Purpose-Built Pretrained Models¶
The purpose-built AI models packaged with TLT may be broadly categorized into two categories, namely:
Computer Vision¶
The purpose built model shipped with the TLT-CV package can be used in smart cities, retail, public safety, healthcare and are trained on thousands of images. There are 2 versions of these models - trainable and deployable. Both version of these models are available on NGC.
The trainable models or sometimes referred to as trainable or unpruned models are used
with TLT to re-train with your dataset.
On the other hand, deployable or pruned models are deployment ready that allows you to
directly deploy on your edge device. In addition, the deployable model could also contain a calibration
table for running inference in INT8 precision. The pruned INT8 model will provide the highest inference throughput.
The table below shows the network architecture, number of classes and accuracy measured on our dataset.
Model Name |
Network Architecture |
Number of classes |
Accuracy |
TrafficCamNet |
DetectNet_v2-ResNet18 |
4 |
83.5% mAP |
PeopleNet |
DetectNet_v2-ResNet34 |
3 |
84% mAP |
DetectNet_v2-ResNet18 |
3 |
80% mAP |
|
DashCamNet |
DetectNet_v2-ResNet18 |
4 |
80% mAP |
FaceDetect-IR |
DetectNet_v2-ResNet18 |
1 |
96% mAP |
VehicleMakeNet |
ResNet18 |
20 |
91% mAP |
VehicleTypeNet |
ResNet18 |
6 |
96% mAP |
Emotion Recognition |
5 Fully Connected Layers |
6 |
0.91 F1 score |
Gesture Recognition |
ResNet18 |
6 |
0.85 F1 score |
License Plate Detection |
DetectNet_v2-ResNet18 |
1 |
98% mAP |
License Plate Recognition |
Tuned ResNet18 |
36(US) / 68(CH) |
97%(US)/99%(CH) |
Gaze Estimation |
Four branch AlexNet based model |
NA |
6.5 RMSE |
Facial Landmark |
Recombinator networks |
NA |
6.1 pixel error |
FaceDetect |
DetectNet_v2-ResNet18 |
1 |
85.3 mAP |
PeopleSegNet |
MaskRCNN-ResNet50 |
1 |
85% mAP |
Heart Rate Estimation |
Two branch model with attention |
NA |
0.7 BP |
Training¶
The PeopleNet, TrafficCamNet, DashCamNet, FaceDetect-IR and License Plate Detection are detection models based on DetectNet_v2 and either ResNet18 or ResNet34 backbone. To re-train these models with your data, use the unpruned model from NGC and follow the DetectNet_v2 object detection training guidelines from chapters Preparing the Input Data Structure to Exporting the model. The entire training workflow is given in the prior section. You can also download the DetectNet_v2 Jupyter notebook from NGC resources.
The VehicleMakeNet and VehicleTypeNet are classification models based on the ResNet18 backbone. To re-train these models, use the unpruned model from NGC and follow the Image classification training guideline from chapters Preparing the Input Data Structure to Exporting the model. You can also use the classification Jupyter notebook from NGC resources.
The table below shows more information about trainability of the pre-trained models. It shows image requirement, annotation format, model output format, and if the training pipeline supports pruning and INT8 quantization.
