Workload Isolation#
In a multi-tenant deployment, it is critical that the end-to-end solution provides workload isolation and resiliency. In a multi-tenant K8s deployment, end users should be able to request a dedicated K8s control plane instance (KaaS). K8s cluster instances that provide tenants with API access must not be shared between tenants, to ensure isolation and security. However, the physical worker hosts running the control plane node virtual machines can be shared across tenants in many deployment scenarios, which is a great way to improve utilization of the underlying physical servers.
From a tenant’s viewpoint, Bare Metal provides the best node-level isolation by removing any noisy neighbors and significantly reducing the access the infrastructure operator may have, but has the highest cost (for infrastructure, for provisioning, for sanitization during node recycling, etc). As such, Virtual Machines likely fit the majority of computing needs at a lower cost.
A worker node is a virtual machine (VM) running on a physical worker host. The hypervisor hosting these VMs should isolate them and protect them against active and passive attacks, including resource-contention attacks, memory leaks, CPU cache line leaks, and more. NVIDIA recommends configuring protective measures in the hypervisor to safeguard against hostile or noisy neighbors interfering with physical resources such as GPU, CPU, memory, and network, as well as logical resources such as storage and IP space.
Multi-tenancy on a single node, where VMs from different tenants physically execute on the same node, is inherently less secure than when a single tenant is present. Where possible, it is recommended to keep nodes aligned to a single tenant as this provides the best security and enables the attached GPUs to work together as efficiently as possible. If allocating multiple tenants to the same node, it is imperative to have a robust isolating mechanism (e.g. hardened hypervisor, utilize DPU).
For use cases like managed Kubernetes and AI Platforms, resources on the control plane side should be assigned on a per-tenant basis as well to make sure that a noisy or misbehaving tenant can’t impede the operation of another tenant. Specifically, for a service like the k8s control plane, it is recommended that there is a unique control plane running per tenant. It may be acceptable to aggregate these control planes in VMs running on the same machines if the isolation solution is sufficient.
When infrastructure is turned over between tenants, it is critical that the Operator remove all tenant data, or “sanitize”, from the infrastructure. This includes wiping memory, making sure all firmware across all devices is in a known good state, and “erasing” the local ephemeral drive data.
A worker node (the worker virtual machine instantiated on a physical worker host) must be assigned to exactly one tenant, and thus also to only one K8s control plane instance.
When a VM is assigned as a worker node to a K8s control plane instance, the control plane may schedule one or many workloads in that VM at a time. Workload isolation within a VM provided by runc or similar process-based isolation may be less robust than the isolation provided by the hypervisor between VMs. Operators and tenants should consider these differences in user-to-user isolation when scheduling workloads within it. The K8s control plane should support the tenant’s choice to schedule one or many workloads per worker-node VM.
The worker nodes on a host should be actively monitored for resource contention, abuse, and attack patterns. A worker VM that exhibits unexpected behavior should be appropriately acted upon.
Workload isolation in the networking infrastructure is available in the Common Networking reference architecture (ID 1144496). Request this document from your NVIDIA Sales Representative.
Boot and Attestation#
It is important to be confident in the integrity of the firmware and software running on a compute node. This is foundational to having secure infrastructure. The cloud operator should take a zero-trust approach on the infrastructure and implement a secure and measured boot solution that can attest to its state. This process should apply to every processor running an OS in the data center. This includes BMCs, DPUs, and Host Processors (x86 or ARM). A secure multi-tenant AI infrastructure should implement secure boot, cleanup, and attestation methods.
Secure Boot#
Secure Boot is the process that guarantees that privileged software that is loaded has been signed by a trusted vendor or operator. This is done by creating a chain of trust from one verified software entity to the next.
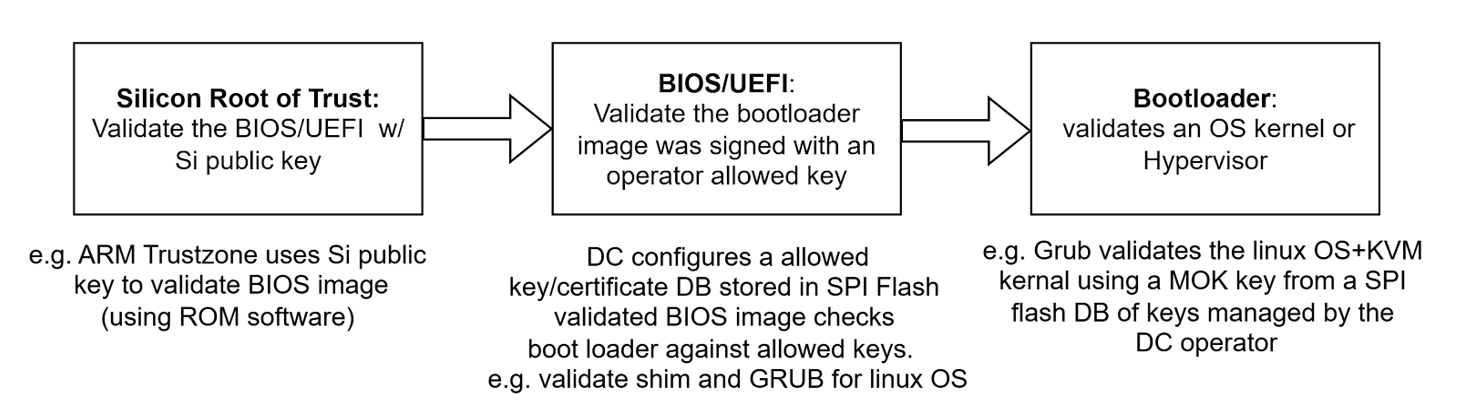
Secure Boot Stages#
This chain can continue to grow the stack as much as the operator wishes. At the end of this process, only trusted code signed by allowed agents has been loaded.
Measured Boot#
Measured Boot is designed to provide a path to detect the case where the secure boot policies or signing keys get compromised. Thus, it does not prevent bad things from happening but rather provides an audit trail of what has been loaded and run. This is created by not only validating the signatures at each stage shown above, but also by generating a hash — called a digest — of the entire binary image being loaded and storing (extending) that digest into a platform component called a TPM, or Trusted Platform Module. This trail now allows the control plane to be able to verify that the processor did load the expected sequence of software.
Remote Attestation#
The process of validating that the correct software was loaded is called remote attestation. A part of the cloud control plane, the attestation service, should ask each host TPM for the current measurements. This includes a challenge value called a nonce to be sure the response is not spoofed. Without going into the detailed cryptographic handshakes, the TPM responds to the attestation service, which acts as the verifier to confirm the TPM responded correctly and that all measurements were done using the appropriate keys and certificates and match golden values.