Break-Fix Architecture#
The mission of the NCP Software Reference architecture break-fix system is to ensure that tenants have high availability on clusters through automations that:
Ensure healthy cluster hand-off from cloud provider to tenant
Passively screen, triage, and remediate hardware (field diags→RMA) and software components (applying updates such as firmware, software upgrades, and system reboots)
Minimize human intervention required to fix broken nodes
The focus is to create a day 2 Break-Fix system that is focused on monitoring and, to the greatest extent possible, automating the remediation of the GPU-based compute nodes. Day 2 is defined as once the data center is online and validated and ready for normal tenant operation. It is critical to minimize downtime.
Break-Fix Overview#
The intent of the Break-Fix architecture is to “detect, triage, remediate, and validate” GPU nodes for AI infrastructure. This is sometimes referred to as health checks and break-fix, but this document will consider break-fix to be inclusive of the health checks. The goal of this section is to describe how one can create a robust Break-Fix architecture that can be operationalized across a wide array of AI platforms and workloads and operated by an NCP.
While the architecture can be expanded to support traditional compute nodes, the focus of this document is on GPU nodes. By creating an automated way to handle break-fix scenarios, especially ones where the entire fix can be deployed without human intervention, the resulting uptime can be made significantly better.
Break-Fix#
The Break-Fix architecture should be thought of as having two primary domains. The first domain, the Tenant Domain (TD), includes all break-fix operations done while the node or GPU is in possession of a tenant. The second domain, the Infrastructure Operator Domain (IOD), includes all break-fix operations done while the machine is in control of the infrastructure operator. The notable exception to this split is that continuous/offline checks are performed by the IOD even when a machine is part of the Tenant Domain. It is important to keep these two domains logically separated.
The Tenant Domain has three primary roles:
Continuous in-band Node Health Checks: This requires the tenant to run a set of health checks on a regular heartbeat to inform the break-fix system on the overall health of each node. Thus, the Tenant must opt-in to running continuous health checks and participating in the overall break-fix flow.
Tenant Remediation: Where possible, the goal of the break-fix system is to fix any unhealthy nodes as quickly as possible while minimizing impact on the tenant. Many issues can be handled without removing the node from circulation, such as doing a PCIe GPU reset.
Node Return: If the node’s health checks identify an issue that cannot be remediated while in the tenant’s possession, the tenant must agree to return the node to the IOD domain for further action. This could result in another node getting allocated, or it could result in a reduced set of capabilities for the tenant.
The Infrastructure Operator Domain (IOD) has three primary roles:
Initial Node Validation: A key principle is to make sure that the IaaS service always delivers a known-good node to the tenant upon initial vending. Thus, while a node is under the IOD, the infrastructure operator needs to be doing node health checks and making sure the node is functioning as expected (to the extent the tests can show).
Continuous Offline Node Health Checks: Some health checks can be done in an offline manner, so they do not require the tenant to opt in. Some examples of offline checks on the platform or data lake could be BMC query for node thermals, DPU heartbeat, and log file monitoring to find indications of issues. As mentioned, this is being done by the IOD even when the machine is in the Tenant Domain.
Node Remediation: When a node issue is identified by any mechanism, process the node (in as automated a way as possible) to remove the node from circulation, get it healthy, and put it back into circulation.
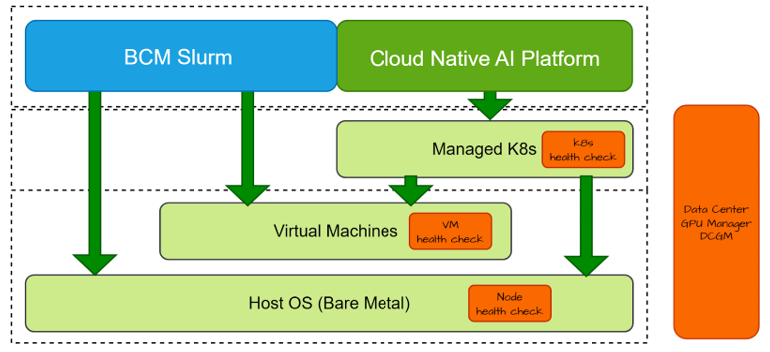
Node-Level Health Checks#
There are many utilities to help with node-level health checks, both created by NVIDIA and in the ecosystem. For the NCP Software Reference Guide architecture, no specific tool integration is assumed, but it is assumed that NVIDIA’s Data Center GPU Manager (DCGM) entity is used.
Health checks may run at all levels of infrastructure. This is due to the fact that certain information is only available at a particular level of the stack. For example, many of the components need direct access to the GPU driver. This might exist at the Host OS level, or it might be provided as a passthrough device to the VM level. The net effect is that a certain set of health checks need to run at the appropriate place.
The health check entity typically includes a harness — to run the local health checks on a regular heartbeat and to interact with the overall break-fix solution — and the actual set of checks themselves. Some health checks may run at every interval, and others may run less often or only upon request. As health issues are detected, the health check entities will report back to the break-fix control plane to act.
Break-Fix Architecture#