Realtime API Reference#
Overview#
Riva Realtime Server provides a WebSocket-based API for real-time text-to-speech (TTS) synthesis. This API allows you to stream text data and receive real-time speech audio output.
Reference#
The WebSocket server provides real-time communication capabilities for text-to-speech synthesis services. To establish a connection, clients must connect to the WebSocket endpoint with the required query parameter.
Synthesis Sessions Endpoint#
The synthesis sessions endpoint allows you to create text-to-speech synthesis sessions.
Base URL:
http://<address>:9000
Endpoint:
/v1/realtime/synthesis_sessions
Method: POST
Response: Returns the initial synthesis session configuration.
{
"id": "sess_<uuid4>",
"object": "realtime.synthesize_session",
"input_text_synthesis": {
"language_code": "en-US",
"voice_name": "English-US.Male-1",
},
"output_audio_params": {
"sample_rate_hz": 22050,
"num_channels": 1,
"audio_format": "LINEAR_PCM"
},
"custom_dictionary": "",
"zero_shot_config": {
"audio_prompt_bytes" : "<base64_encoded_audio_data>",
"audio_prompt_transcript": "",
"prompt_quality": 20,
"prompt_encoding": "LINEAR_PCM",
"sample_rate_hz": 22050
},
"client_secret": null
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
id |
string |
No |
Session identifier |
auto-generated (“sess_ |
object |
string |
Yes |
Object type identifier |
“realtime.synthesize_session” |
input_text_synthesis.language_code |
string |
Yes |
Synthesis language code (e.g., “en-US”, “es-ES”) |
“en-US” |
input_text_synthesis.voice_name |
string |
No |
Voice to use for synthesis (e.g., “English-US.Male-1”, “English-US.Female-1”) |
“English-US.Male-1” |
output_audio_params.sample_rate_hz |
integer |
No |
Audio sample rate in Hz |
22050 |
output_audio_params.num_channels |
integer |
No |
Number of audio channels |
1 |
output_audio_params.audio_format |
string |
No |
Output audio format (LINEAR_PCM, OGG_OPUS) |
“LINEAR_PCM” |
custom_dictionary |
string |
No |
Custom pronunciation dictionary |
“” |
zero_shot_config.audio_prompt_bytes |
string |
No |
Base64-encoded audio prompt for zero-shot voice cloning |
“” |
zero_shot_config.audio_prompt_transcript |
string |
No |
Transcript of the audio prompt |
“” |
zero_shot_config.prompt_quality |
integer |
No |
Quality setting for zero-shot (1-40) |
20 |
zero_shot_config.prompt_encoding |
string |
No |
Encoding format of the audio prompt |
“LINEAR_PCM” |
zero_shot_config.sample_rate_hz |
integer |
No |
Sample rate of the audio prompt in Hz |
22050 |
client_secret |
string |
No |
Client authentication secret |
null |
Note: The zero_shot_config allows for voice cloning using audio prompts. When provided, the system will attempt to synthesize speech in a voice similar to the provided audio prompt. The audio_prompt_bytes should be base64-encoded audio data.
WebSocket Connection Details#
Base URL:
ws://<address>:9000
Endpoint:
/v1/realtime
Required Query Parameter:
intent=synthesize
Example Connection URL#
The following is a complete example of a connection URL to access the WebSocket server:
ws://localhost:9000/v1/realtime?intent=synthesize
Connection Requirements#
Establish the WebSocket connection with the
intentquery parameter set to a supported valueThe only currently supported intent for the text-to-speech service is
synthesizeThe server runs on port 9000 by default
The connection uses the standard WebSocket protocol (ws://)
An invalid or missing intent results in connection closure with WebSocket code 1008 (Policy Violation)
Usage Notes#
Ensure your client supports WebSocket connections
Maintain the connection for the duration of the synthesis session
Handle connection errors and reconnection logic in your client implementation
Health Check Endpoint#
The health check endpoint provides a way to verify the server’s operational status.
