

Observability (Legacy Managed)
Observability (Legacy Managed)
Overview
NVIDIA Cloud Functions provides a comprehensive observability solution through two main approaches:
-
NGC UI/CLI Observability
- Basic metrics in the Overview tab
- Log data with time ranges in the Logs tab
- Limited to NGC account holders
- Enabled by default for all functions or tasks
See details on using the built-in observability features below.
-
External Observability Integration
- Send telemetry data to your organization’s observability platforms
- Support for logs, metrics, and traces
- Requires explicit configuration of telemetry endpoints
See external-observability for detailed instructions.
NGC UI Observability
The NGC UI provides basic observability through three main tabs:
-
Overview Tab
- Provides real-time status and performance metrics
- Shows instance counts and request statistics
- Displays basic function or task information
-
Logs Tab
- Access to container and event logs
- Real-time log streaming capabilities
- Search and filtering functionality
-
Metrics Tab
- Detailed performance indicators
- Time-series data visualization
- Resource utilization trends
You can access these tabs by navigating to your function in the NGC UI. Each tab offers specific insights into your function’s operation and performance.
Overview
The Overview tab provides access to your function’s current status and performance metrics, offering real-time insights into your function’s operation and health.
-
Basic Function or Task Metrics
- Current function or task status (Running, Stopped, Error)
- Last updated timestamp
- Function or task version
- Runtime environment details
-
Instance Counts
- Active instances
- Pending instances
- Failed instances
- Historical instance trends
-
Request Statistics
- Total requests processed
- Current request rate
- Success/failure ratios
- Average response times
How to Access
- Navigate to the Functions list page
- Click on your function
- The Overview tab is displayed by default
- Use the refresh button to update the data
- Overview data updates every 30 seconds
- Historical data is available for the last 24 hours
- Some metrics may have a slight delay in reporting
Logs
The Logs tab enables monitoring through detailed log access.
NVCF displays logs related to:
-
Deployment stages
- Function or Task Creation
- Function or Task Deployment
-
Function or task invocation logs
-
Real-time logs (listed in the UI under the Live Tail tab)
- For detailed information about real-time logging capabilities, see the NGC UI Logs tab described above.
Viewing Metrics
- Navigate to the Functions list page
- Click on your function
- Select the Metrics tab
The Metrics view displays:
Summary Statistics
- Total Invocations - Number of function calls in the selected time period
- Average Inference Time - Mean processing time for function calls
- Total Instance Count - Current number of running instances
- Failures - Count of failed executions
Time Series Graphs
- Invocation Activity and Queue Depth - Shows request patterns and queued requests
- Average Inference Time - Processing duration trends
- Instances Over Time - Shows scaling behavior
- Success Rate - Function reliability metrics
Use the time range selector (e.g., Past 1 Hour) in the top right to adjust the view period.
- Minor discrepancies may occur in aggregated invocations due to rounding, especially with smaller values
- Most recent metrics may be delayed
- Metrics have a 5-minute ingestion delay
NGC UI access is limited to NGC account holders. For broader observability access, work with your account administrator to configure external observability endpoints.
External Observability
Configure external observability endpoints to monitor your NVIDIA Cloud Functions. By setting up telemetry endpoints, you can stream metrics (see appendix-b), logs, and traces to popular observability platforms like Grafana Cloud and Datadog. This extends beyond the basic metrics in NGC UI, giving you deeper insights into your functions’ performance.
To export function or task telemetry through external observability platforms, your source code must be instrumented using OpenTelemetry. Without proper OpenTelemetry instrumentation, only system-level metrics will be available.
Ports
The OpenTelemetry collector uses the following ports:
-
OTLP (OpenTelemetry Protocol)
- OTLP gRPC: Port 14357
- OTLP HTTP: Port 14358
-
Metrics
- Port 18888 - Used for collector metrics
-
Health Check
- Port 13133 - Used for health check endpoint
These ports are reserved for the OpenTelemetry collector and should not be used by your functions or tasks.
Configuration
Telemetry endpoints can only be configured when creating a new function or deploying a new version. You cannot add a telemetry endpoint to an existing function deployment.
A Telemetry Endpoint is a configuration that specifies where telemetry data is sent. This is allowed for all functions or tasks to be configured to send telemetry data to an external observability platform.
