Megatron-FSDP Checkpointing |
Save and load un-even DTensor checkpoints using Torch Distributed Checkpoint (DCP). |
|
|
Meta Device Initialization |
Megatron-FSDP initializes a meta-initialized model to the CUDA device in shards to avoid OOM on large models. Requires implementation of |
|
|
Distributed Optimizer |
Megatron-FSDP uses Megatron-Core’s |
|
|
FSDP Fundamentals#
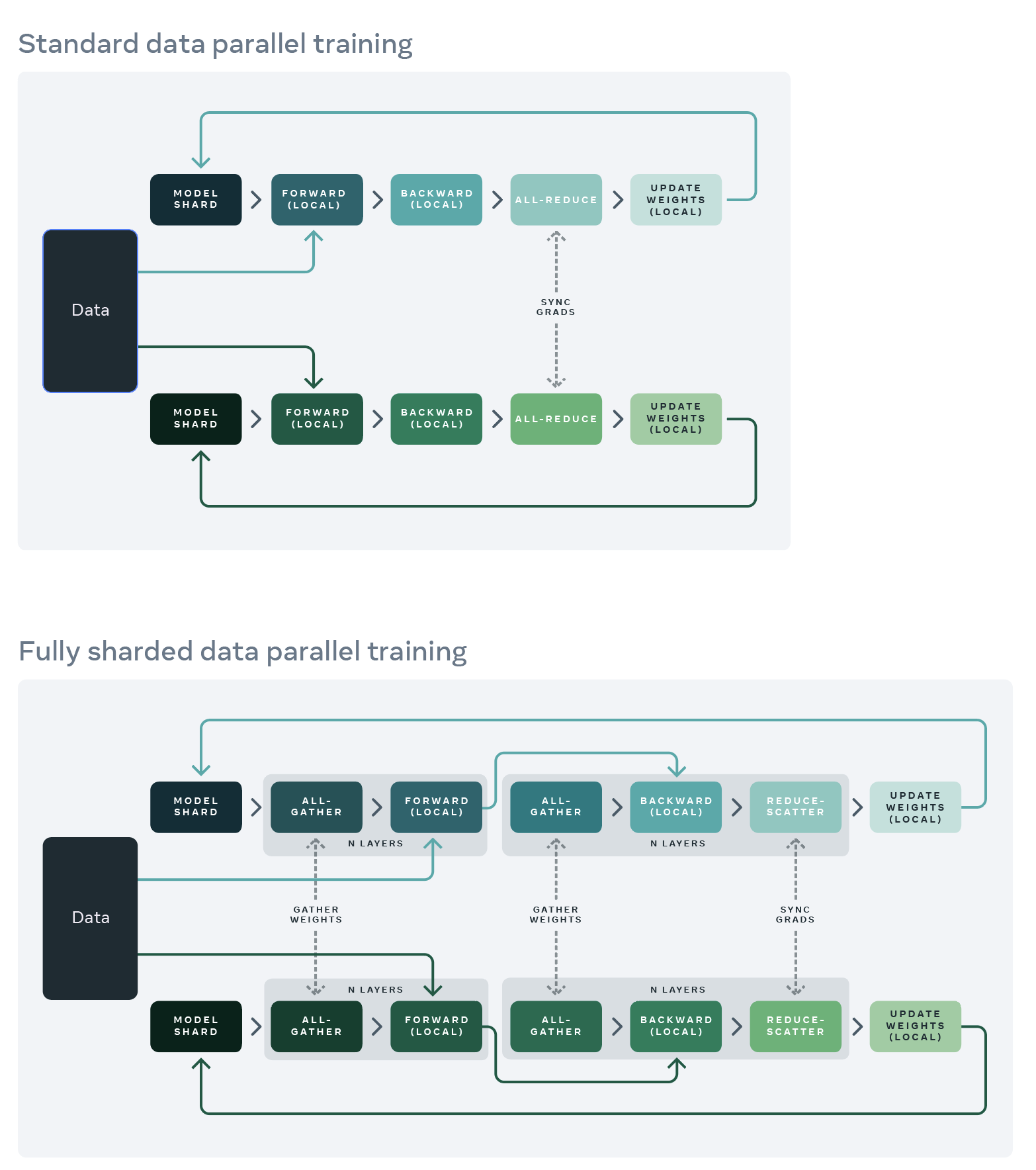
Comparison between Distributed Data Parallelism (DDP) and Fully-Sharded Data Parallelism (FSDP). While gradients are all-reduced in DDP, they are sharded and reduce-scattered with FSDP.#
Source: Meta AI, Ott, Myle, et al. “Fully Sharded Data Parallel: Faster AI Training with Fewer GPUs.” Facebook Engineering, 15 July 2021, https://engineering.fb.com/2021/07/15/open-source/fsdp/.
Fully Sharded Data Parallelism (FSDP) is a type of distributed data parallelism (DDP) that shards optimizer state, weight gradients (wgrad), and model weights across devices that ingest data-parallel samples for data-parallel training or inference. Activations (fprop) and data gradients (dgrad) are not sharded or distributed, and are preserved for the backward pass, but can be recomputed during the backward pass, offloaded to CPU, or sharded / routed using other parallelisms such as tensor parallelism (TP), context parallelism (CP), or expert parallelism (EP).
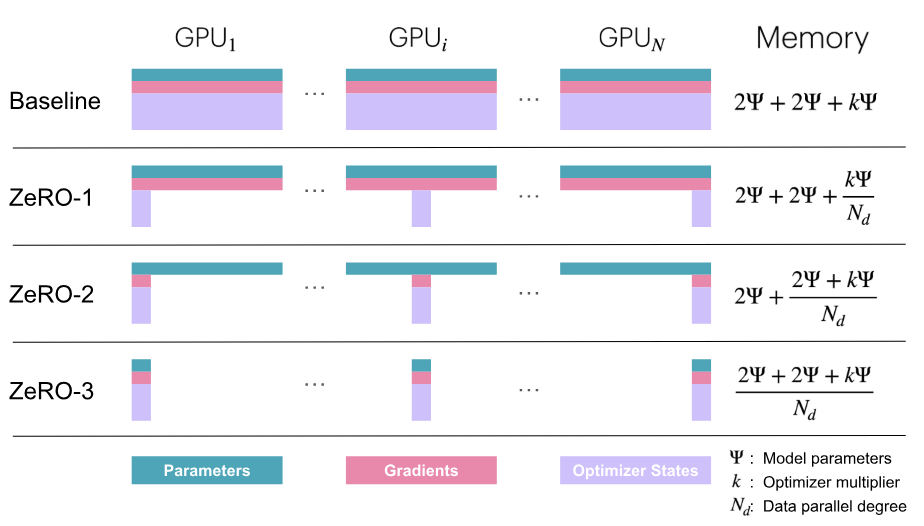
Sharded memory profiles for ZeRO-1 (optimizer state), ZeRO-2 (optimizer state and gradients), and ZeRO-3 (optimizer state, gradients, and parameters).#
Source: Zero-Redundancy Optimizer Model State Partition Diagram. From The Ultra-Scale Playbook: Training LLMs on GPU Clusters by Tazi, Nouamane, et al. HuggingFace, 2025, https://huggingface.co/spaces/nanotron/ultrascale-playbook.