Endpoint:
/v1/health
Method: GET
Response:
{
"status": "ok"
}
Status Codes:
200 OK: Server is healthy and ready to accept connections503 Service Unavailable: Server is not ready to accept connections
Use Cases:
Pre-flight check before establishing WebSocket connections
Load balancer health monitoring
System status monitoring
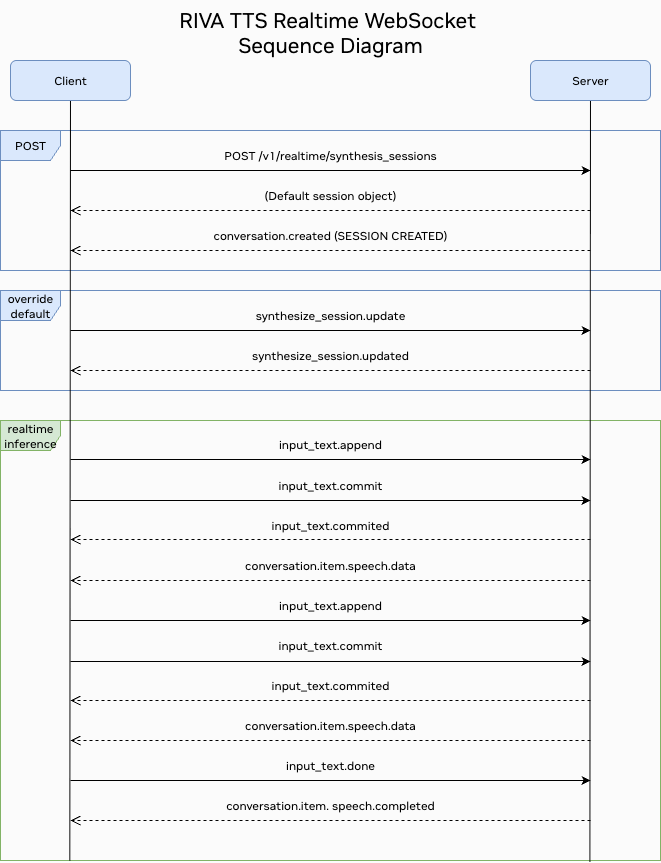
Events#
WebSocket events#
The realtime server uses a WebSocket-based event system for communication between clients and the server. Events are JSON messages that follow a specific format and are used to handle various operations like session management, text processing, and speech synthesis.
Each event has:
A unique
event_idfor trackingA
typefield indicating the event typeAdditional fields specific to the event type
Events are categorized into:
Client Events: Events sent from client to server
Session management (create, update)
Text buffer operations (append, commit)
Server Events: Events sent from server to client
Session responses (created, updated)
Speech synthesis results (data, completed, failed)
Error notifications
Status updates
The server validates all incoming events and sends appropriate error messages for:
Invalid event formats
Unsupported features
Message size limits
Server errors
Client Events#
Events that can be sent from the client to the server.
List of Client Events#
Event Type |
Description |
|---|---|
|
Updates session configuration |
|
Sends text data for processing |
|
Commits the current text buffer |
|
Signals completion of text input |
synthesize_session.update#
Send this event to update a synthesis session.
{
"event_id": "event_<uuid4>",
"type": "synthesize_session.update",
"session": {
"input_text_synthesis": {
"language_code": "en-US",
"voice_name": "English-US.Male-1"
},
"output_audio_params": {
"sample_rate_hz": 22050,
"num_channels": 1,
"audio_format": "LINEAR_PCM"
},
"custom_dictionary": "",
"zero_shot_config": {
"audio_prompt_bytes": "<base64_encoded_audio_data>",
"audio_prompt_transcript": "",
"prompt_quality": 20,
"prompt_encoding": "LINEAR_PCM",
"sample_rate_hz": 22050
}
}
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Event identifier |
auto-generated (“event_ |
type |
string |
Yes |
Event type |
“synthesize_session.update” |
session.input_text_synthesis.language_code |
string |
Yes |
Synthesis language code (e.g., “en-US”, “es-ES”) |
“en-US” |
session.input_text_synthesis.voice_name |
string |
No |
Voice to use for synthesis (e.g., “English-US.Male-1”, “English-US.Female-1”) |
“English-US.Male-1” |
session.output_audio_params.sample_rate_hz |
integer |
No |
Audio sample rate in Hz |
22050 |
session.output_audio_params.num_channels |
integer |
No |
Number of audio channels |
1 |
session.output_audio_params.audio_format |
string |
No |
Output audio format |
“LINEAR_PCM” |
session.custom_dictionary |
string |
No |
Custom pronunciation dictionary |
“” |
session.zero_shot_config.audio_prompt_bytes |
string |
No |
Base64-encoded audio prompt for zero-shot voice cloning |
“” |
session.zero_shot_config.audio_prompt_transcript |
string |
No |
Transcript of the audio prompt |
“” |
session.zero_shot_config.prompt_quality |
integer |
No |
Quality setting for zero-shot (1-40) |
20 |
session.zero_shot_config.prompt_encoding |
string |
No |
Encoding format of the audio prompt |
“LINEAR_PCM” |
session.zero_shot_config.sample_rate_hz |
integer |
No |
Sample rate of the audio prompt in Hz |
22050 |
input_text.append#
Sends text data to the server for processing. The server maintains a text buffer that accumulates text chunks until they are committed for synthesis. If the buffer is empty, a new chunk is created. If the buffer contains existing chunks, the new text is appended to the last chunk to maintain continuity.
