NVIDIA vGPU for Compute Overview#
NVIDIA vGPU (Virtual GPU) for Compute lets multiple VMs share one physical GPU while each VM sees a dedicated-style device. This page explains core terms, how components fit together, the three vGPU modes—Time-Sliced vGPU, MIG-Backed vGPU, and Time-Sliced MIG-Backed vGPU—headline features, and platform limitations—before you install or size a deployment.
Key Terms#
For definitions of vGPU Manager, vGPU Guest Driver, NVIDIA Licensing System, and NVIDIA AI Enterprise Infra Collection, see the Glossary.
NVIDIA vGPU Architecture Overview#
Under the NVIDIA Virtual GPU Manager on the hypervisor, one physical GPU can expose multiple vGPUs, each attachable to a guest VM as its own GPU device.
Download the latest vGPU for Compute drivers from the NVIDIA AI Enterprise Infra 8 collection.
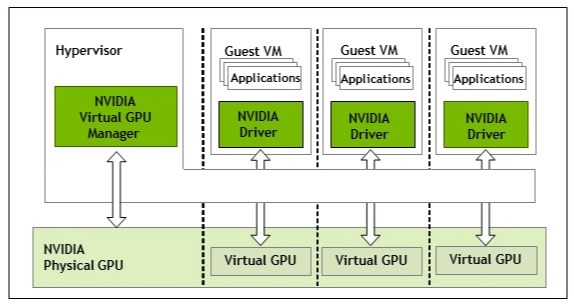
Each vGPU behaves like a GPU with a fixed framebuffer carved from the physical GPU at creation time; that memory stays reserved for that vGPU until the vGPU is destroyed.
NVIDIA vGPU for Compute Configurations#
Supported modes depend on the physical GPU:
Time-sliced vGPUs are available on all NVIDIA AI Enterprise supported GPUs.
On GPUs with Multi-Instance GPU (MIG), these MIG-backed variants are supported:
MIG-backed vGPUs that use a whole GPU instance
Time-sliced vGPUs within a MIG instance (time-sliced, MIG-backed)
vGPU Mode |
Description |
GPU Partitioning |
Isolation |
Use Cases |
Supported GPUs |
|---|---|---|---|---|---|
Time-Sliced vGPU |
Multiple Compute VMs time-share the same physical GPU: SMs and engines are used one vGPU at a time in scheduled slices. |
Temporal |
Strong hardware memory and fault isolation; round-robin scheduling yields solid throughput when strict per-VM compute isolation is not required. |
Workloads tolerating shared compute time, or platforms without MIG-backed vGPU. Typical fits: lighter inference, preprocessing, and model dev/test before large training. |
|
MIG-backed vGPU |
Built from one or more MIG slices on a MIG-capable GPU; each VM owns the SMs and engines of its GPU instance and runs in parallel with VMs on other instances on the same card. See Virtual GPU Types for Supported GPUs for profiles and sizing. |
Spatial |
Strong hardware memory and fault isolation; dedicated cache and memory bandwidth per instance with lower scheduling jitter than pure time-slicing on the full GPU. |
Multi-tenant or SLA-sensitive setups: consistent inference, fine-tuning, or smaller training jobs that need predictable isolation on one physical GPU. |
|
Time-Sliced, MIG-Backed vGPU |
Uses part of a MIG instance; VMs on that instance time-share its SMs and engines. Introduced with the RTX PRO 6000 and RTX PRO 4500 Blackwell Server Edition GPUs. Profile details: NVIDIA vGPU Types Reference. |
Spatial between MIG instances; temporal within each instance. |
Hardware isolation between instances; within an instance, time-sharing similar tradeoffs to full-GPU time-slicing but scoped to the MIG partition. |
Dense multi-tenant layouts that need hard boundaries between tenant groups but more than one light workload per MIG slice—for example:
|
RTX PRO 6000 Blackwell Server Edition, RTX PRO 4500 Blackwell Server Edition |
NVIDIA vGPU for Compute Key Features#
Beyond basic partitioning, vGPU for Compute adds networking, migration, scheduling, and memory features aimed at AI, ML, and HPC in virtualized clusters.
Key Capabilities
MIG-Backed vGPU - Hardware-level GPU partitioning with spatial isolation for multi-tenant workloads.