- Configure External Telemetry Endpoints
Remember that to collect custom metrics, logs, and traces from your function’s or task’s code, you must instrument your application using OpenTelemetry. System-level metrics (CPU, memory, GPU) are collected automatically.
You can configure telemetry endpoints using either the web UI or the NGC CLI:
Web UI Method:
- Navigate to your NGC organization settings
- Select “Settings” in your Cloud Functions NGC organization
- Scroll to the bottom of the page
- Click “Add Telemetry Endpoint”

- Select your desired endpoint type (Grafana Cloud or Datadog)
- Configure the endpoint with the required credentials
Grafana Cloud
Follow these steps to set up Grafana Cloud integration with NVCF:
Web UI Method:
-
Access Grafana Cloud
-
For new users:
-
Complete the free Grafana Cloud registration process
-
For existing users:
-
Log in with your credentials
-
Configure OpenTelemetry
-
In the top menu bar, locate “My Account”
-
Expand the Details section by clicking the icon
-
Access OpenTelemetry Settings
-
In your Grafana Cloud stack, locate the OpenTelemetry card
-
Click “Configure” to access the OpenTelemetry configuration
-
You will see options for configuring:
-
Metrics
-
Logs
-
Traces
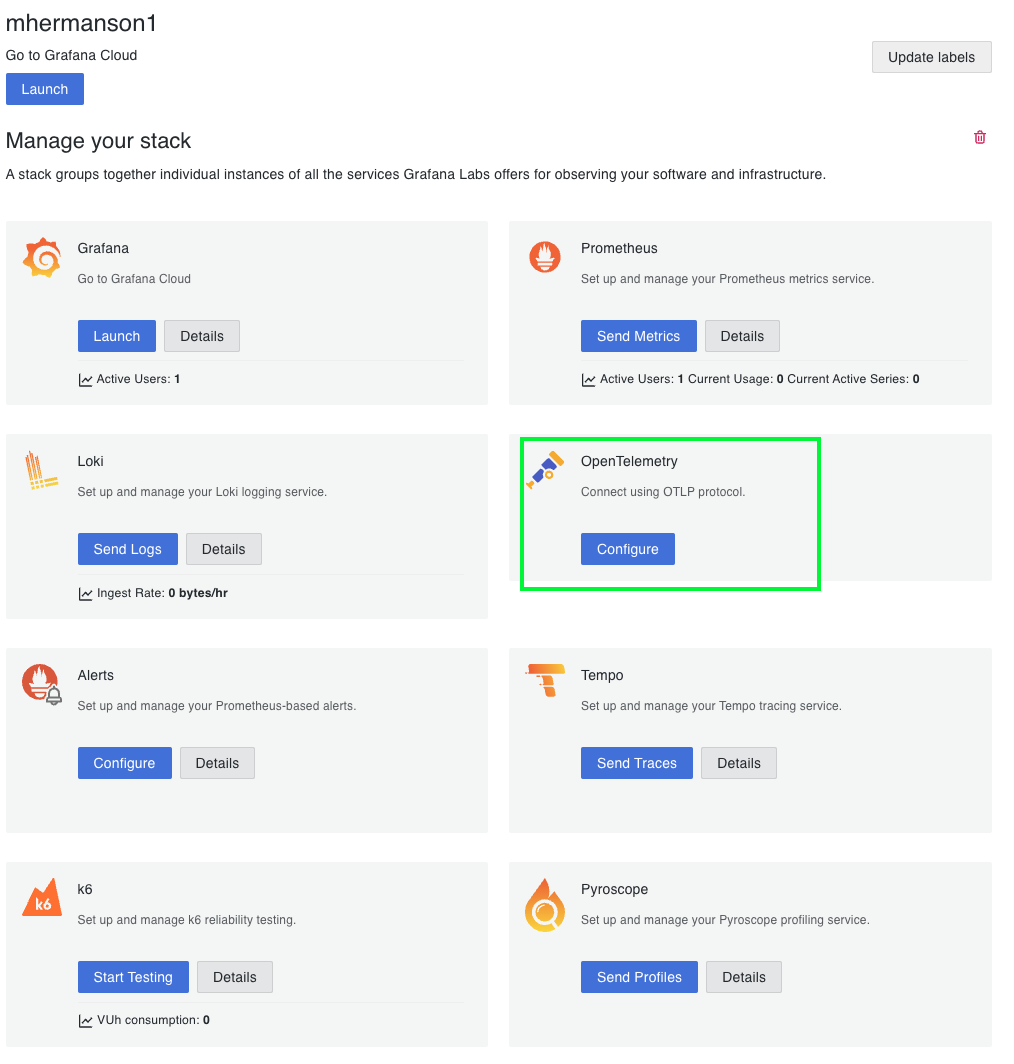
-
Locate OTLP Configuration Details
-
The OTLP endpoint section will display:
-
OTLP Endpoint URL (e.g., https://otlp-gateway-prod-us-west-0.grafana.net/otlp)
-
Instance ID (a numeric identifier for your instance)
-
API Token section with option to “Generate now”
-
Use the “Copy to Clipboard” buttons to easily copy these values into the NVCF Telemetry Endpoint configuration.
