MinMaxLoc#
Overview#
The Minimum/Maximum Location algorithm does a 2D search on the input image for all pixel locations that exactly matches the global minimum/maximum values. This operation is useful to locate peaks on an image.
Algorithm Description#
In PVA algorithms, each VPU processes one tile (a small part of the image) at a time. In order to achieve global min/max locations with only local access, there are mainly two kinds of methods:
2-Pass Method#
The 2-pass method iterates tiles over the image twice.
1st pass: obtain global min/max values
In each tile, calculate local min/max values, and update the global min/max values.
2nd pass: obtain global min/max locations
In each tile, compare tile pixel values with the global min/max values to get global min/max locations.
The 2-pass method is pretty straightforward, and the 2nd pass could be done totally in parallel for different tiles, thus is preferred on multi-threaded platforms like GPU.
On PVA, the following 1-pass method turns out to achieve better computing efficiency, which is therefore adopted in our example implementation.
1-Pass Method#
In 1-pass method, we only iterate over all tiles once. We keep track of the temporary global min/max values and locations, and clear previous results when new global min/max values occur.
Specifically speaking, for each tile the following steps are performed:
Compute local min&max values of the tile;
For each of min and max, do steps 2 - 4:
Compare the local optimum with the temporary global optimum. If the local optimum is:
worse than the temporary global(min is larger, or max is smaller), skip updating locations;
better than the temporary global(min is smaller, or max is larger), update the temporary global value, and clear locations buffers(both in VMEM and DRAM, explained later in the Output Data Flow section);
If the local optimum is no worse than(equivalent to or better than) the temporary global optimum, calculate locations that equals to the local optimum, and append results to the VMEM location buffers;
If the VMEM location buffer is almost full(not enough space for another tile), trigger writing data flow to move locations out to DRAM location buffers.
Compared with the 2-pass method, the 1-pass method saves time by reading the image only once, but could spend more time on processing temporary locations and writing them out. The trade-off between these two factors depends on the number of temporary locations, which is determined by the input data distribution. This data-dependent nature of 1-pass method’s performance is further discussed in later sections.
Implementation Details#
In our example implementation, the MinMaxLoc operator returns global minimum and maximum values, total counts for min and max locations,
as well as a limited number(see the Capacity section below) of min and max location coordinates in the form of XY-interleaved 1D vectors.
We support seven input data types: uint8, int8, uint16, int16, uint32, int32, and float32.
This demonstrates how to write VPU kernels for different data types using a unified control logic, covering a wide range of use cases.
The example MinMaxLoc operator can be applied to find peaks in not only images, but also feature maps of signed integer or floating point values.
Capacity#
This parameter sets the maximum number of locations that can be returned for either the minimum or maximum values. It is obtained from the size of location tensors in DRAM, which is allocated by the user. That is to say, the user can determine the location tensor size according to how many min/max location coordinates are desired. If only a few examples of the min/max locations instead of all are needed, allocating a small location buffer is enough, and the VPU kernel latency would reduce due to less amount of post-processing and writing out location results.
Support for Arbitrary Image Sizes#
In order to load a large image into PVA’s VMEM, the tiling technique is usually adopted. We divide image into 2D patches and load one tile at a time. It is very likely that the image width/height is not divisible by the tile width/height, in which case the last (rightmost) column tiles or the the last (bottom) row tiles might require extra effort.