The core principles of FSDP are:
Only a small depth-wise fraction of the model state can exist un-sharded at any point in time.
Communication should overlap computation.
From these core principles, software requirements can be derived:
Model states sharded by FSDP are directly initialized across devices in shards.
Model parameters are all-gathered (AG) in pre-designated groups or modules pre-forward and pre-backward to un-shard a small fraction of the model state at any point in time during training or inference. After
fpropanddgradcomputation, the un-sharded weights are immediately de-allocated.wgradare reduce-scattered (RS) and accumulated in pre-designated groups or modules immediately post-backward to limit the amount of un-sharded gradients at any point in time during training or inference.Distributed optimizers, optimizers that are initialized with respect to a sharded model state and support distributed mechanics, update the sharded model state using the reduced gradient shard to implement data parallelism (DP).
Computation and communication are overlapped across multiple CUDA streams, expending multiple streaming multi-processors (SM). Weights from subsequent groups or modules are pre-fetched, which ideally hides the communication latency required for FSDP behind model computation kernels (GEMM).
FSDP can also be visualized as a decomposition of the all-reduce collective used in DDP into a gradient reduce-scatter, distributed optimization step, and parameter all-gather.
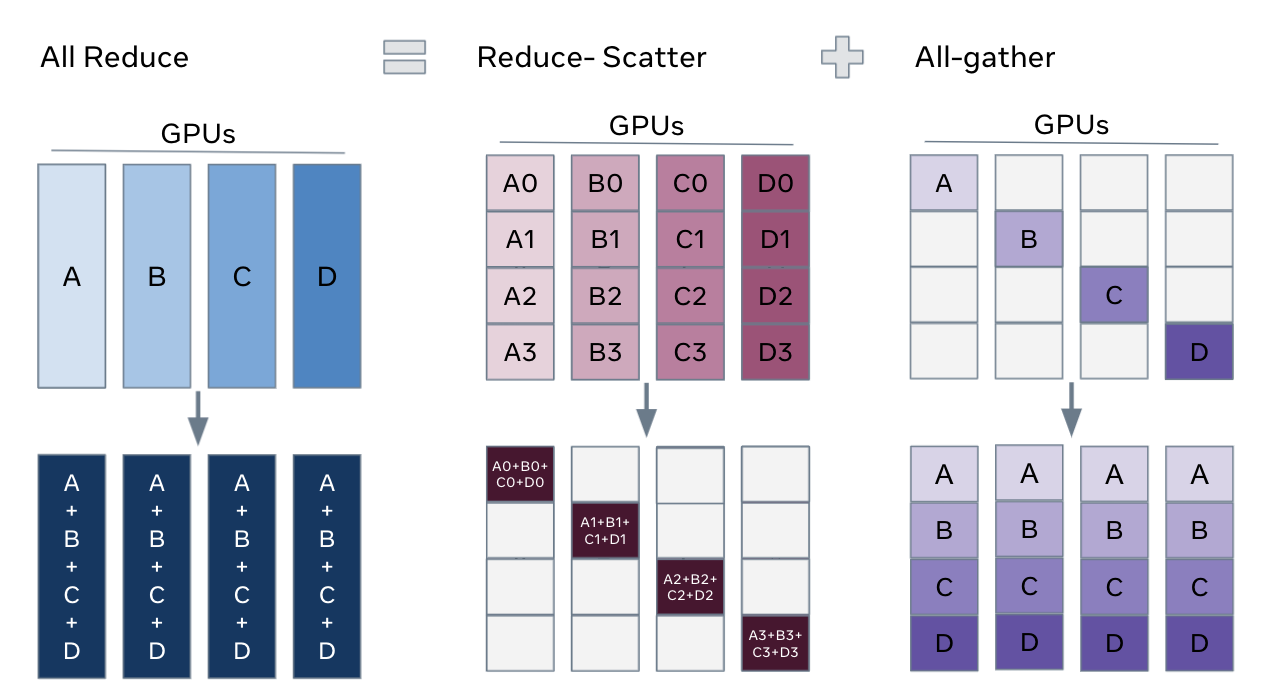
Source: Feng, Wei, Will Constable, and Yifan Mao. “Getting Started with Fully Sharded Data Parallel (FSDP2).” PyTorch Tutorials, 17 Mar. 2022, https://docs.pytorch.org/tutorials/intermediate/FSDP_tutorial.html.#
FSDP Unit Modules#
Optimization |
Description |
|
|
|---|---|---|---|
FSDP Unit Modules |
A list of |
Defaults to supported Megatron-Core modules ( |
|
FSDP Double Buffer Allocator |
Megatron-FSDP uses the double-buffer allocator, which persistently allocates a buffer pair assigned to alternating FSDP units that temporarily stores parameters and gradients. Automatically used with NCCL user buffer registration. |
|
|
Param All-Gather Overlap |
Whether to overlap parameter all-gather with compute. Automatically activated for the ZeRO-3 sharding strategy. |
|
|
Gradient Reduce-Scatter Overlap |
Whether to overlap gradient reduce-scatter or all-reduce with compute. Automatically activated for ZeRO-2 and ZeRO-3 sharding strategies. |
|
|
FSDP Communication Size |
Customize the size (in |
|
N/A (Megatron-Core Only) |
Only a small depth-wise fraction of the model state can exist un-sharded at any point in time.
FSDP Unit Modules represent fractions of the model state that are computed and communicated as a (coalesced) group, un-sharded when needed for computation, and re-sharded after computation to release memory for subsequent model states. Implicitly, an FSDP unit module is also a modeling contract, requiring that FSDP-managed unit module parameters are not accessed or modified beyond the scope of the forward pass, backward pass, or optimization step.
Megatron-FSDP accepts a list of str or class paths representing FSDP unit modules via the fsdp_unit_modules argument, which is currently hard-coded to supported model classes (like TransformerLayer) in Megatron-Core. It performs a depth-first traversal of the model (via torch.nn.Module.named_modules()) and groups the parameters of each matching module for sharding and coalesced communication. Nested units are resolved by precedence: if a module matches an FSDP unit class but is already a sub-module of a previously registered FSDP unit, it is skipped, so the outermost (and necessarily largest) FSDP unit class in any module sub-tree becomes the effective FSDP unit module.
Communication should overlap computation.
