Overview#
NVIDIA AI Enterprise offers the flexibility run AI workloads within VMs but if you want to embrace containers, upstream Kubernetes is also offered.
By leveraging Kubernetes, the IT Administrator can automate deployments, scale and manage containerized AI applications and frameworks.
What is Kubernetes?#
Kubernetes is an open-source container orchestration platform that makes the job of a DevOps engineer easier. Applications can be deployed on Kubernetes as logical units which are easy to manage, upgrade and deploy with zero downtime (rolling upgrades) and high availability using replication. Deploying Triton Inference Server on Kubernetes offers these same benefits to AI in the Enterprise. To easily manage GPU resources in the Kubernetes cluster, the NVIDIA GPU operator is leveraged.
What is Helm?#
Helm is an application package manager running on top of Kubernetes. Helm is very similar to what Debian/RPM is for Linux, or what JAR/WAR is for Java-based applications. Helm charts help you define, install, and upgrade even the most complex Kubernetes applications.
What is the NVIDIA Network Operator?#
The NVIDIA Network Operator leverages Kubernetes custom resources and the Operator framework to configure fast networking, RDMA, and GPUDirect. The Network Operator’s goal is to install the host networking components required to enable RDMA and GPUDirect in a Kubernetes cluster. It does so by configuring a high-speed data path for IO intensive workloads on a secondary network in each cluster node.
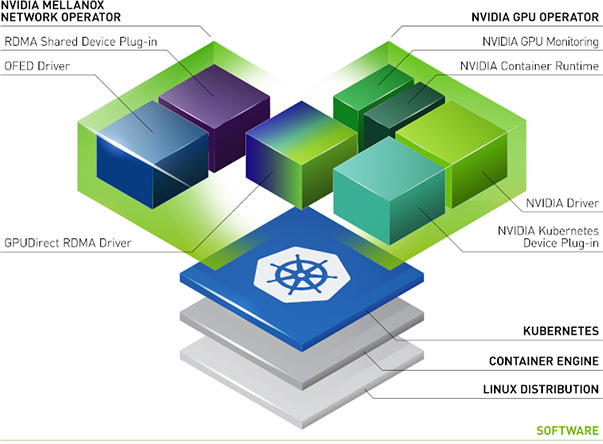
What is the NVIDIA GPU Operator?#
The GPU Operator allows DevOps Engineers of Kubernetes clusters to manage GPU nodes just like CPU nodes in the cluster. Instead of providing a special OS image for GPU nodes, administrators can deploy a standard OS image for both CPU and GPU nodes and then rely on the GPU Operator to provide the required software components for GPUs.
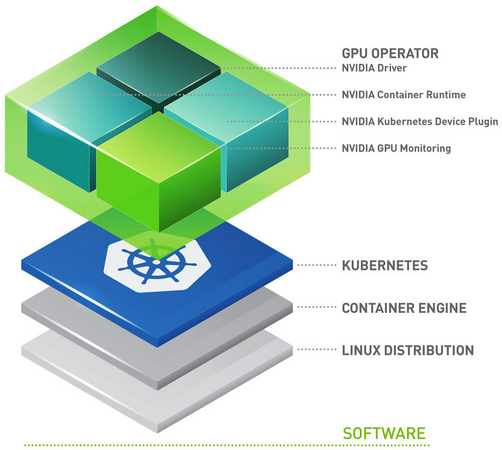
The GPU Operator is packaged as a Helm Chart. It installs and manages the lifecycle of software components so GPU accelerated applications can be run on Kubernetes.
The components are as follows:
GPU Feature Discovery, which labels the worker node based on the GPU specs. This enables customers to more granularly select the GPU resources that their application requires.
The NVIDIA AI Enterprise Guest Driver
Kubernetes Device Plugin, which advertises the GPU to the Kubernetes scheduler
NVIDIA Container Toolkit – allows users to build and run GPU accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs.
DCGM Monitoring – Allows monitoring of GPUs on Kubernetes.
How does the GPU Operator help IT Infrastructure Teams?#
GPU Operator enables DevOps teams to manage the lifecycle of GPUs when used with Kubernetes at a Cluster level. There is no need to manage each node individually. Without GPU Operators, infrastructure teams had to manage two operating system images, one for GPU nodes and one CPU node. When using the GPU Operator, infrastructure teams can use a CPU image with GPU worker nodes. It allows customers to run GPU accelerated applications on immutable operating systems as well. Faster node provisioning is achievable since the GPU Operator has been built in a way that it detects newly added GPU accelerated Kubernetes worker nodes. Then automatically installs all software components required to run GPU accelerated applications. The GPU Operator is a single tool to manage all K8s components (GPU Device Plugin, GPU Feature Discovery, GPU Monitoring Tools, NVIDIA Runtime). It is important to note, GPU Operator installs NVIDIA AI Enterprise Guest Driver as well.