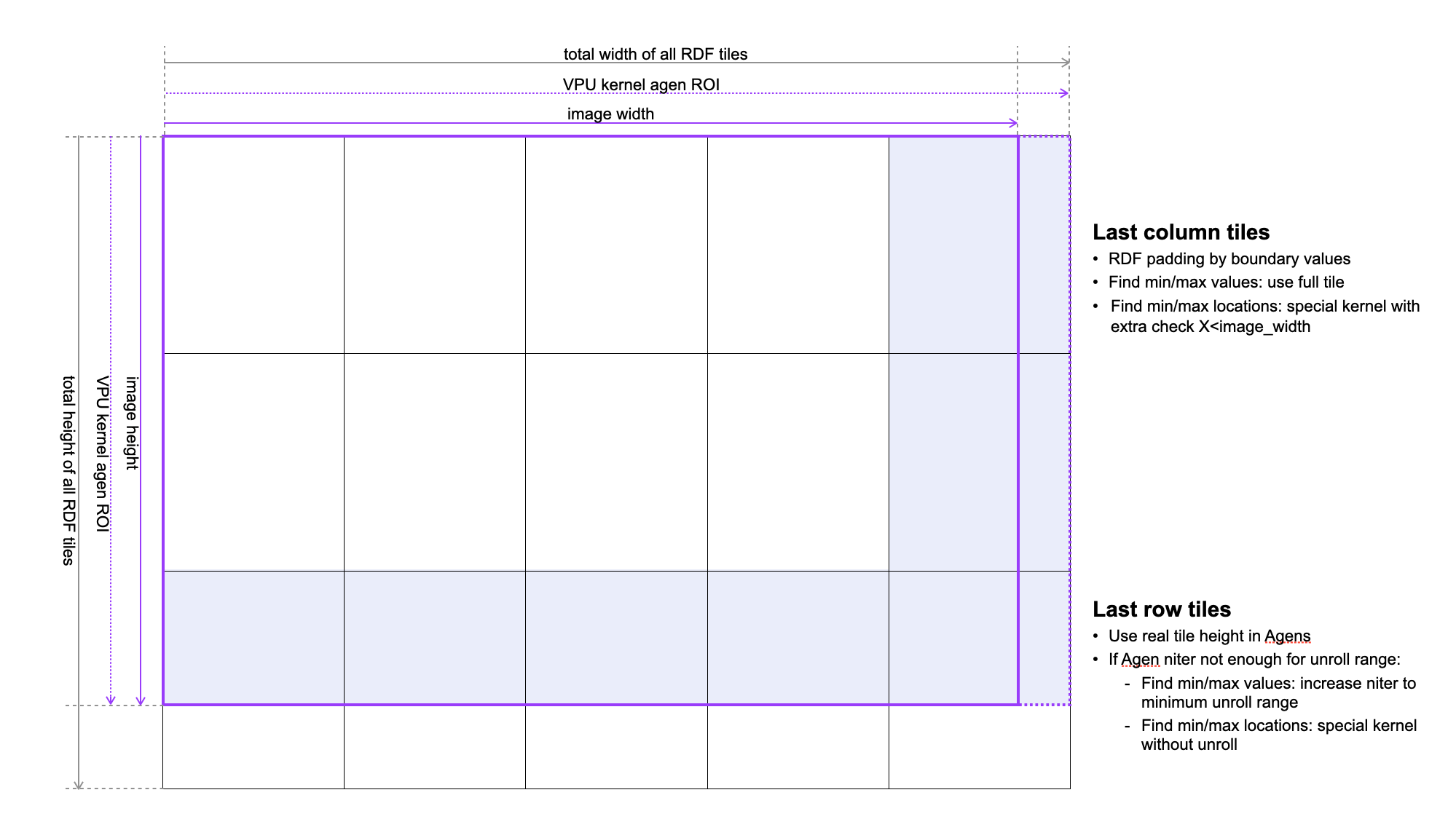
Figure 1: tiling for input image, when the image size is not divisible by the tile size#
Input Data Flow: RasterDataFlow(RDF)#
RasterDataFlow(RDF) is utilized to read image tiles into VMEM. The tile size is set to be \(64 \times 128\). When the image width/height is not divisible by the tile width/height, the last(rightmost) column tiles or the the last(bottom) row tiles are not of full tile size. RDF loads the last column/row tiles by the normal tile size with padding in out-of-range pixels.
There are two supported padding modes: padding by constant and padding by boundary-pixel-extension. We choose the latter, so that the padded data would not introduce new min/max values. In particular, each tile in our implementation has 2 kinds of VPU kernel functions:
1. Find local min/max values.#
For the padded tiles, the padded data are extension of boundary values in the same tile, so the local min/max values of the padded tiles are the same as that of the actual data in the tile. The value functions can be directly applied.
Additionally, for the last row tiles, we could calculate only for valid data rows to save unnecessary cycles. In fact, VPU kernel functions access data by AGEN(address generation), each time loading/storing a vector of pixels. 2D patches are processed row by row. The AGEN iteration row number could be set to the valid data height instead of the tile height to avoid processing padded data.
2. Find locations of the the same value as the given value.#
Padding by boundary values is not enough for the location functions, since coordinates must not exceed the image boundaries. The padded data affects the location functions in the following two ways:
Last column tiles: vector intrinsic fails
In the last column tiles, if the valid data width is not divisible by the AGEN vector size, then padded data would come into the same vector with normal data. Accordingly, we add a special function with an extra cycle to check \(X<\text{IMAGE}\_\text{WIDTH}\).
Last row tiles: unrolling factor or range not satisfied
VPU kernel functions usually applies unrolling in the critical loop for software pipelining. The AGEN iteration number must be multiples of the unrolling factor and no less than the unrolling range. Typically, this is achieved by rounding up the AGEN iteration number to multiples of the unrolling factor which are at least the unrolling range.