Once a model is partitioned into unit modules, computation is overlapped with communication based on the granularity of the FSDP unit module. Depending on the size of the compute and communication kernels, fine-tuning the unit module size and grouping configuration can impact performance and elicit trade-offs between overlap and memory when using FSDP.

Each color-coded block in the compute and communication streams, merged and categorized in the simplified (and worst-case) scenario where SM resources are under contention, correspond to a single FSDP unit module.#
Compute-communication overlaps are orchestrated using CUDA streams that capture and parallelize serial operations. All collectives associated with all combinations of {DP-Inner, DP-Outer} and {AG, RS} are scheduled and tracked with separate streams and communicators / ProcessGroup(s).
Parameters are un-sharded prior to
fpropanddgradcomputation. To overlap the pre-fetch all-gather with computation, at least two FSDP units worth of un-sharded weight memory is required at any point in time.Gradients are reduced and sharded after
wgradcomputation. To overlap gradient reduce-scatter withwgradcomputation, at least two FSDP units worth of un-sharded gradient memory is required at any point in time.
FSDP Module Hooks#
To implement these “unit-periodic” mechanics, Megatron-FSDP uses Module hooks to install a variety of (pre- and post-) forward and backward operations:
Pre-Forward
Un-shards the model parameters of the current and (via pre-fetching) forward-subsequent FSDP unit modules.
When
MegatronFSDP.forward()is invoked, Megatron-FSDP will swap all parameter references to point to the un-shardedTensorcompute weights for the forward and backward pass.
Post-Forward
Re-shards model weights after the forward pass, if the module is an FSDP unit. Non-unit modules remain persistently un-sharded.
When using activation recomputation during the backwards pass, computing both
fpropanddgradrequires these parameters, so parameters are resharded during Post-Backward.
Releases the transpose cache of quantized parameters (in FSDP / ZeRO-3) for specific quantization recipes in
TransformerEngine.
Pre-Backward
Un-shards the model parameters of the current and (via pre-fetching) backward-subsequent FSDP unit modules.
Implemented as a
torch.autograd.graph.register_multi_grad_hooktriggered by the outputdgrad, and installed via aModulepost-forward hook.
Post-Backward
Re-shards model weights after the backward pass, if the module is an FSDP unit. Non-unit modules remain persistently un-sharded.
Implemented by injecting an Autograd function (
RegisterFSDPBackwardFunction) that is installed during aModulepre-forward hook.
Reduces gradients after the backward pass.
Implemented using a
Tensor.register_post_accumulate_grad_hooktriggered byparam.grad, as well as a root-level post-backward hook installed during Pre-Backward (torch.autograd.Variable._execution_engine.queue_callback).
State Dictionary
When
module.state_dict()(for any module managed by Megatron-FSDP) is invoked, Megatron-FSDP will swap all parameter references to point to shardedDTensormain weights for distributed optimization and checkpointing.When
MegatronFSDP.load_state_dict()is invoked, both the main and compute weights are updated. When using quantized model compute, the main weights are quantized and sharded.
Double Buffering#
Megatron-FSDP uses a Tensor._typed_storage()._resize_(bytes)-based allocator to instantly allocate and de-allocate memory without depending on the CUDACachingAllocator for un-sharded parameters and gradients by default. (Cache fragmentation and garbage collection can procrastinate large quantities of cudaMalloc and cudaFree operations that can block programs and spike memory, particularly when memory utilization is maxed out.) However, modifying the underlying storage of a buffer is not compatible with NCCL symmetric registration or CUDA graphability, which require a persistent state during runtime.
To support these optimizations, Megatron-FSDP uses double-buffering, which assigns 2 persistently-allocated buffers to FSDP units in an alternating pattern, hard-limiting the memory overhead for parameter and gradient buffer allocation and ensuring that no more than 2 FSDP units are computed or communicated concurrently.
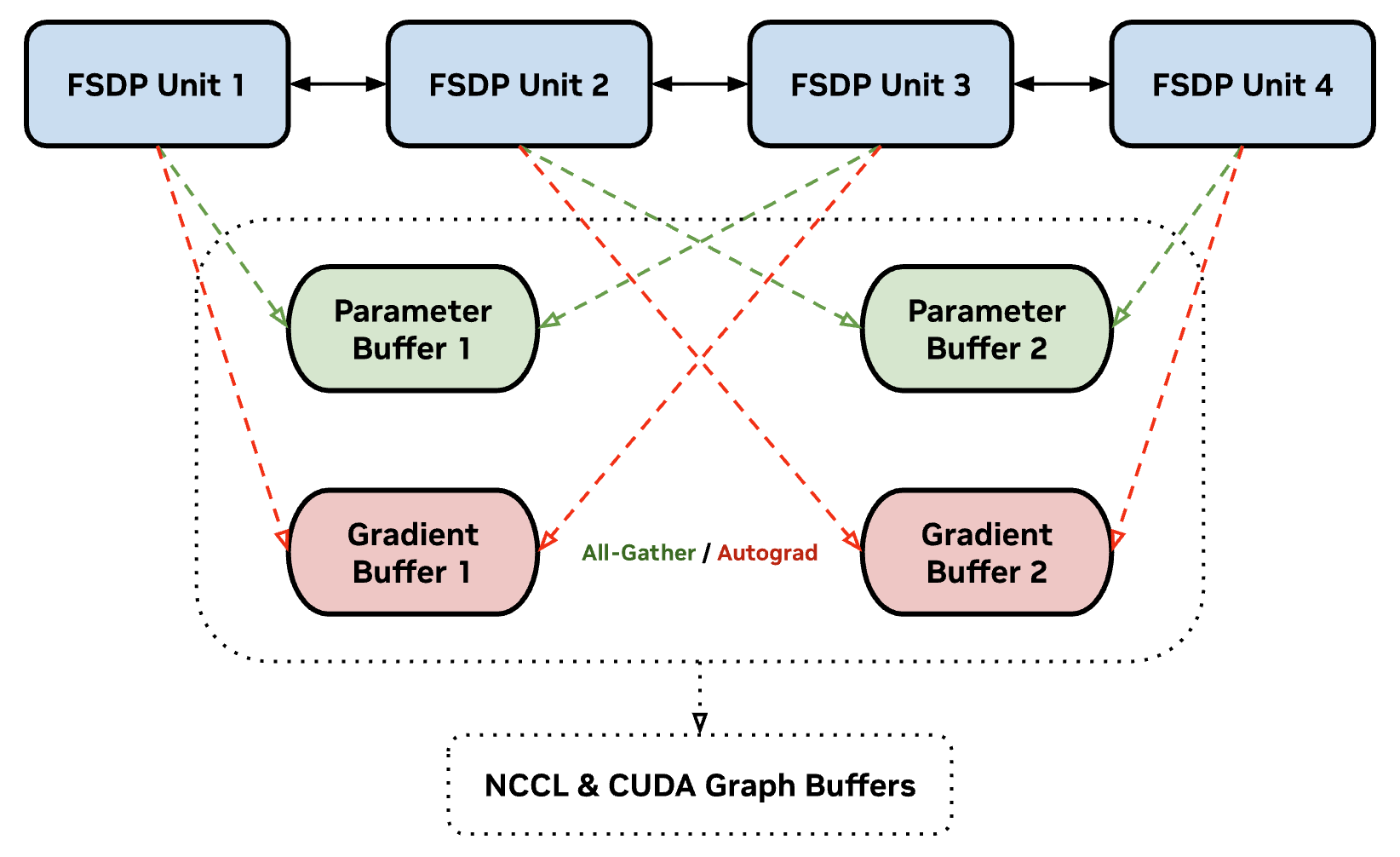
Visualization of double buffering in Megatron-FSDP. Even- and odd-indexed FSDP units share the same un-sharded parameter and gradient buffers, overwriting incumbent data as needed during runtime. Megatron-FSDP ensures that no more than two FSDP units are un-sharded at any point during runtime.#
With double-buffering, Megatron-FSDP does not need to allocate memory after initialization, which can reduce memory fragmentation and improve performance. However, double-buffering requires depth-wise model symmetry, where even- and odd-indexed FSDP units have identical size during runtime. If double-buffering is utilized, Megatron-FSDP computes the mode of FSDP unit sizes as the symmetrical double-buffer size, and any FSDP units not symmetrical to the computed size will default to the _resize_(bytes)-based allocator (or persistently allocated for extremely large and asymmetrical layers that affect performance significantly like torch.nn.Embedding when the low-level argument fsdp_db_use_persist_buf_on_alloc_fail is set).