Alternative: Create Grafana Telemetry Endpoint via CLI
As an alternative to the web UI, you can create the Grafana Cloud telemetry endpoint using the NGC CLI:
Keep your API Token secure and never share it publicly. If your token is compromised, you can generate a new one and update your configuration.
Datadog
Follow these steps to set up Datadog integration with NVCF:
Web UI Method:
-
Sign Up for Datadog
-
Visit the Datadog Getting Started page
-
Complete the registration process for a new Datadog account
-
Configure API Key
-
Log in to your Datadog account
-
Navigate to Organization Settings (found in the bottom left corner of the page)
-
Select API Keys from the left menu
-
Either click “+New Key” to create a new API key or copy an existing one from the list
-
Get Telemetry Endpoint
-
Your endpoint URL will be displayed in the browser address bar
-
Available endpoints based on your instance location:
-
datadoghq.com (US1)
-
us3.datadoghq.com (US3)
-
us5.datadoghq.com (US5)
-
datadoghq.eu (EU1)
-
ddog-gov.com (US1-FED)
-
For more details on Datadog sites and endpoints, see the Datadog site documentation
-
Configure in NVCF Web UI
-
Input the configuration details:
-
API Key (copied from step 2)
-
Endpoint URL (selected from step 3)
-
Select telemetry type(s):
-
Choose “Logs” to send log data
-
Choose “Metrics” to send metrics data
-
You can select both to send both types of telemetry
-
Save the configuration
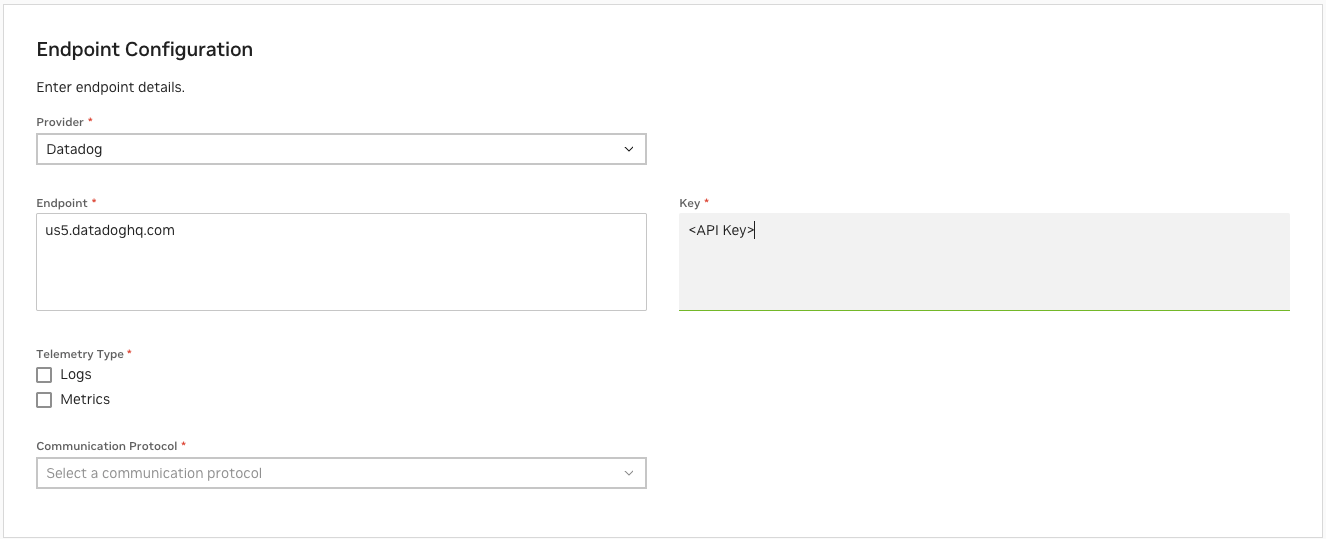
Alternative: Create Datadog Telemetry Endpoint via CLI
As an alternative to the web UI, you can create the Datadog telemetry endpoint using the NGC CLI:
Make sure to keep your API key secure and never share it publicly. If your key is compromised, you can generate a new one and update your configuration.
