Infrastructure-as-a-Service#
The Infrastructure-as-a-Service (IaaS) layer provides scalable bare metal and virtual machines (both called instances) to users, allowing tenants to run their applications without having to manage the underlying physical infrastructure. The IaaS layer should provide a range of offerings that can be customized by the NCP, configuring dimensions like general-purpose compute size, memory, storage, and GPU capacity.
IaaS Architecture#
The following diagram defines the major components of the IaaS system that are considered part of the Data Center Management (DCM) functionality. This includes the Cloud Control Plane (CCP), Software Defined Networking (SDN), Compute Service, and Software Defined Storage (SDS).
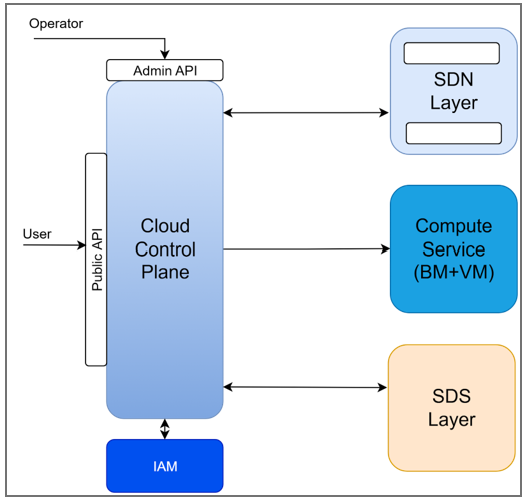
Infrastructure as a Service Components#
These components work together to build a CSP-like infrastructure-as-a-service system.
Component Descriptions#
Component |
Description |
|---|---|
Cloud Control Plane (CCP) |
Public-facing control plane providing API/UI to provision and manage compute, networking, and storage. Handles authentication, authorization, quota enforcement, and metering. |
Software Defined Network (SDN) |
Enables centralized, programmable network management for automation, scalability, and multi-tenant isolation. |
Compute Service |
Manages bare metal and VM instance lifecycle, including provisioning, placement, monitoring, and sanitization between tenants. |
Software Defined Storage (SDS) |
Manages provisioning, pooling, and scaling of block, file, and object storage. |
Identity and Access Management (IAM) |
Authentication and authorization for end-users. |
Each IaaS component requires specific capabilities to operate an AI-optimized, multi-tenant data center. Building a complete IaaS layer requires integrating software across all these components. NVIDIA provides a range of infrastructure software for network management, compute management, and storage acceleration. NCPs and ISVs integrate the software components with their choice of operating system, hypervisor, and storage vendor.
Network Management#
To recap from the Data Center View, an AI data center operates multiple network fabrics:
Network |
Purpose |
Technology |
|---|---|---|
Tenant Access Network (TAN) |
North-South traffic: Tenant access to storage, external services |
Ethernet (Spectrum) |
Cluster Interconnect Network (CIN) |
East-West traffic: GPU-to-GPU communication across nodes |
InfiniBand (Quantum) or Ethernet (SpectrumX) |
NVLink Network |
Scale-up: GPU-to-GPU communication within a rack |
NVLink (GB200/GB300) |
Secure Management Network (SMN) |
Out-of-band (OOB) infrastructure management |
Ethernet (1GbE) |
Shared Services |
Tenant access to shared services (registry, IAM) |
Logical overlay on TAN |
Network management encompasses provisioning, configuring, and isolating these fabrics to support multi-tenant AI workloads.
Capabilities Required#
Ethernet Fabric Provisioning: Configure leaf-spine fabric for TAN and Ethernet-based CIN
Ethernet visibility & telemetry: Monitor fabric health, validate changes, troubleshoot issues
InfiniBand Fabric Management: Configure IB fabric for high-performance CIN
NVLink Domain Management: Configure rack-scale NVLink (GB200/GB300)
Tenant Network Isolation: Create isolated VPCs via overlays (VXLAN) or partition keys (PKeys)
Software Defined Networking (SDN)#
With Software Defined Networking, the network control plane is separated from the data plane to enable centralized and programmable management for the network behavior. Thus, rather than having a system administrator manually go to switches and routers to update behavior, it can all be updated programmatically by the SDN controller.