Data-Parallel Sharding Strategies#
Optimization |
Description |
|
|
|---|---|---|---|
Data Parallel Sharding Strategy |
Primary data-parallel sharding strategy for FSDP, which supports DDP, ZeRO-1 (optimizer), ZeRO-2 (optimizer and gradients), and ZeRO-3 (optimizer, gradients, and parameters). Typically uses intra-node communications, i.e. “inner” or “intra” DP. |
|
|
DP-Outer Sharding Strategy |
Secondary data-parallel sharding strategy for HSDP, which supports Hybrid-Sharded Data Parallel (HSDP / |
|
|
Hybrid Data Parallelism Size |
Specify the DP-Outer / Inter-DP parallel size. DP-Inner / Intra-DP sizes will be deduced from the sizes of other parallelisms and |
|
|
Megatron-FSDP supports a variety of sharding strategies over a variety of distributed topologies:
Distributed Data Parallelism (DDP)
Model state is replicated across DP ranks.
Gradient all-reduce is overlapped with backward compute and launched during the last backward pass before the optimization step.
ZeRO-1
Optimizer state is sharded across DP ranks.
Gradient reduce-scatter is overlapped with backward compute and launched during the last backward pass before the optimization step. (Reduce-scatter is used in lieu of all-reduce for performance, because only a shard of the gradient is needed for optimization.)
ZeRO-2
Optimizer state and gradients are sharded across DP ranks.
Gradient reduce-scatter is overlapped with backward compute and accumulated during every backward pass.
Fully-Sharded Data Parallelism (FSDP / ZeRO-3)
Optimizer state, gradients, and parameters are sharded across DP ranks.
Gradient reduce-scatter is overlapped with backward compute and accumulated during every backward pass.
Hybrid-Sharded Data Parallelism (HSDP)
Optimizer state, gradients, and parameters are sharded across the “inner” or “intra” DP ranks.
Model state is replicated across “outer” / “inter” DP ranks, and outer data-parallel gradients are all-reduced during the last backward pass before the optimization step.
Hybrid-FSDP (HFSDP)
Optimizer state, gradients, and parameters are sharded across the “inner” or “intra” DP ranks.
Optimizer state is further sharded across “outer” / “inter” DP ranks.
Outer data-parallel gradients are reduce-scattered after during the last backward pass before the optimization step.
Outer data-parallel parameters are all-gathered during the first forward pass after the optimization step.
FSDP primary sharding (
optim_grads_params) is required for HFSDP secondary sharding (optim).Requires passing cumulative data-parallel groups (
hybrid_fsdp_group/hybrid_fsdp_expt_group), which include ALL data-parallel ranks, to Megatron-FSDP.To create these using
DeviceMesh, create a data-parallelDeviceMeshfor the cumulative DP group and useDeviceMesh._unflatten(dp_dim, mesh_sizes=(dp_outer_size, dp_inner_size), mesh_dim_names=("dp_outer_dim", "dp_shard_dim"))to construct aDeviceMeshwith DP-Inner and DP-Outer mesh dimensions for Hybrid-FSDP.
Understanding Hybrid-FSDP (HFSDP)#
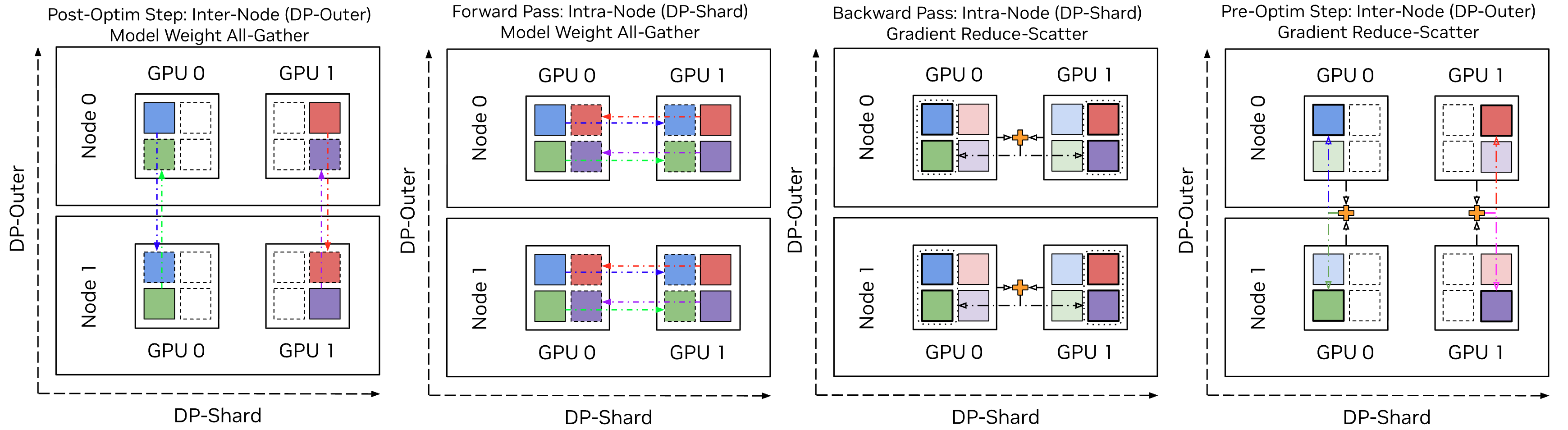
Hybrid-FSDP (HFSDP) is a variation of HSDP where the optimizer state in particular is sharded across both DP-Inner and DP-Outer, i.e. all data-parallel ranks, which further reduces memory utilization. In other words, intra-node sharding and communication uses ZeRO-3, while inter-node sharding and communication uses ZeRO-1. Parameters and gradients are converted from and to the fully-sharded optimizer state during optimization steps only, reducing the frequency of inter-node communications.#
Inspired by the artistry in the DHEN (Zhang, Luo, Liu, Meta, et al., 2022) paper: https://arxiv.org/abs/2203.11014
Hybrid-Fully Sharded Data Parallelism (HFSDP) is a slight modification to HSDP that fully-shards the optimizer state across all data-parallel ranks and introduces outer-level all-gather and reduce-scatter collectives to map fully-sharded parameters and gradients into partially-sharded parameters and gradients.