Device Groups - Automated detection and provisioning of physically connected devices for optimal topology.
GPUDirect RDMA and Storage - Direct memory access and storage I/O bypass that reduces CPU overhead and latency for GPU-to-GPU and GPU-to-storage transfers.
Heterogeneous vGPU - Mixed vGPU profiles on a single GPU for diverse workload requirements.
Live Migration - VM migration with minimal downtime (seconds of stun time) for maintenance and load balancing on supported hypervisors.
Multi-vGPU and P2P - Multiple vGPUs per VM with peer-to-peer communication.
NVIDIA NVSwitch - High-bandwidth GPU-to-GPU interconnect fabric through NVLink.
NVLink Multicast - Efficient one-to-many data distribution for distributed training.
Scheduling Policies - Workload-specific GPU scheduling algorithms.
Suspend-Resume - VM state preservation for flexible resource management.
Unified Virtual Memory - Single memory address space across CPU and GPU.
For platform support, configuration requirements, and compatibility tables per feature, see NVIDIA vGPU for Compute Features.
Product Limitations and Known Issues#
GPU Monitoring and Profiling on Hypervisor Hosts#
NVIDIA Data Center GPU Manager (DCGM) is not supported in vGPU environments:
Hypervisor hosts: Not supported on hosts running the NVIDIA AI Enterprise vGPU Manager (host driver), including Linux KVM with SR-IOV passthrough and MIG-backed vGPU.
vGPU guest VMs: Not supported inside guests for MIG-backed or time-sliced vGPU.
Expect missing or zero metrics, profiling errors, and loss of visibility; tools such as NVIDIA Nsight Compute may fail to read performance counters in these setups.
Hypervisor Limitations and Known Issues#
See Red Hat Enterprise Linux with KVM product limitations.
See Ubuntu KVM product limitations.
See VMware vSphere product limitations.
Large-Memory VMs (64 GB+ MMIO)
Some GPUs require 64 GB or more of MMIO space. When a vGPU on such a GPU is assigned to a VM with 32 GB or more of memory on ESXi, the VM’s MMIO space must be raised to the GPU’s requirement.
Details: Requirements for Using vGPU on GPUs Requiring 64 GB or More of MMIO Space with Large-Memory VMs.
GPU |
MMIO Space Required |
|---|---|
NVIDIA B300 HGX |
768 GB |
NVIDIA B200 HGX |
768 GB |
NVIDIA H200 (all variants) |
512 GB |
NVIDIA H100 (all variants) |
256 GB |
NVIDIA H800 (all variants) |
256 GB |
NVIDIA H20 141 GB |
512 GB |
NVIDIA H20 96 GB |
256 GB |
NVIDIA L40 |
128 GB |
NVIDIA L20 |
128 GB |
NVIDIA L4 |
64 GB |
NVIDIA L2 |
64 GB |
NVIDIA RTX 6000 Ada |
128 GB |
NVIDIA RTX 5000 Ada |
64 GB |
NVIDIA A40 |
128 GB |
NVIDIA A30 |
64 GB |
NVIDIA A10 |
64 GB |
NVIDIA A100 80 GB (all variants) |
256 GB |
NVIDIA A100 40 GB (all variants) |
128 GB |
NVIDIA RTX A6000 |
128 GB |
NVIDIA RTX A5500 |
64 GB |
NVIDIA RTX A5000 |
64 GB |
Microsoft Windows Server Limitations and Known Issues#
See Microsoft Windows Server product limitations.
NVIDIA AI Enterprise supports only the Tesla Compute Cluster (TCC) driver model for Windows guest drivers.
MIG-backed vGPU is not supported for Windows guests on NVIDIA H100 GPUs (including profiles such as H100XM-1-10C). Only time-sliced vGPU is supported there; assigning a MIG-backed profile to a Windows VM will fail at guest driver install.
Windows guest VMs only support running native applications—no containers. NVIDIA AI Enterprise features that require containerization are not supported on Windows guest operating systems.
On generic Linux under KVM, guest OS support for Windows follows the hypervisor vendor’s matrix.
More context: Non-containerized Applications on Hypervisors and Guest Operating Systems Supported with vGPU table.