The picture below shows the SDN system built on top of NVIDIA technologies. While this is not the only way to construct the SDN, it is shown this way to explain the relevant technologies.
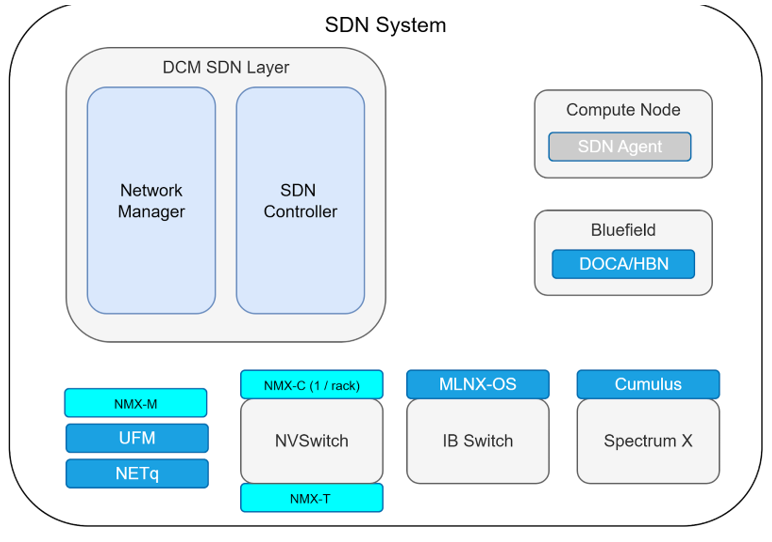
Software Defined Network built on NVIDIA software components#
The DCM SDN Layer contains the Network Manager and SDN Controller — these are typically ISV or NCP-built components that handle the control plane logic.
On the right side, the Compute Node runs an SDN Agent, with the BlueField DPU running DOCA/HBN to terminate tenant overlays at the edge.
At the bottom, NVIDIA software manages each network fabric: NMX manages NVSwitch-based NVLink domains, UFM manages InfiniBand switches running MLNX-OS, and NetQ provides visibility for Spectrum switches running Cumulus.
Compute Management#
The Compute Service is responsible for managing bare metal (BM) and virtual machine (VM) instances and their full lifecycle. This applies to all the compute in the data center, including GPU nodes, general-purpose nodes, and potentially software-defined storage nodes. The Compute Service deals with:
Instance Lifecycle (create, start/stop, terminate, reboot, placement)
Instance Management (for example, Get VM Status, Attach Volume)
Monitor Instance (get logs, get metrics)
Instance Networking (Assign IP to Instance, attach virtual NIC to instance)
Sanitize compute resources between tenants
Tenant Isolation
Capabilities Required#
Capability |
Purpose |
|---|---|
Machine Discovery |
Discover and ingest physical machines into inventory |
Bare Metal Provisioning |
PXE boot, firmware updates, OS installation at scale |
Instance Lifecycle |
Create, start/stop, terminate, reboot, placement |
Instance Management |
Get status, attach volumes, assign IPs, attach vNICs |
Hardware Attestation |
Verify node and firmware integrity prior to allocation |
Node Health Check |
Stress test to verify performance before allocation |
Node Sanitization |
Securely wipe nodes between tenants |
GPU Virtualization |
Share GPUs across VMs (time-sliced or MIG) |
GPU Observability |
Monitor GPU health, metrics, diagnostics |
Rack-Scale Lifecycle |
Power sequencing, cooling, coordinated firmware |
The following describes logical components that make up the Compute Service. A specific implementation may partition differently, but the capabilities should be present.
Machine Lifecycle Manager — Discovery, ingestion, placement, provisioning, sanitization, firmware updates, BMC management, IP allocation, OS installs
Instance Database — Maintains state for all physical machines and instances
VM Control Plane — Receives provisioned BM nodes, handles VM requests, bin-packing, event monitoring. This applies at the node level; for rack-level and larger deployments (e.g. scalable unit (SU) delineations), the same behavior and placement decisions should be considered to achieve optimal network bandwidth and latency. NVIDIA recommends KubeVirt on Kubernetes.