The memory profile of HFSDP is a “hybrid” of FSDP (optimizer state) and HSDP (gradients and model weights). Another elegant way to understand HFSDP functionality is ZeRO-1 composed with ZeRO-3.
The modified algorithm has the following characteristics:
Megatron-FSDP maintains a view of the model parameters sharded across all data-parallel ranks.
Distributed checkpoints save and load the fully-sharded model parameters.
Distributed optimizer state is initialized on the fully-sharded model parameters.
During the first forward pass after checkpointing or optimization, fully-sharded model weights are all-gathered into partially-sharded model weights.
During the last backward pass before optimization, partially-sharded model gradients are reduce-scattered into fully-sharded model gradients.
Otherwise, FSDP is performed on the partially-sharded model weights and accumulated gradients. Because model weights and gradients are only updated and ingested once per optimization cycle, we can skip or postpone all expensive inter-node / DP-outer collectives until an optimization step.
In addition to improved memory utilization, HFSDP communications are split in communication size (bytes communicated), communication topology (DP-Inner and DP-Outer groups), and communication domain (NVLink and InfiniBand) across two sharding stages.
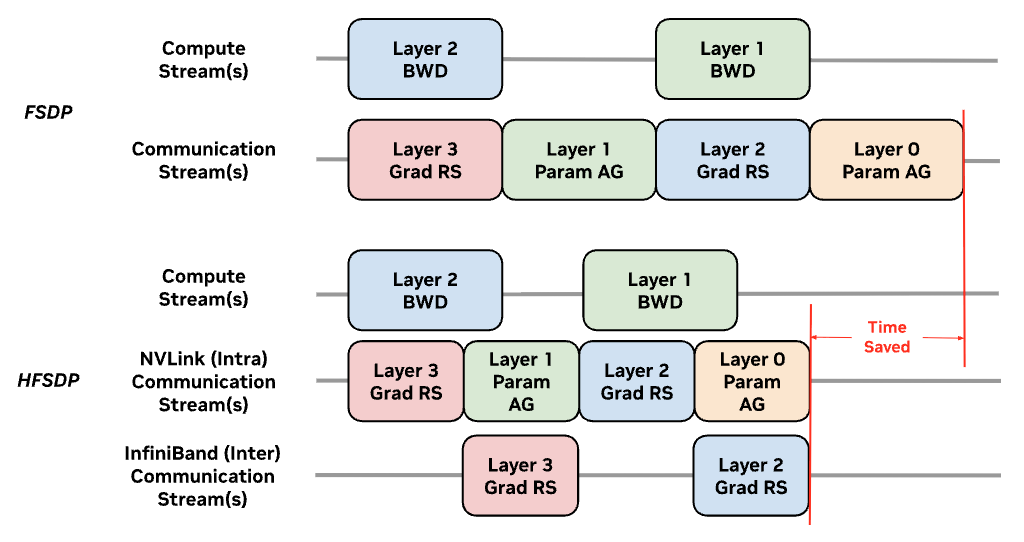
Inter-node communications can also be parallelized with intra-node communications using separate CUDA streams.#
Mixing FSDP & Model Parallelism#
Megatron-FSDP is also compatible with a variety of model parallelisms that shard the model state, such as Tensor Parallelism (TP) and Expert Parallelism (EP). When sharding model states across multiple dimensions in the device topology, FSDP sharding is always performed last, because FSDP collectives un-shard and re-shard parameters and gradients immediately before and after computation. Thus, FSDP sharding mechanics are implemented over tensor and expert parallel (strided) shards.
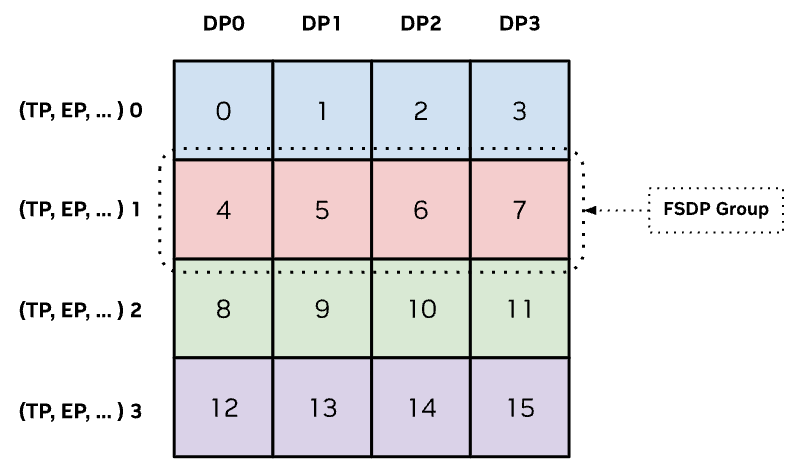
Wheneveer FSDP is composed with other model parallelisms, FSDP sharding is always exercised last to seamlessly integrate with existing model shards.#
Megatron-FSDP uses torch.distributed.DeviceMesh to describe and configure communications across devices in data-parallel group(s). Because heterogeneous models that have mixed layers, such as Hybrid Mamba-Transformer or Mixture-of-Experts (MoE) models, require different parallelism configurations, multiple DeviceMesh(s) may be required for specific layers that require distinct distributed topologies for optimal memory efficiency and performance.
Currently, Megatron-FSDP supports two DeviceMesh(s), one for dense / non-expert Module(s) and another for Megatron-Core MoE sparse / expert Module(s). (Expert modules and parameters in Megatron-Core are automatically detected.)
Dense modules typically have a
DeviceMeshwith data parallel, tensor parallel, and context parallel dimensions, where the data parallel dimension is used for FSDP. Typically, both data-parallel and context-parallel ranks are used for sharding in FSDP.Mixture-of-experts modules typically have a
DeviceMeshwith data parallel, tensor parallel, and expert parallel dimensions, where the data parallel dimension is used for FSDP.