For the location functions, we use the valid data height instead of the tile height in AGEN to get rid of padded rows as mentioned above. Location coordinates are written to VMEM buffers without using AGEN-based store instructions, so there are no predicate features. Increasing the AGEN iteration number would introduce invalid coordinates and therefore is not allowed. If the AGEN iteration number does not satisfy the unrolling factor or range conditions, we use a special version of the location function without unrolling.
Output Data Flow: SequenceDataFlow(SQDF)#
In VPU kernels, temporary min/max locations are saved in VMEM, with X and Y coordinates in separate buffers. Once the VMEM buffers do not have enough space for another tile, an output data flow from VMEM to DRAM is triggered to move all coordinates out.
Since the final location coordinates are required to be in XY-interleaved format, there is an extra post-processing step to interleave X and Y coordinates and save results to another buffer in VMEM. This buffer is then used as the source data for the output data flow.
The output data flow of min/max locations from VMEM to external memory has three difficulties:
1. No fixed number of triggers#
The total number of min/max locations in the input is data-dependent, thus how many times the output data flow needs to be triggered is not known in advance.
2. Dynamic external memory access#
In the 1-pass method, whenever new min/max value occurs, the previous results in VMEM and DRAM buffers need to be cleared. Clearing the DRAM buffer means resetting external memory address in the output data flow.
3. Dynamic tile size#
The output data flow is triggered once the VMEM buffer does not have enough space for another tile, and then all location coordinates in the VMEM buffer are moved out. Consequently, the number of locations moved out each time could be different. The output data flow should also support dynamic tile size for each trigger.
To the best of our understanding, SequenceDataFlow (SQDF) is the most suitable choice. In our implementation, SQDF updates the VMEM address, DRAM address and tile size before each trigger.
Ping-Pong Buffers#
We use ping-pong buffers for both reading/writing tiles, to hide the load/store latency by computation.
Reduce Unnecessary Location Calculations#
For each tile, the VPU kernels first calculate the local min/max values, and then determine whether calculations for min/max locations are needed according to how they compare to the temporary global min/max values. For each of min and max, if the local optimum is already worse than the temporary global optimum, that is to say if the local min is larger than the temporary global min or the local max is smaller than the temporary global max, then calculation for its locations could be skipped since there is no global min/max locations in this tile for sure.