Model Name |
Image Type |
Annotation format |
Model output format |
Prunable |
INT8 supported |
TrafficCamNet |
RGB |
KITTI |
Encrypted UFF (.etlt) |
Yes |
Yes |
PeopleNet |
RGB |
KITTI |
Encrypted UFF (.etlt) |
Yes |
Yes |
DashCamNet |
RGB |
KITTI |
Encrypted UFF (.etlt) |
Yes |
Yes |
FaceDetect-IR |
IR |
KITTI |
Encrypted UFF (.etlt) |
Yes |
Yes |
VehicleMakeNet |
RGB |
Encrypted UFF (.etlt) |
Yes |
Yes |
|
VehicleTypeNet |
RGB |
Encrypted UFF (.etlt) |
Yes |
Yes |
|
Emotion Recognition |
68 facial points (no image required) |
JSON file (NV format) |
Encrypted ONNX (.etlt) |
No |
No |
Gesture Recognition |
RGB |
JSON file (NV format) |
Encrypted ONNX (.etlt) |
No |
No |
License Plate Detection |
RGB |
KITTI |
Encrypted UFF (.etlt) |
Yes |
Yes |
License Plate Recognition |
RGB |
TXT |
Encrypted ONNX (.etlt) |
No |
No |
Gaze Estimation |
Grayscale (1 channel) |
JSON file (NV format) |
Encrypted ONNX (.etlt) |
No |
No |
Facial Landmark |
Grayscale (1 channel) |
JSON file (NV format) |
Encrypted ONNX (.etlt) |
No |
No |
FaceDetect |
Grayscale (3 channels) |
JSON file (NV format) |
Encrypted UFF (.etlt) |
No |
Yes |
PeopleSegNet |
RGB |
COCO |
Encrypted UFF (.etlt) |
No |
Yes |
Heart Rate Estimation |
BGR |
JSON file (NV format) |
Encrypted ONNX (.etlt) |
No |
No |
Deployment¶
You can deploy your own trained or the provided pruned or deployable model on any edge device using DeepStream or TLT CV inference pipeline. To deploy on DeepStream, more information can be found in the individual model section. For deploying using the TLT CV inference pipeline, check out the TLT CV inference pipeline section in this guide.
The performance across various NVIDIA platforms is summarized in the table below.The performance in the table is inference performance measured using the trtexec tool in TensorRT samples.
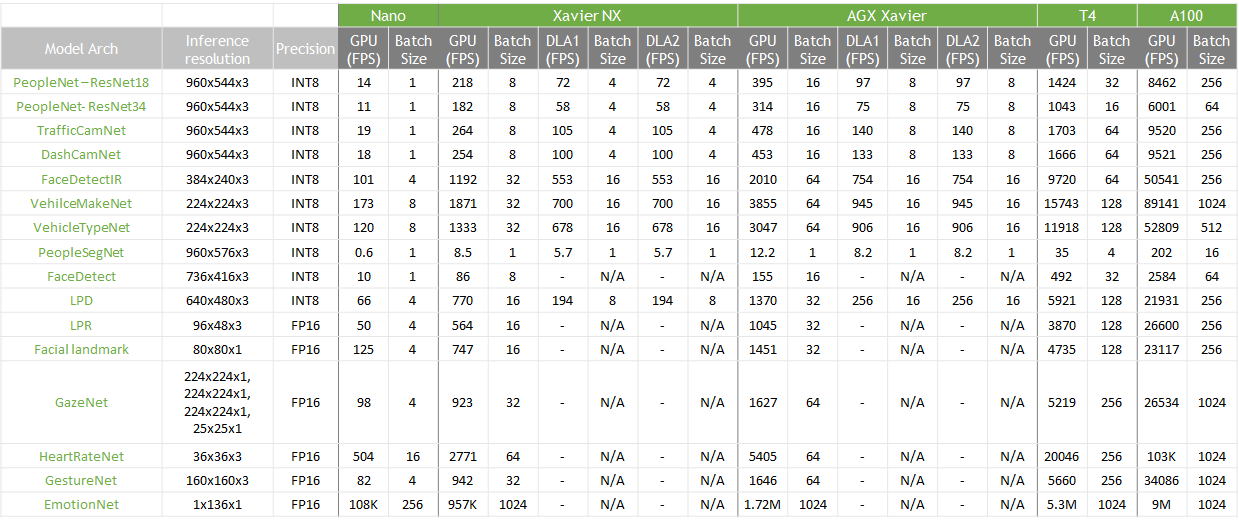
The CV models below can be deployed on any NVIDIA datacenter GPUs such as A100, T4, Quadro or on embedded platform like NVIDIA Jetson.
The table below shows the inference SDK along with if inference is supported on DLA (Deep learning accelerator) on Jetson AGX Xavier or Xavier NX.
