Essential concepts
This section describes essential concepts necessary for understanding Clara Train. Clara Train v4.0 and later uses MONAI’s training workflows which are based off of PyTorch Ignite’s engine.
Clara Train is built using a component-based architecture with using components from MONAI for v4.0 and later:
Training Data Pipeline
Validation Data Pipeline
Applications <https://docs.monai.io/en/latest/apps.html>
Transforms <https://docs.monai.io/en/latest/transforms.html>
Inference methods <https://docs.monai.io/en/latest/inferers.html>
Event handlers <https://docs.monai.io/en/latest/handlers.html>
Network architectures <https://docs.monai.io/en/latest/networks.html>
Loss functions <https://docs.monai.io/en/latest/losses.html>
Optimizers <https://docs.monai.io/en/latest/optimizers.html>
Visualizations <https://docs.monai.io/en/latest/visualize.html>
Utilities <https://docs.monai.io/en/latest/utils.html>
As we add examples showing how to leverage components in specific ways, we are working on more detailed documentation on how the components impact the training workflow here.
The design principle of MONAI was to split PyTorch and ignite dependencies into different layers, so most of MONAI’s components just follow regular PyTorch APIs. This way for networks, loss functions, metrics, optimizers, and transforms, users can easily bring MONAI components into their regular PyTorch program or bring their own PyTorch components into MONAI program.
From Clara v4.0 the training and validation workflows are based on:
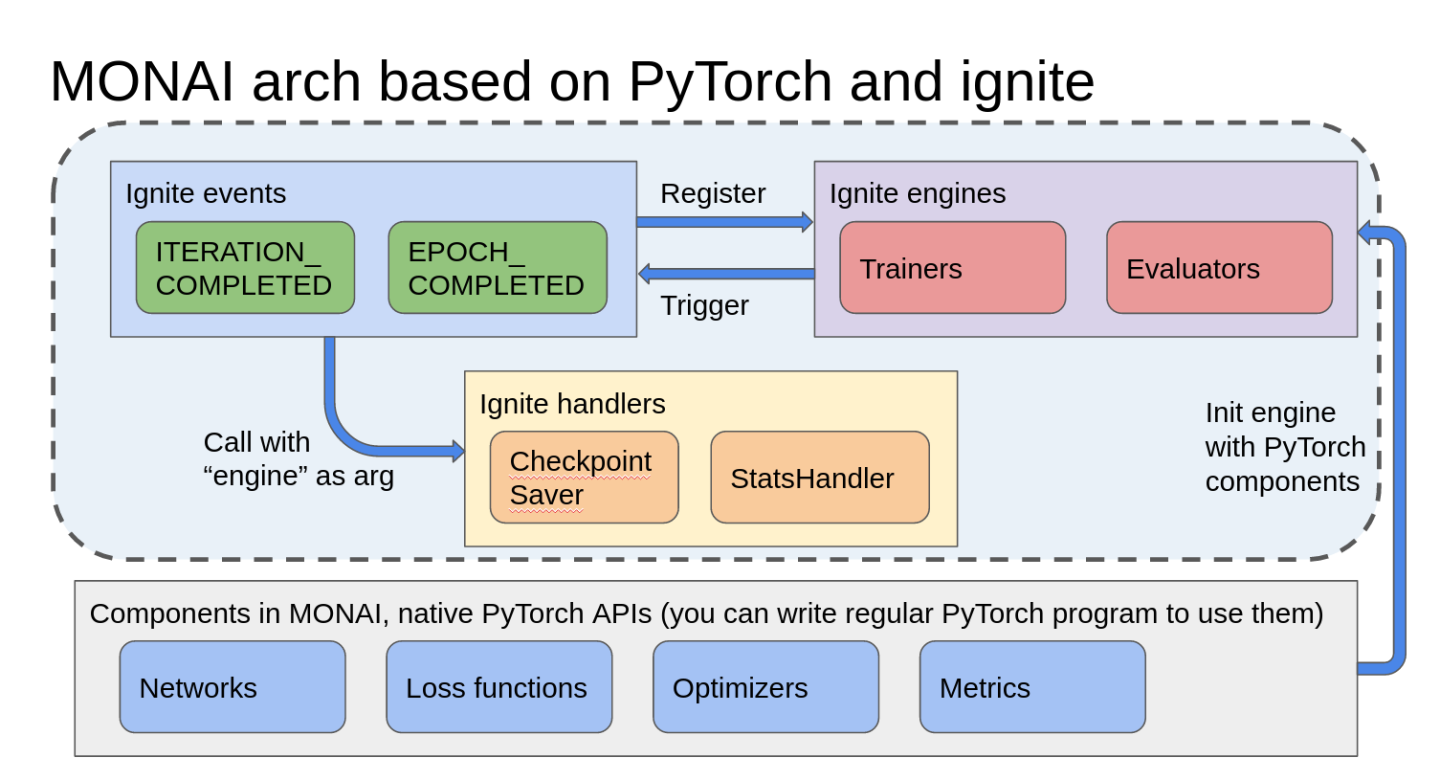
Data pipelines are responsible for producing batched data items during training. Typically, two data pipelines are used: one for producing training data, another producing validation data.