To be exact, there are three kinds of scenarios:
1. Both local min and max values are worse than temporary global values.#
No need to calculate locations, directly continue to the next tile.
2. One of local min and max is worse than its temporary global value.#
Only calculate locations for that optimum.
3. Both local min and max values are as good as temporary global values.#
Calculate locations for both min and max values.
Essentially, the location functions collect coordinates of pixels of the same value as the given input values. To reduce unnecessary computation as much as possible, we use different kernel functions for scenario 2 and 3. Functions for scenario 2 calculate locations for a single input value(either min or max that requires computation), while functions for scenario 3 calculate locations for 2 input values(both min and max). Rather than calling the function with a single input twice, the function with 2 inputs in scenario 3 saves cycles by sharing the logic of managing X and Y coordinates.
The overall process is summarized in the following diagram:
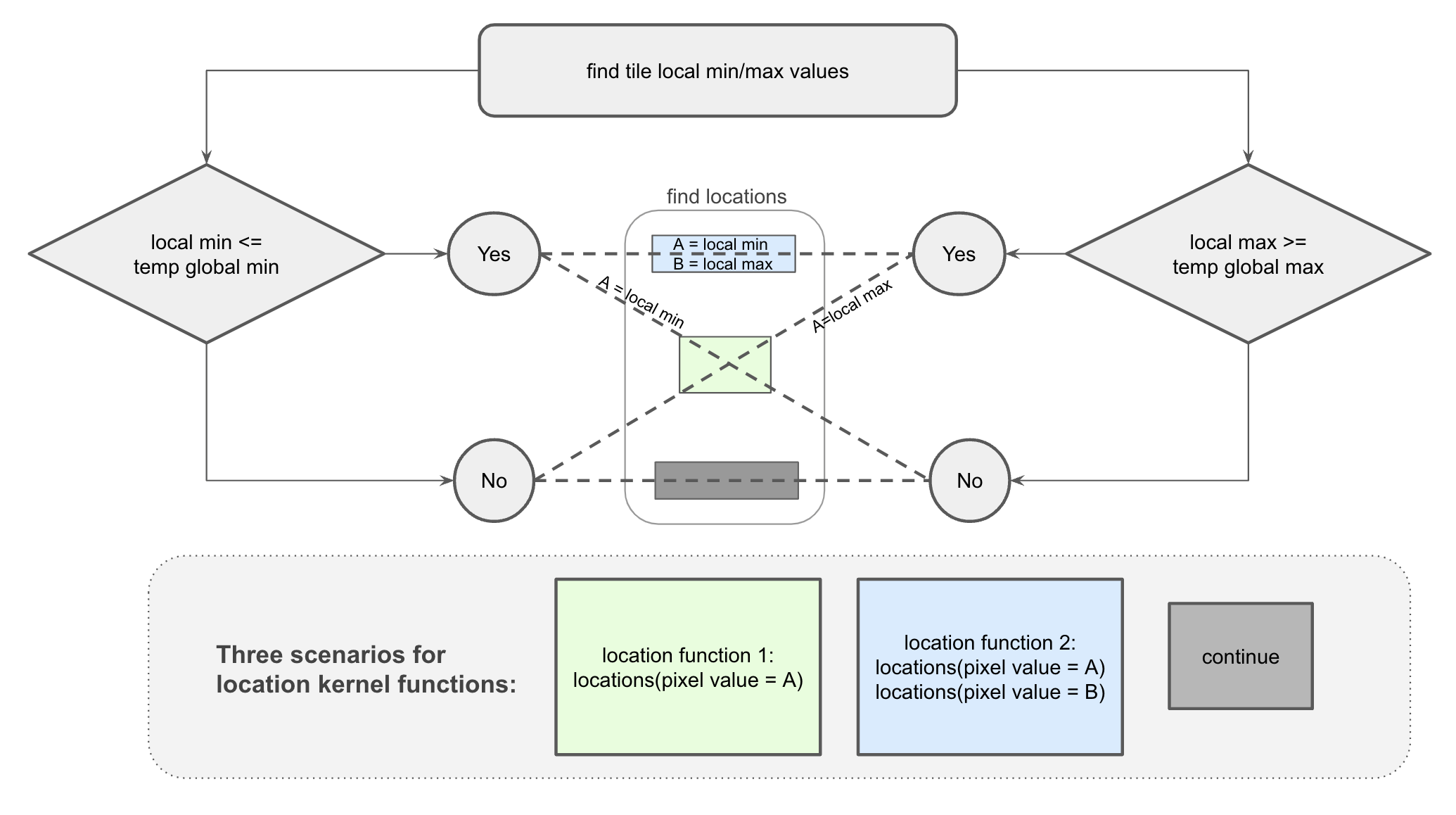
Figure 2: three scenarios of a tile in finding locations#
We use A and B to represent different input values for location functions, emphasizing that the two kinds of location functions are essentially classified by the number of input values to collect locations for: one takes one, and the other takes two. A and B for each case are the corresponding min/max values annotated in the diagram. The crossed lines with a green rectangle at the intersection point illustrate that the two cases with one Yes and one No are sharing the same location function.
Performance#
ImageSize |
DataType |
LocCapacity |
Execution Time |
Submit Latency |
Total Power |
|---|---|---|---|---|---|
1920x1080 |
U8 |
20 |
0.338ms |
0.043ms |
11.932W |
1920x1080 |
U8 |
200000 |
0.343ms |
0.041ms |
11.932W |
1920x1080 |
S8 |
20 |
0.486ms |
0.027ms |
11.63W |
1920x1080 |
S8 |
200000 |
0.488ms |
0.029ms |
11.63W |
1920x1080 |
U16 |
20 |
0.363ms |
0.042ms |
12.915W |
1920x1080 |
U16 |
200000 |
0.368ms |
0.043ms |
12.915W |
1920x1080 |
S16 |
20 |
0.363ms |
0.042ms |
12.915W |
1920x1080 |
S16 |
200000 |
0.368ms |
0.044ms |
12.915W |
1920x1080 |
U32 |
20 |
0.562ms |
0.043ms |
13.226W |
1920x1080 |
U32 |
200000 |
0.567ms |
0.044ms |
13.126W |
1920x1080 |
S32 |
20 |
0.562ms |
0.042ms |
13.126W |
1920x1080 |
S32 |
200000 |
0.567ms |
0.044ms |
13.226W |
1920x1080 |
F32 |
20 |
0.720ms |
0.042ms |
12.332W |
1920x1080 |
F32 |
200000 |
0.726ms |
0.043ms |
12.332W |
For detailed information on interpreting the performance table above and understanding the benchmarking setup, see Performance Benchmark.