Model Name |
Inference Pipeline |
DLA supported |
TrafficCamNet |
DeepStream |
Yes |
PeopleNet |
DeepStream |
Yes |
DashCamNet |
DeepStream |
Yes |
FaceDetect-IR |
DeepStream |
Yes |
VehicleMakeNet |
DeepStream |
Yes |
VehicleTypeNet |
DeepStream |
Yes |
Emotion Recognition |
TLT CV Inference pipeline |
No |
Gesture Recognition |
TLT CV Inference pipeline |
No |
License Plate Detection |
DeepStream |
Yes |
License Plate Recognition |
DeepStream |
No |
Gaze Estimation |
TLT CV Inference pipeline |
No |
Facial Landmark |
TLT CV Inference pipeline |
No |
FaceDetect |
TLT CV Inference pipeline |
No |
PeopleSegNet |
DeepStream |
Yes |
Heart Rate Estimation |
TLT CV Inference pipeline |
No |
TrafficCamNet¶
TrafficCamNet is a 4-class object detection network built on NVIDIA’s detectnet_v2 architecture with ResNet18 as the backbone feature extractor. It’s trained on 544x960 RGB images to detect cars, persons, road signs and two wheelers. The dataset contains images from real traffic intersections from cities in the US (at about 20ft vantage point). This model is trained to overcome the problem of separating a line of cars as they come to stop at a red traffic light or a stop sign. This model is ideal for smart city applications, where you want to count the number of cars on the road and understand flow of traffic.
PeopleNet¶
PeopleNet is a 3-class object detection network built on NVIDIA’s detectnet_v2 architecture with ResNet34 as the backbone feature extractor. It’s trained on 544x960 RGB images to detect person, bag, and face. Several million images of both indoor and outdoor scenes were labeled in-house to adapt to a variety of use cases, such as airports, shopping malls and retail stores. This dataset contains images from various vantage points. PeopleNet can be used for smart places or building applications where you need to accurately count people in a crowded environment for security or higher level business insights.
DashCamNet¶
DashCamNet is a 4-class object detection network built on NVIDIA’s detectnet_v2 architecture with ResNet18 as the backbone feature extractor. It’s trained on 544x960 RGB images to detect cars, pedestrians, traffic signs and two wheelers. The training data for this network contains real images collected, annotated and curated in-house from different dashboard cameras in cars at about 4-5ft height in vantage point. Unlike the other models the camera in this case is moving. The use case for this model is to identify objects from a moving object, which can be a car or a robot.
FaceDetect-IR¶
FaceDetect_IR is a single class face detection network built on NVIDIA’s detectnet_v2 architecture with ResNet18 as the backbone feature extractor. The model is trained on 384x240x3 IR (infrared) images augmented with synthetic noises and is trained for use cases where the person’s face is close to the camera, such as a laptop camera during video conferencing or a camera placed inside a vehicle to observe a distracted driver. When infrared illuminators are used this model can continue to work even when visible light conditions are considered too dark for normal color cameras.
VehicleMakeNet¶
VehicleMakeNet is a classification network based on ResNet18, which aims to classify car images of size 224 x 224. This model can identify 20 popular car makes. VehicleMakeNet is generally cascaded with DashCamNet or TrafficCamNet for smart city applications. For example, DashCamNet or TrafficCamNet acts as a primary detector, detecting the objects of interest and for each detected car the VehicleMakeNet acts as a secondary classifier determining the make of the car. Businesses such as smart parking or gas stations can use the insights of the make of vehicles to understand their customers.
VehicleTypeNet¶
VehicleTypeNet is a classification network based on ResNet18, which aims to classify cropped vehicle images of size 224 x 224 into 6 classes: Coupe, Large Vehicle, Sedan, SUV, Truck, and Vans. The typical use case for this model is in smart city applications such as smart garage or toll booth, where you can charge based on size of the vehicle.