CLI Method:
As an alternative to the web UI, you can use the NGC CLI to manage telemetry endpoints. Here are the basic CLI commands:
- Endpoint names must be unique within your NGC organization
- API tokens and keys are stored securely in NGC Encrypted Secrets Store and can be updated if needed
- Endpoint configurations cannot be updated - delete and recreate to change settings
-
Add Telemetry Endpoint to Function or Task
Telemetry endpoints can only be configured when creating a new function or deploying a new version. You cannot add a telemetry endpoint to an existing function deployment.
Web UI Method:
When creating a new function or deploying a new version:
- In the function creation/deployment form
- Look for the Telemetry Endpoints section
- Select the desired telemetry endpoint from the dropdown
- Complete the rest of the function creation/deployment process
If you need to change the telemetry endpoint for an existing function, you must deploy a new version of that function with the updated telemetry configuration.
-
Verify Deployment
After deploying the function with the telemetry endpoint, verify that the telemetry data is flowing correctly to your observability platform.
If you don’t see your custom metrics, logs, or traces in your observability platform, verify that:
- Your function’s or task’s code is properly instrumented with OpenTelemetry
- The telemetry endpoint is correctly configured
- The function or task deployment is active and running
Grafana Cloud
-
Log in to your Grafana Cloud account
-
Navigate to the Metrics Explorer
-
Search for the following metrics to verify data flow:
-
DCGM_FI_DEV_GPU_UTIL - Shows GPU utilization percentage
-
container_fs_reads_bytes_total - Shows container filesystem read metrics
-
container_fs_writes_bytes_total - Shows container filesystem write metrics
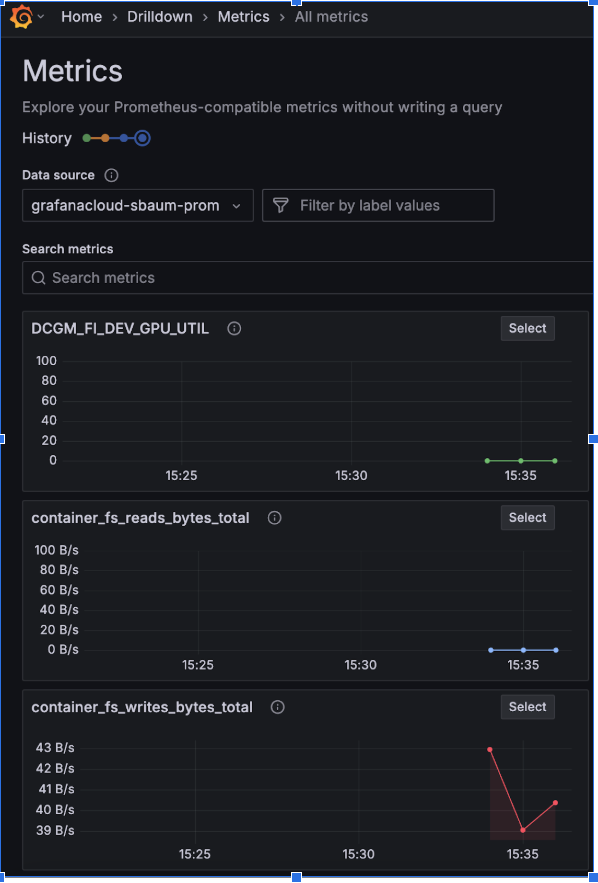
Datadog
-
Log in to your Datadog account
-
Navigate to the Metrics Explorer
-
Search for “nvidia.cloud.function” to find your function’s metrics
-
You can view metrics such as:
-
GPU utilization
-
Function or task invocations
-
Request latency
-
Resource usage
The OpenTelemetry collector version, image and configuration are managed entirely by NVCF and cannot be modified by users.
-
Delete a Function or Task and Remove Telemetry Endpoint
To remove a telemetry endpoint, you must first cancel all deployments and remove all functions that use that endpoint. The endpoint cannot be removed while any functions are still using it, even if those functions are not currently deployed.