For more information about Mixture-of-Experts in Megatron-Core, refer to the Megatron-Core User Guide - MoE.
Non-Uniform / Un-Even Model Sharding#
While torch.distributed.tensor.DTensor defaults to per-parameter sharding, where Tensors are split evenly on dim=0 across the data-parallel domain, Megatron-FSDP uses non-uniform or un-even DTensor shards of a (flattened) group of parameters associated with an FSDP unit.
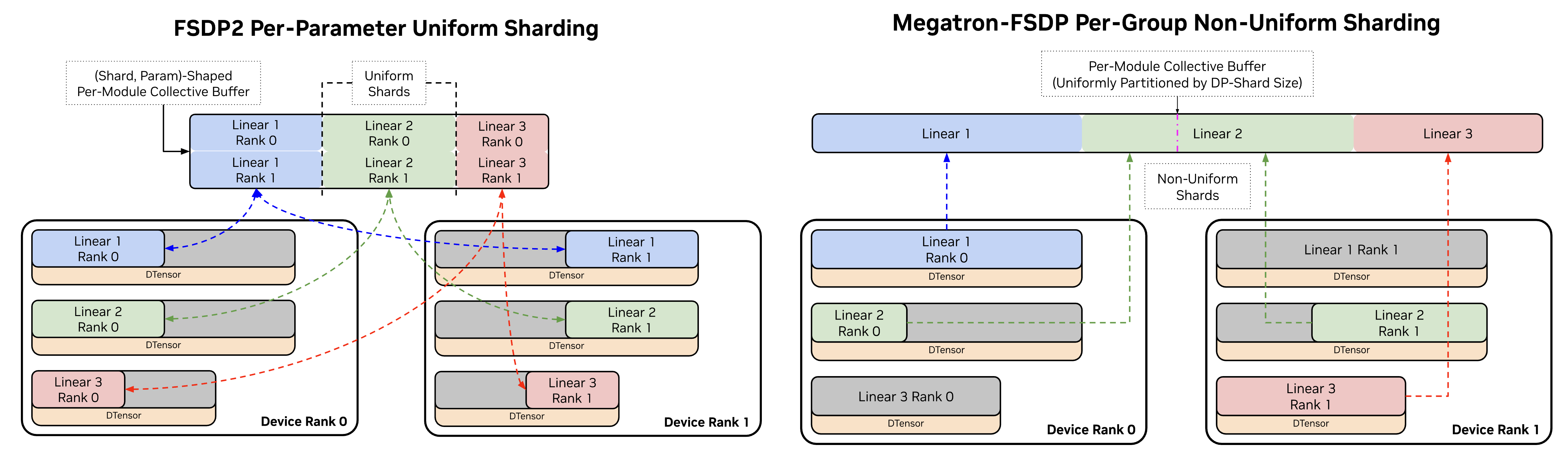
Comparison of FSDP2 per-parameter sharding and Megatron-FSDP per-unit or per-module sharding. FSDP2 requires COPY operations to move parameters and gradients in and out of communication buffers to reduce the frequency of NCCL collective calls, while Megatron-FSDP assigns sliced views of contiguous communication buffers to parameters associated with an FSDP unit.#
While complex and less user-intuitive, an un-evenly sharded data structure enables a few performance benefits without introducing expensive COPY operations to set up communication and computation buffers:
Fewer NCCL calls, reducing kernel launch and synchronization overhead. Only parameters in FSDP units that have different communication-related properties, such as their
dtypeor distributed topology, are coalesced into separate NCCL calls.Flat communication and computation buffers are contiguous-by-design, supporting optimized CUDA kernels that require buffers backed by contiguous memory, such as grouped GEMMs used in MoE.
Effectively, this implies that the same DTensor-sharded model parameters may have completely different shapes on different ranks, and if entire parameters are assigned to other ranks, the local Tensor will be empty.
ℹ️ Megatron-FSDP has a handy library (
megatron_fsdp.uneven_dtensor) for manipulating un-evenly shardedDTensors, focused on per-parameter operations like un-sharding or reducing parameters that have different shapes across ranks. While the parameter group is evenly-sharded for FSDP collectives, per-parameter collectives (that assume a symmetrical amount of bytes are communicated between devices) will hang waiting on bytes that will never arrive for un-evenly shardedDTensors.
In particular, contiguous memory is only half the requirement for high-performance CUDA kernels. The other requirement is locality, which FSDP can violate, that introduces compatibility issues when combining FSDP with present and future optimizations. For example, block-wise quantization (scaling factor / absmax calculations for MXFP8, NVFP4, etc.) requires DP communication and custom max-reduce kernels if the block is sharded by FSDP.
Megatron-FSDP supports dim=0 sharding, which computes the least-common multiple (LCM) of p.shape[1:] for all parameters p in an FSDP unit and pads the un-sharded buffer to the closest multiple of DP x LCM(p.shape[1:]), forming a “DP-LCM” partition with LCM-length parts to ensure that DP-sharding boundaries do not violate chunks of data for coordinates of dim=0.

Visualization of how parameters are assigned un-evenly to the flat per-unit buffer sharded across DP ranks. With the LCM algorithm, every slice of dim=0 is never bisected by FSDP. Algorithms and compute kernels can leverage this locality and contiguity.#
When a parameter is divisble by the LCM, it can be inserted at any index multiple of the LCM in the buffer that is free.
p[i]chunks of this parameter by definition divide the LCM, and thus align with the DP-LCM sharding grid.When a parameter is larger than but not divisible by the LCM, the remainder
rpopulates a fraction of another LCM part, so a “conjugate” parameter that also exceeds the LCM with a “conjugate” remainderr'that is less than or equal toLCM - ris installed to fill the remaining space and align with the DP-LCM sharding grid.When a parameter is smaller than but not divisible by the LCM, a post-assignment sweep on the leftover space in the flat buffer is run, and all gaps that are multiples of the LCM that are large enough to support the entire parameter are utilized. Once all gaps are filled, the final parameters are assigned to the tail of the buffer respecting the DP-LCM sharding grid.
ℹ️ Generalized support for contiguity and locality in Megatron-FSDP is a work-in-progress and will evolve with contribution from the OSS community and PyTorch. For more information about how kernel buffer requirements affect the design of FSDP data structures, refer to the veScale: Consistent and Efficient Tensor Programming with Eager-Mode SPMD (Li, Youjie, ByteDance Seed, et al.) paper that comprehensively analyzes these requirements.
Mixed-Precision & Quantization#
Optimization |
Description |
|
|
|---|---|---|---|
Quantized Parameters |
Megatron-FSDP will shard and all-gather TransformerEngine-quantized parameters for computation. Quantized parameters are updated every optimization step, and both row-wise (FWD) and column-wise (BWD) data are managed for non-transposable 1-D quantization recipes like MXFP8. Otherwise, only activations are quantized. |
|
TransformerEngine |
Main Parameter (Optimization / Checkpoint) Data-Type |
Data-type for optimization and checkpointing parameters. If set to |
|
|
Main Gradient (Accumulation) Data-Type |
Data-type for gradient accumulation. If set to |
|
|
Gradient Communication (Reduction) Data-Type |
Data-type for gradient communication and reduction. If set to |
|
|
Weight Gradient Accumulation Fusion |
When using TransformerEngine modules, Megatron-FSDP implements |
|
N/A (Megatron-Core Only) |
Precision-Aware Optimizer |
Use the TransformerEngine |
|
|
Quantization#
Quantization is an extremely important feature for Megatron-FSDP as it reduces memory utilization and communication size for both activations and parameters, which directly affects the viability and performance of FSDP.
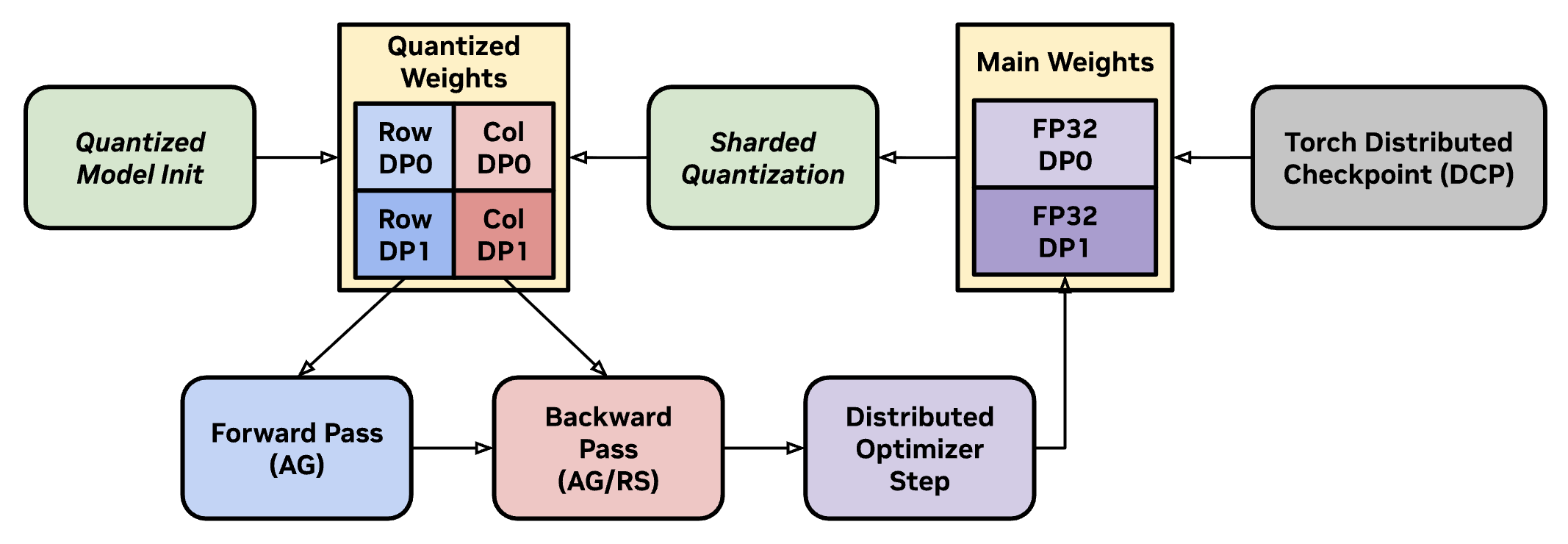
Visualization of Megatron-FSDP’s training loop when using quantized weights from TransformerEngine. Every optimization step updates the quantized representation of sharded model weights, which have reduced communication size.#
While TransformerEngine handles activation quantization, Megatron-FSDP shards quantized weights for AG.
Quantized Model Initialization - Model is initialized with quantized weights, e.g. MXFP8 or NVFP4. If using
metadevice initialization, Megatron-FSDP will callreset_parameters()to initialize quantized weights layer-by-layer. If row-wise and column-wise data are not transposable, Megatron-FSDP will shard and buffer both. Additionally, high-precision main weights are retrieved and sharded for distributed optimization, checkpointing, and quantization.Forward / Backward Pass - Quantized weights are un-sharded for both the forward and backward pass. If row-wise and column-wise data aren’t transposable, the row-wise weights are gathered for forward, and the column-wise weights are gathered for backward.
Distributed Optimization Step - Non-quantized accumulated gradient shards from quantized GEMMs are applied to high-precision main weight shards.
Sharded Quantization - Sharded main weights are quantized to update the quantized compute weights for subsequent training steps.
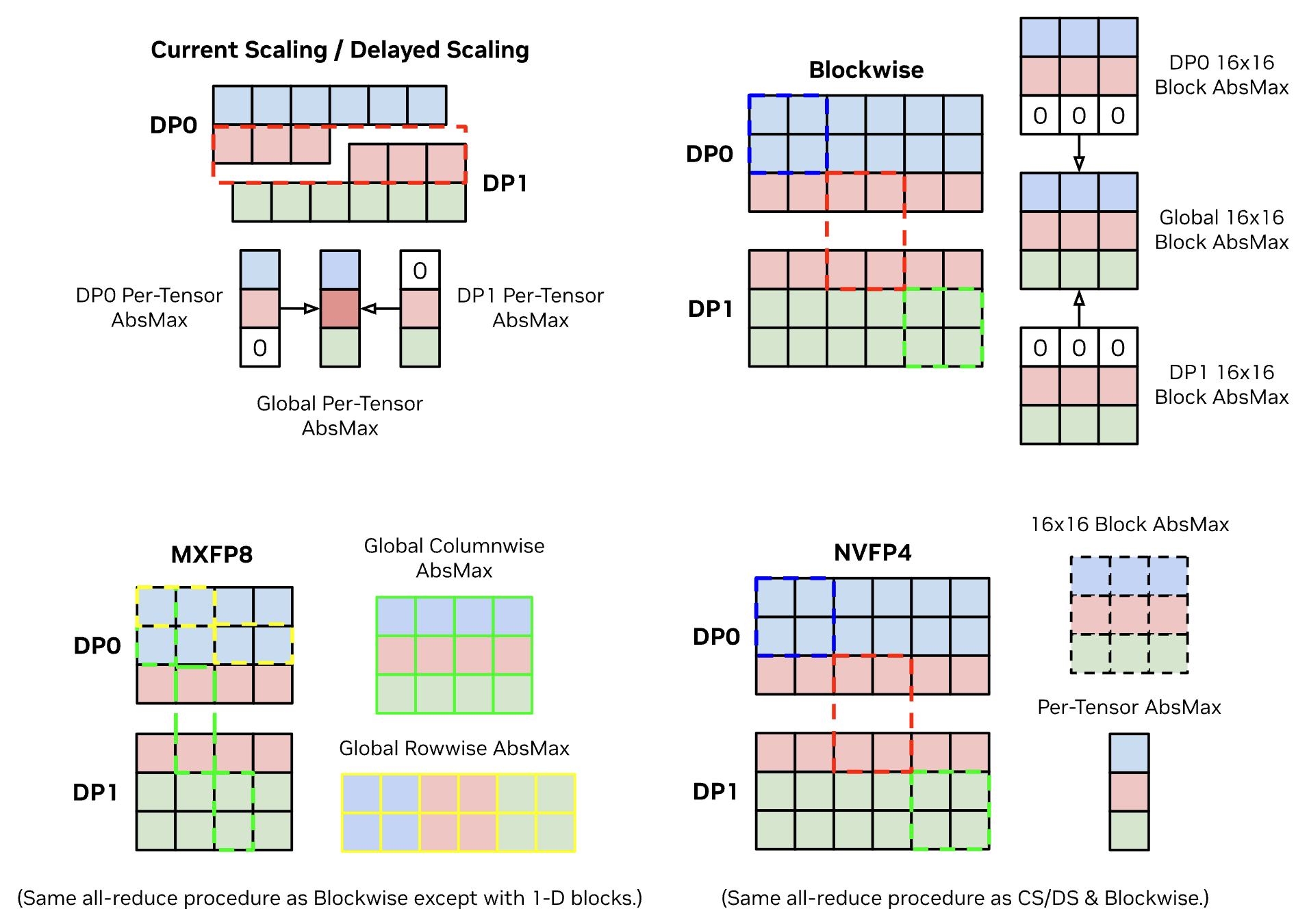
Sharded quantization involves reducing maxima to compute a global set of scaling factors for local / sharded quantization.#
In particular, sharded quantization minimizes communication size and memory utilization by communicating scaling factors instead of main weights.