Emotion Recognition (EmotionNet)¶
EmotionNet is a classification network based on 5 Fully Connected Layers, which aims to classify human emotion into 6 classes: disgust, happy, neutral, scream, squint, and surprise. One use case for this model is with deployment for retail vision and analytics. With person detection, speech recognition, and emotion detection, customers can build a solution to understand store activity. The goal is for all retailers to analyze and optimize activity in physical store locations.
Gaze Estimation (GazeNet)¶
GazeNet is a network that can predict eye gaze point of regards and gaze vector. The network requires four inputs, including face, left eye, right eye, and facegrid. The architecture of the model has four branches. The face, left eye, and right eye branch are AlexNet based architecture. The facegrid branch has two Fully Connected layers. One use case of GazeNet in deployment is to use gaze values as threshold to determine when to enable speech recognition. This “Looking At” feature enables speech recognition only when the subjects are looking at the camera.
Heart Rate Estimation (HeartRateNet)¶
HeartRateNet is a heart rate pulse estimation network, which aims to estimate heart rate pulse from RGB facial videos. This is a two branch model with an attention mechanism that takes in a motion map of size 72 x 72 x 3 and an appearance map size of 72 x 72 x 3 both derived from RGB face videos.
Facial Landmark (FPENet)¶
FPENet is a fiducual point estimation network, which aims to predict the (x,y) location of keypoints for a given input face image. FPEnet is generally used in conjuction with a face detector and the output is commonly used for face alignment, head pose estimation, emotion detection, eye blink detection, gaze estimation, among others.
Gesture Recognition (GestureNet)¶
GestureNet is a classification network based on ResNet18, which aims to classify cropped hand images of size 160 x 160 into 6 classes: Thumbs Up, Fist, Stop, Ok, Two and Random. One deployment use case for this model is for human machine interaction.
License Plate Recognition (LPRNet)¶
LPRNet is a license plate recognition network trained on license plates in US and China.
FaceDetect¶
FaceDetect is a face detection model that takes in 3 channel RGB images and detect person’s face.
PeopleSegNet¶
PeopleSegNet is a instance segmentation network to detect and localize people in a crowded environment.
Conversational AI¶
The purpose built models shipped with the TLT - Conversational AI package can be used directly in tasks like answering questions across multiple domains, improving sentence semantics and more or can be re-trained or fine tuned to deploy a Conversational AI like a Virtual Assistant to service customers in varied fields like financial services, legal services, insurance, customer service and many more!
The table below shows the network architecture and the application area in which the model is trained. These models can be re-trained or fine tuned to change the domain/language according to the user’s requirements
Model Name |
Base Architecture |
Dataset |
Purpose |
|---|---|---|---|
ASR - Jasper |
Jasper |
ASR Set 1.2 with Noisy (profiles: room reverb, echo, wind, keyboard, baby crying) - 7K hours |
Speech Transcription |
ASR - QuartzNet |
Jasper |
ASR Set 1.2 |
Speech Transcription |
Question Answering |
BERT Base, BERT Large |
SQuAD 2.0 |
Answering questions in SQuADv2.0, a reading comprehension dataset consisting of Wikipedia articles. |
Named Entity Recognition |
BERT Base |
GMB (Gronigen Meaning Book) |
Identifying entities in a given text (Supported Categories: Geographical Entity, Organization, Person , Geopolitical Entity, Time Indicator, Natural Phenomenon/Event) |
Intent and Slot Recognition |
BERT Base |
Proprietary |
Classifying an intent and detecting all relevant slots (Entities) for this Intent in a query. Intent and slot names are usually task specific. This model recognizes weather related intents like weather, temperature, rainfall etc. and entities like place, time, unit of temperature etc. For a comprehensive list, please check the corresponding model card. |
Punctuation and Capitalization |
BERT Base |
Tatoeba sentences, Books from the Project Gutenberg that were used as part of the LibriSpeech corpus, Transcripts from Fisher English Training Speech |
Add punctuation and capitalization to text. |
Text Classification |
BERT Base, BERT Large |
Proprietary |
For domain classification of queries into the 4 supported domains: weather, meteorology, personality, and none. |