{
"event_id": "event_0000",
"type": "input_text.append",
"text": "Hello, how are you today?"
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
event_0000 |
type |
string |
Yes |
Event type |
“input_text.append” |
text |
string |
Yes |
Text to synthesize. Maximum size: 1MB |
- |
input_text.commit#
Commits the current text buffer for processing.
{
"event_id": "event_0000",
"type": "input_text.commit"
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
event_0000 |
type |
string |
Yes |
Event type |
“input_text.commit” |
input_text.done#
Tells the server that the client is done sending text data and wants to stop the inference processing. This event triggers the server to process any remaining text chunks in the buffer and then stop the inference task.
Note
This parameter is mandatory for text file processing.
{
"event_id": "event_0000",
"type": "input_text.done"
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
event_0000 |
type |
string |
Yes |
Event type |
“input_text.done” |
Server Events#
These are events emitted from the server to the client.
List of Server Events#
Event Type |
Description |
|---|---|
|
Returned when a conversation is created |
|
Sent when session configuration is updated |
|
Returned when an input text buffer is committed |
|
Sent when new speech audio data is available |
|
Sent when speech synthesis is completed |
|
Sent when an error occurs |
conversation.created#
Returned when a conversation session is created.
{
"event_id": "event_<uuid4>",
"type": "conversation.created",
"conversation": {
"id": "conv_<uuid4>",
"object": "realtime.conversation"
}
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
auto-generated (“event_ |
type |
string |
Yes |
Event type |
“conversation.created” |
conversation.id |
string |
Yes |
The unique ID of the conversation |
auto-generated (“conv_ |
conversation.object |
string |
Yes |
Must be ‘realtime.conversation’ |
“realtime.conversation” |
synthesize_session.updated#
Returned when a synthesis session is updated.
{
"event_id": "event_<uuid4>",
"type": "synthesize_session.updated",
"session": {
"input_text_synthesis": {
"language_code": "en-US",
"voice_name": "English-US.Male-1"
},
"output_audio_params": {
"sample_rate_hz": 22050,
"num_channels": 1,
"audio_format": "LINEAR_PCM"
},
"custom_dictionary": "",
"zero_shot_config": {
"audio_prompt_bytes": "<base64_encoded_audio_data>",
"audio_prompt_transcript": "",
"prompt_quality": 20,
"prompt_encoding": "LINEAR_PCM",
"sample_rate_hz": 22050
}
}
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Event identifier |
auto-generated (“event_ |
type |
string |
Yes |
Event type |
“synthesize_session.updated” |
session.input_text_synthesis.language_code |
string |
Yes |
Synthesis language code (e.g., “en-US”, “es-ES”) |
“en-US” |
session.input_text_synthesis.voice_name |
string |
No |
Voice to use for synthesis (e.g., “English-US.Male-1”, “English-US.Female-1”) |
“English-US.Male-1” |
session.output_audio_params.sample_rate_hz |
integer |
No |
Audio sample rate in Hz |
22050 |
session.output_audio_params.num_channels |
integer |
No |
Number of audio channels |
1 |
session.output_audio_params.audio_format |
string |
No |
Output audio format |
“LINEAR_PCM” |
session.custom_dictionary |
string |
No |
Custom pronunciation dictionary |
“” |
session.zero_shot_config.audio_prompt_bytes |
string |
No |
Base64-encoded audio prompt for zero-shot voice cloning |
“” |
session.zero_shot_config.audio_prompt_transcript |
string |
No |
Transcript of the audio prompt |
“” |
session.zero_shot_config.prompt_quality |
integer |
No |
Quality setting for zero-shot (1-40) |
20 |
session.zero_shot_config.prompt_encoding |
string |
No |
Encoding format of the audio prompt |
“LINEAR_PCM” |
session.zero_shot_config.sample_rate_hz |
integer |
No |
Sample rate of the audio prompt in Hz |
22050 |
input_text.committed#
Returned when an input text buffer is committed. All accumulated text chunks in the buffer are sent for inference processing, and the buffer is cleared after processing.
{
"event_id": "event_0000",
"type": "input_text.committed",
"previous_item_id": "msg_0000",
"item_id": "msg_0001"
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
event_0000 |
type |
string |
Yes |
Event type |
“input_text.committed” |
previous_item_id |
string |
No |
ID of the preceding item |
msg_0000 |
item_id |
string |
No |
ID of the current item |
msg_0001 |
conversation.item.speech.data#
Returned speech audio data when response is received from gRPC server.