Local Abs-Max - For a group of parameters in an FSDP unit, compute local tensor-wise or block-wise maxima across the global un-sharded shape, with zero padding for non-local data.
Global Abs-Max - Globally all-reduce maxima and derive scaling factors from maxima.
Local Quantization - Locally quantize sharded main weights and install into compute weight buffers.
Mixed-Precision#
Megatron-FSDP sharding and communication buffers support mixed-precision, such that users can customize the dtype used for main weights, gradient communication (reduction), and gradient accumulation in addition to the native or quantized dtype used for model computation. These options are wrapped in a MixedPrecisionPolicy dataclass.
Main Weight Precision - Controls the data-type for parameters responsible for distributed optimization, distributed checkpointing, and quantization. If set to
auto(None), the native model compute parameter data-type will be utilized. Required for parameter quantization with--fp8-param-gather. Defaults totorch.float32.Main Gradient Precision - Controls the data-type for
wgradaccumulation and distributed optimization. Defaults toauto(None), the model native gradient data-type will be utilized. Whiletorch.float32(or higher) is recommended for accuracy at scale, asmain_grads_dtypecontrols the data-type for gradient accumulation,autois more flexible and uses pre-determined parameter gradient logic in mixed-precision scenarios, such asBF16forFP8/FP4parameters quantized via TransformerEngine.Gradient Communication Precision - Controls the data-type for gradient communications when reducing gradients. Lower precision improves (communication) performance. Defaults to
auto(None), in which the main gradient data-type will be utilized. If usingno_shard,optim, HSDP, or HFSDP, allocatingdtype-custom gradient communication buffers may increase per-unit memory overhead, so users should consider the performance-memory trade-off when using this feature.If using NCCL symmetric registration
v2.27+, gradient reduction may be performed in high-precision depending on the network domain (NVLink or IB), and can enable mixed-precision communication and accumulation, e.g. setting grad_comm_dtype toBF16can supportFP32reduction even though we haveBF16input and output communication buffers. Otherwise, gradients will be reduced and accumulated in communication and accumulation precision as usual.
NCCL#
Optimization |
Description |
|
|
|---|---|---|---|
NCCL User Buffers |
Allocate and register Megatron-FSDP communication buffers with NCCL, which enables zero- |
|
|
NCCL Manual Registration |
Instead of registering NCCL user buffers on first allocation, batch registration of all communication buffers at the end of the initial training step. Reduces registration latency. |
|
N/A (Megatron-Core Only) |
Disable Symmetric Registration |
Disable symmetric registration with NCCL. Optional, as symmetric registration failure defaults to normal registration. |
|
|
NVIDIA Collective Communications Library (NCCL) implements multi-device and multi-node communication primitives optimized for CUDA devices and networking from NVIDIA. Megatron-FSDP communications are registered and deeply integrated with NCCL, which enables a variety of hardware-level networking optimizations such as copy-engine AG, high-precision RS, SHARP reduction offloading, and symmetric kernels.
To leverage NCCL networking optimizations, NCCL user buffer registration (UBR) is required to inform NCCL of PyTorch Tensors (“user buffers”) that act directly as the input and target of NCCL collectives for PyTorch ProcessGroup(s). Because registered communication buffers are known to NCCL, COPY operations that send collective inputs to NCCL buffers and collective outputs to PyTorch buffers are no longer required, which enables Megatron-FSDP to be zero-COPY end-to-end.
NCCL (v2.27+) supports symmetric allocation or registration for communicators over the NVLink domain, which allow buffers that share identical virtual addresses across devices to benefit from optimized collectives:
Symmetric Kernels - On the NVLink domain, symmetric kernels operating on symmetric memory reduces the SM utilization for a single communication kernel to 1.
NVSwitch SHARP Offloading - To further minimize SM utilization for AG and RS collectives, NCCL SHARP offloads reduction and aggregation work to NVLink and IB Switch hardware that uses 1-6 SM depending on the domain: NVL, IB, or NVL + IB.
Copy-Engine (CE) Collectives: Instead of using SMs (or CTAs) for common non-computational collectives like AG in Megatron-FSDP, copy engines are instead used to perform all-gather collectives, dedicating SM resources to compute and reduction during FSDP. Requires NCCL
v2.28+.High-Precision Reduction: When training large models, high-precision gradient reduction and accumulation is desired for accuracy and convergence, but communicating FP32 gradients is expensive. With symmetric registration, FP32 accumulators enable gradients to be reduced in FP32 but communicated in BF16, which decreases gradient RS communication latency while maintaining high accuracy during training. Megatron-FSDP supports FP32 main gradient accumulation but BF16 gradient communication, customizable through
megatron_fsdp.MixedPrecisionPolicy.
These optimizations significantly reduce SM resource contention for overlapped compute and communication kernels in FSDP. Symmetric registration, allocation, and pooling is also supported in PyTorch: torch.distributed._symmetric_memory.