Web UI method:
-
Navigate to the Functions list page
-
Click on the function you want to delete
-
Navigate to the Deployments tab
-
For each deployment:
- Click “Cancel Deployment” and confirm
- Wait for all deployments to be fully cancelled
-
Navigate to the Settings tab
-
Click “Delete Function” and confirm
-
Verify the function is completely removed
-
After all functions using the telemetry endpoint have been removed:
- Navigate to your NGC organization settings
- Select “Settings” in your Cloud Functions NGC organization
- Scroll to the Telemetry Endpoints section
- Find the endpoint you want to remove
- Click the delete icon next to the endpoint
- Confirm the deletion
CLI method:
-
All deployments must be fully cancelled before function removal. The function must be completely removed before the endpoint can be removed. Removing a telemetry endpoint will permanently delete the endpoint configuration. Make sure to export any necessary telemetry data before removing endpoints.
When you select a telemetry endpoint, NVCF:
- Deploys a dedicated OpenTelemetry collector with your function or task
- Automatically configures authentication and endpoint connections
- Enables collection of metrics, logs, and traces from your function or task
- Directs telemetry data to your organization’s observability platform
Resource Management
In the pod for each function or task, an OpenTelemetry collector is deployed. This collector has automatic memory management and built-in resource protection to ensure reliable telemetry collection without impacting function or task performance. NVCF manages all resource allocation for the collector, so you don’t need to worry about resource configuration.
Security
NVCF ensures secure telemetry handling by storing credentials securely in the NGC Encrypted Secrets Store, Each collector only accesses its own function’s or task’s data, and authentication is handled automatically. Credentials are rotated securely to maintain security and integrity.
How to Set Up External Observability on a BYOC Cluster
BYOC Steps
-
BYOC cluster registered with NVCA on
2.46.10+version- See the NGC-Managed Clusters page for upgrade instructions.
-
Ensure the
Bring Your Own Observabilitycluster feature is enabled. If you are running a cluster agent version older than2.50.0, refer to the Configuration page for managing feature flags.

Error Handling
If issues occur with telemetry collection:
- Your function or task continues to run normally
- Error messages are logged for troubleshooting
- Health status is monitored and reported
- Automatic retry logic handles temporary failures
The collector’s health can be monitored through:
- Status checks in the NGC UI
- Metrics in your observability platform
- Built-in health endpoints
Appendix A: Terminology
Appendix B: Available Metrics
The following metrics are collected through the OpenTelemetry collector deployed with your function when using External Observability and exported through your configured Telemetry Endpoints. The metrics exported depend on the Kubernetes deployment used by the function or task.
Key metrics include:
- Function or task invocation metrics
- Resource utilization metrics
- Platform metrics related to the function or task
Metrics are filtered based on deployment type and configuration. Not all metrics may be available for all deployment scenarios.
CPU Metrics
Memory Metrics
Filesystem Metrics
Only present if the container is performing IO operations:
Network Metrics
Only present if the container is performing network operations:
Kubernetes State Metrics
Only present if helm-based function has a deployment k8s object:
Only present if helm-based function has a replicaset k8s object:
Only present if helm-based function has a stateful k8s object:
Only present if the helm-based function has a job/cronjob k8s object:
Only present if function has a configmap k8s object:
Only present if function has a secret k8s object:
Only present if function has a pod k8s object:
Only present if function/task helm deployments:
Only present if function/task helm defined an init container:
GPU Metrics
Always present for container and helm:
For detailed information about all available DCGM field IDs and GPU metrics, see the NVIDIA DCGM API Field IDs documentation.
NVCF Worker Service Metrics
Streaming metrics are only present for streaming functions.
All NVCF metrics include the label origin: nvcf-byoo.
NVCA Instance Type Metrics
Present for cluster management:
OpenTelemetry Collector Metrics
Always present for container and helm. The final list of metrics depends on telemetries received & exported by function/task:
Resource Attributes
All logs and metrics have the following attributes added to their metadata:
The platform metrics have the following attributes when available:
jobattribute is available in Grafana Cloudserviceis used in Datadog instead of attributejob
Appendix C: Adding Custom Application Metrics/Logs/Traces
You can export custom metrics/logs/traces to your external observability platform by sending them to the OpenTelemetry collector. Refer to the following table for the available environment variables that you can specify: