Introduction#
Added in version 2.0.
Red Hat OpenShift#
Red Hat and NVIDIA have partnered to unlock the power of AI for every business by delivering an end-to-end enterprise platform optimized for AI workloads. This integrated platform delivers best-in-class AI software, the NVIDIA AI Enterprise suite, optimized and certified for Red Hat OpenShift, the industry’s leading Containers and Kubernetes platform. Running on NVIDIA-Certified Systems™, industry-leading accelerated servers, this platform accelerates the speed at which developers can build AI and high-performance data analytics, enabling organizations to scale modern workloads on the same infrastructure they have already invested in, and delivers enterprise-class manageability, security, and availability. Furthermore, with Red Hat OpenShift, enterprises have the flexibility to deploy in either bare-metal or virtualized environments with VMware vSphere.
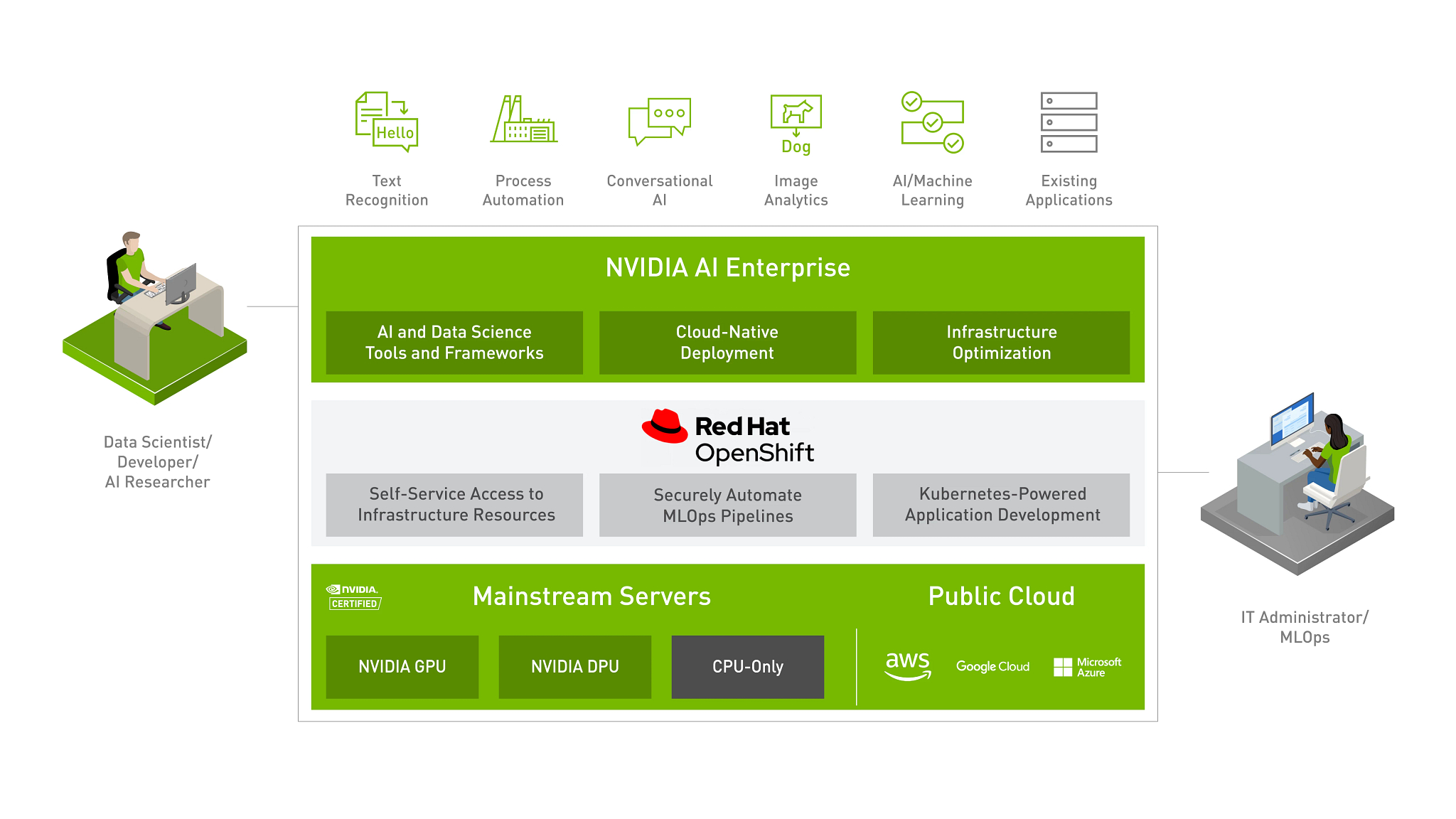
The benefits of this joint NVIDIA and Red Hat AI-Ready Platform solution are:
Ease Of Deployment and Scaling
Enterprises can confidently deploy and scale an end-to-end AI solution certified by NVIDIA and Red Hat on NVIDIA-Certified Systems. This includes the flexibility to consistently deploy the NVIDIA AI Enterprise and data analytics software on Red Hat OpenShift, on bare metal or existing VMware vSphere across data centers and edge. Red Hat OpenShift’s integration with NVIDIA GPUs using the certified Kubernetes Operator and containerized AI software derisks deployments and enables seamless scaling.
Empower self-service access to AI tools and infrastructure
NVIDIA AI Enterprise on Red Hat OpenShift enables self-service, consistent, cloud-like experience for data scientists, ML engineers, and developers with the flexibility and portability to use the containerized AI tools and infrastructure resources. This allows them to rapidly build, scale, reproduce, and share the models before production rollout. They also have access to out of the box trusted, tried, tested AI tools to increase productivity and achieve faster time to value.
Secure delivery of intelligent applications with integrated MLOps
Extending OpenShift DevOps and GitOps automation capabilities to the entire AI lifecycle allows better collaboration between data scientists, ML engineers, software developers, and IT operations. This enables organizations to automate and simplify the iterative process of integrating models into software development processes, production rollout, monitoring, retraining, and redeployment for continued prediction accuracy.
NVIDIA GPU Operator#
GPU Operator enables DevOps teams to manage the lifecycle of GPUs when used with Red Hat OpenShift at a cluster level. There is no need to manage each node individually. When the GPU Operator is used with Red Hat OpenShift, infrastructure teams can easily manage GPU and CPU nodes from same cluster control plane. The GPU Operator allows customers to run GPU accelerated applications on immutable operating systems as well. Faster node provisioning is achievable since the GPU Operator has been built in a way that it detects newly added GPU accelerated Kubernetes worker nodes and then automatically installs all software components required to run GPU accelerated applications. The GPU Operator is a single tool to manage all Kubernetes components (GPU Device Plugin, GPU Feature Discovery, GPU Monitoring Tools, NVIDIA Runtime). It is important to note, GPU Operator installs NVIDIA AI Enterprise Guest Driver as well.
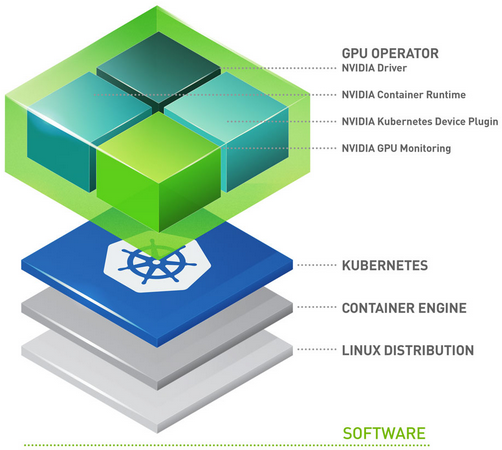
The components are as follows:
GPU Feature Discovery, which labels the worker node based on the GPU specs. This enables customers to more granularly select the GPU resources that their application requires.
The NVIDIA AI Enterprise Guest Driver
Kubernetes Device Plugin, which advertises the GPU to the Kubernetes scheduler
NVIDIA Container Toolkit - allows users to build and run GPU accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs.
Data Center GPU Manager (DCGM) Monitoring - Allows monitoring of GPUs on Kubernetes.
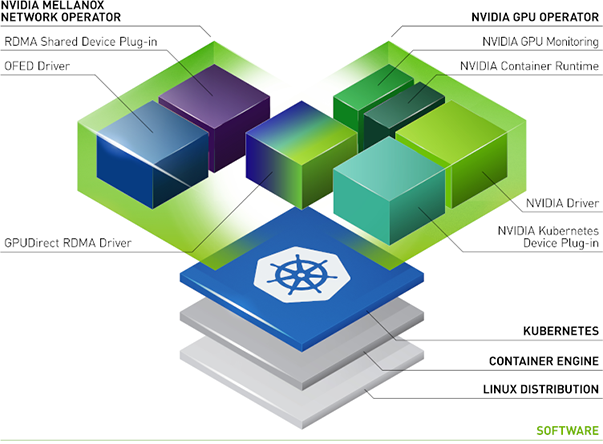
NVIDIA Network Operator#
The NVIDIA Network Operator leverages Kubernetes custom resources and the Operator framework to enable fast networking, RDMA, and GPUDirect.
Install NGC Catalog CLI (Optional)#
To access the NVIDIA AI Enterprise Software, you must first download and install NGC Catalog CLI. After the NGC Catalog CLI is installed, you will need to launch a command window and then run commands to download software. It is recommended that the NGC CLI is installed on the same machine that may be used to interact with the OpenShift Cluster or ESXi hosts.
To install NGC Catalog CLI
Enter the NVIDIA NGC website
In the top right corner, click Welcome and then select Setup from the menu.
Click Downloads under Install NGC CLI from the Setup page.
From the CLI Install page, click the Windows, Linux, or MacOS tab, according to the platform from which you will be running NGC Catalog CLI.
Follow the instructions to install the CLI.
Open a Terminal or Command Prompt
Verify the installation by entering
ngc--version. The output should beNGC Catalog CLI x.y.zwhere x.y.z indicates the version.You must configure NGC CLI for your use so that you can run the commands. Enter the following command and then include your API key when prompted:
$ ngc config set Enter API key [no-apikey]. Choices: [<VALID_APIKEY>, 'no-apikey']: (COPY/PASTE API KEY) Enter CLI output format type [ascii]. Choices: [ascii, csv, json]: ascii Enter org [no-org]. Choices: ['no-org']: no-org Enter team [no-team]. Choices: ['no-team']: no-team Enter ace [no-ace]. Choices: ['no-ace']: no-ace