{
"event_id": "event_0000",
"type": "conversation.item.speech.data",
"item_id": "item_001",
"content_index": 0,
"audio": "<Base64EncodedAudioData>",
"is_last_chunk": false
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
event_0000 |
type |
string |
Yes |
Event type |
“conversation.item.speech.data” |
item_id |
string |
No |
Optional item identifier |
item_0000 |
content_index |
integer |
No |
The index of the content part |
0 |
audio |
string |
Yes |
Base64-encoded audio data |
- |
is_last_chunk |
boolean |
No |
Indicates if this is the final audio chunk for the text |
false |
conversation.item.speech.completed#
Returned when speech synthesis is completed.
{
"event_id": "event_0000",
"type": "conversation.item.speech.completed",
"item_id": "msg_0000",
"content_index": 0,
"total_audio_chunks": 5,
"synthesis_metadata": {
"text_length": 25,
"synthesis_time_ms": 1500,
"audio_duration_ms": 2000
},
"is_last_result": false
}
Parameters#
Parameter |
Type |
Required |
Description |
Default |
|---|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
event_0000 |
type |
string |
Yes |
Event type |
“conversation.item.speech.completed” |
item_id |
string |
Yes |
The ID of the item |
msg_0000 |
content_index |
integer |
Yes |
The index of the content part |
0 |
total_audio_chunks |
integer |
Yes |
Total number of audio chunks generated |
- |
synthesis_metadata |
object |
No |
Metadata about the synthesis process |
- |
synthesis_metadata.text_length |
integer |
No |
Length of the input text |
- |
synthesis_metadata.synthesis_time_ms |
integer |
No |
Time taken for synthesis in milliseconds |
- |
synthesis_metadata.audio_duration_ms |
integer |
No |
Duration of the generated audio in milliseconds |
- |
is_last_result |
boolean |
No |
Indicates if this is the final synthesis result for the text stream |
false |
error#
Returned when an error occurs.
{
"event_id": "<auto_generated>",
"type": "error",
"error": {
"type": "invalid_request_error",
"code": "invalid_event",
"message": "The 'type' field is missing.",
"param": null
}
}
Parameters#
Parameter |
Type |
Required |
Description |
|---|---|---|---|
event_id |
string |
No |
Optional event identifier |
type |
string |
Yes |
Must be ‘error’ |
error.type |
string |
Yes |
The type of error |
error.code |
string |
Yes |
Error code |
error.message |
string |
Yes |
A human-readable error message |
error.param |
string |
No |
Parameter related to the error, if any |
Available Voices and Models#
The TTS service provides access to various pre-trained voices and models. Query the available voices using the /v1/audio/list_voices HTTP endpoint.
Endpoint:
GET /v1/audio/list_voices
Response Example:
{
"en-US": {
"voices": [
"English-US.Male-1",
"English-US.Female-1",
"English-US.Male-2"
]
},
"es-ES": {
"voices": [
"tacotron2.spanish",
"fastpitch.spanish"
]
}
}
Note: Available voices and models depend on your Riva deployment configuration. Use the list_voices endpoint to discover what’s available in your environment.
Configuration#
Server Parameters#
Parameter |
Default Value |
Description |
|---|---|---|
expiration_timeout_secs |
3600 |
Session expiration timeout in seconds (1 hour) |
inactivity_timeout_secs |
60 |
Inactivity timeout in seconds |
max_connections |
100000 |
Maximum number of concurrent connections |
max_message_size |
15728640 |
Maximum message size in bytes (15MB) |
Error Handling#
The realtime server implements comprehensive error handling for various scenarios:
WebSocket Error Codes#
Code |
Description |
Action |
|---|---|---|
1000 |
Normal closure |
Connection closed normally |
1008 |
Policy violation |
Invalid intent or unsupported operation |
1011 |
Internal error |
Server encountered an error |
1013 |
Try again later |
Server temporarily unavailable |
Common Error Scenarios#
Invalid Intent: Connection closed with code 1008 if intent is missing or unsupported
Message Size Limits: Errors returned for messages exceeding 15MB limit
Session Timeout: Connections closed after inactivity timeout (60 seconds default)
Server Overload: Connection refused when max connections (100000) is reached
Error Response Format#
All errors follow the standard error event format:
{
"event_id": "event_0000",
"type": "error",
"error": {
"type": "error_type",
"code": "error_code",
"message": "Human-readable error message",
"param": "Additional parameter if applicable"
}
}
Client Development Resources#
For building realtime WebSocket clients in Python, refer to the NVIDIA Riva Python Clients repository.
Quick Start#
git clone https://github.com/nvidia-riva/python-clients.git
pip install -r requirements.txt
python scripts/tts/realtime_tts_client.py --help
Refer to the repository for complete examples and API documentation.