PXE Boot Server — The PXE (Pre-boot eXecution Environment) boot server responds to a request from a booting node and loads a minimal OS and a provisioning agent. The provisioning agent can be used to test the node, update all the firmware on the platform, and install a Bare Metal image (tenant OS and cloud-init configuration) or Virtual Machine image (base OS/hypervisor + core components). This may logically be part of the Lifecycle Manager.
Storage Management#
Bare metal servers and virtual machines need access to storage. There are two classes of storage — ephemeral and persistent. Ephemeral is provided by access to (typically local) drives that are erased between tenants. Persistent provides access to a mix of block, file, and object storage across the network. For the latter, the SDS is responsible for managing the provisioning, pooling, and scaling of these three types of storage. This is accessed through the Cloud Control Plane.
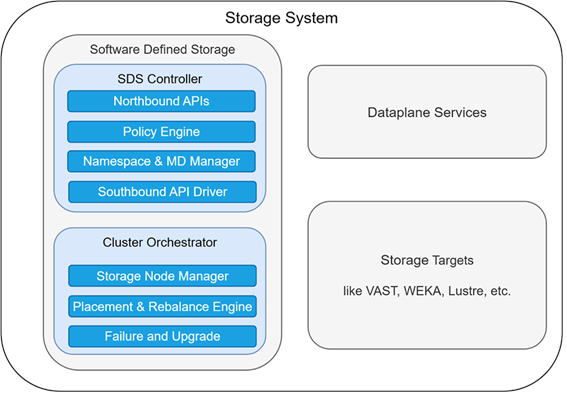
Storage Systems in the NVIDIA Software Reference Architecture#
The SDS system has two primary components:
SDS Controller#
This is the tenant-facing control plane:
Provides the northbound APIs (for example, CreateVolume, DeleteVolume, SetPolicy)
Provides the Policy Engine to enforce quotas, QoS, and security
Namespace Manager to track the logical view of storage
Southbound driver to translate commands to the correct storage target mechanics
Cluster Orchestrator#
This is the infrastructure-facing control plane:
Node Manager manages the physical node lifecycle
Placement Engine applies physical constraints to placement (for example, replicas across power domains)
Detect failures and manage recovery, manage upgrades, and more.
Beyond SDS controller and cluster orchestrator, there are the actual storage targets (like VAST, WEKA, Lustre, NFS) and potential data plane services (such as snapshots, data imports).
Capabilities Required#
Capability |
Purpose |
|---|---|
Block Storage |
Attach persistent volumes to instances |
File Storage |
Shared filesystems for datasets and checkpoints |
Object Storage |
S3-compatible storage for data lakes and artifacts |
Storage Tenant Isolation |
Volume access control, namespace separation, per-tenant encryption |
Storage QoS |
Enforce bandwidth/IOPS limits per tenant to prevent noisy neighbors |
High-Performance Data Path |
Direct GPU-to-storage data movement, bypassing CPU |
Storage Network Integration |
Connect to NVMe-oF, RDMA-capable storage fabrics |
NVIDIA Software for Infrastructure-as-a-Service#
NVIDIA provides software to address specific IaaS capabilities described above. The use of NVIDIA-provided software is optional and depends on architectural decisions made by the NCP. NCPs can work with an ecosystem of ISV partners to integrate specific software components provided.
Functional Area |
NVIDIA Software Implementation |
|---|---|
Network Management |
Cumulus, NetQ, UFM, NMX, DOCA/HBN, NVIDIA NCX Infra Controller[1] |
Compute Management |
NVIDIA NCX Infra Controller |
Storage Connectivity |
GPUDirect Storage, GPUDirect RDMA |
Operations |
DCGM |
For detailed descriptions of each component, see Part 2: NVIDIA Software for Infrastructure as a Service.