A data pipeline contains a chain of transforms that are applied to the input image and label data to produce the data in the format required by the model.
See MONAI Datasets for more information.
Data pipelines contain chains of transformations.
For a list of available transforms, see the MONAI transforms section.
Here is a list of the events in MONAI:
Event name |
Description |
|---|---|
STARTED |
triggered when engine’s run is started |
EPOCH_STARTED |
triggered when the epoch is started |
GET_BATCH_STARTED |
triggered before next batch is fetched |
GET_BATCH_COMPLETED |
triggered after the batch is fetched |
ITERATION_STARTED |
triggered when an iteration is started |
FORWARD_COMPLETED |
triggered when network(image, label) completed (MONAI) |
LOSS_COMPLETED |
triggered when loss(pred, label) completed (MONAI) |
BACKWARD_COMPLETED |
triggered when loss.backward() completed (MONAI) |
ITERATION_COMPLETED |
triggered when the iteration is ended |
DATALOADER_STOP_ITERATION |
triggered when dataloader has no more data to provide |
EXCEPTION_RAISED |
triggered when an exception is encountered |
TERMINATE_SINGLE_EPOCH |
triggered when the run is about to end the current epoch |
TERMINATE |
triggered when the run is about to end completely |
EPOCH_COMPLETED |
triggered when the epoch is ended |
COMPLETED |
triggered when engine’s run is completed |
MONAI workflows use engine as context data to communicate with handlers, handlers accept engine as an argument. Here is all the available data in engine:
properties:
network, # the model in use
optimizer, # (only in trainer) the optimizer for training progress
loss_function, # (only in trainer) loss function for training progress
amp, # flag that whether we are in AMP mode
should_terminate, # flag that whether we should terminate the program
should_terminate_single_epoch, # flag that whether we should terminate current epoch
state:
rank, # rank index of current process
iteration, # current iteration index, count from the first epoch
epoch, # current epoch index
max_epochs, # target epochs to complete current round
epoch_length, # count of iterations in every epoch
output, # output dict of current iteration, for trainer: ({"image": x, "label": x, "pred": x, "loss": x})
# for evaluator: ({"image": x, "label": x, "pred": x})
batch, # input dict for current iteration
metrics, # dict of metrics values, if we run metrics on training data to check overfitting,
# trainer will also have metrics results
metric_details, # dict of the temp data of metrics if set `save_details=True`,
# for example, MeanDice metric can save the mean dice of every channel in every image
dataloader, # DataLoader object to provide data
device, # device to run the program, cuda or cpu, etc.
key_metric_name, # name of the key metric
best_metric, # best metric value of the key metric
best_metric_epoch, # epoch index that we got the best metric
public functions:
terminate(), # send terminate signal to the engine, will terminate completely after current iteration
terminate_epoch(), # send terminate signal to the engine, will terminate current epoch after current iteration
Users can also add more data into engine.state at runtime.
Any of the already implemented and included PyTorch Ignite metrics may be used as well as custom metrics implemented in the same way.