GERMLINE PIPELINE
Given one or more pairs of fastq files, you can run the germline variant pipeline workflow to generate output including variants, BAM, and recal.
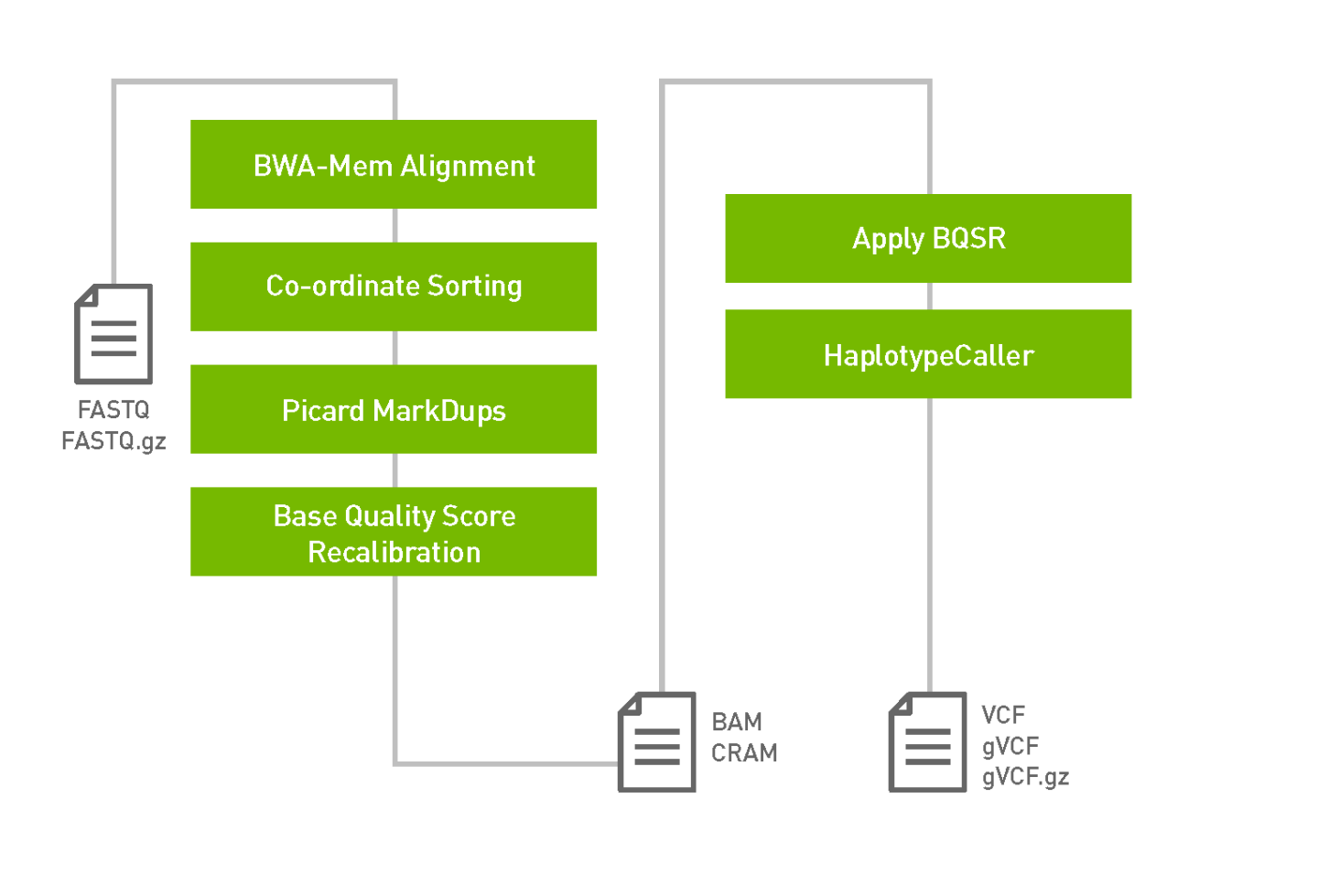
The germline pipeline shown below resembles the GATK4 best practices pipeline. The inputs are BWA-indexed reference files, pair-ended fastq files and knownSites for BQSR calculation. The outputs of this pipeline are:
Aligned, co-ordinate sorted, duplicated marked bam
BQSR report
Variants in vcf/g.vcf/g.vcf.gz format
Run a germline pipeline:
$ pbrun germline --ref Ref/Homo_sapiens_assembly38.fasta \
--in-fq Data/sample_1.fq.gz Data/sample_2.fq.gz \
--knownSites Ref/Homo_sapiens_assembly38.known_indels.vcf.gz \
--out-bam output.bam \
--out-variants output.vcf \
--out-recal-file report.txt
You’ll first need to install the application to your DNAnexus project. See our DNAnexus installation guide.
$ dx run pbgermline
The command below is the bwa-0.7.12 and GATK4 counterpart of the Parabricks command above. The output from these commands will generate the exact same results as the output from the above command. Please look at Output Comparison page on how you can compare the results.
# Run bwa-mem and pipe output to create sorted bam
$ bwa mem -t 32 -K 10000000 -R '@RG\tID:sample_rg1\tLB:lib1\tPL:bar\tSM:sample\tPU:sample_rg1' \
Ref/Homo_sapiens_assembly38.fasta S1_1.fastq.gz S1_2.fastq.gz | gatk \
SortSam --java-options -Xmx30g --MAX_RECORDS_IN_RAM=5000000 -I=/dev/stdin \
-O=cpu.bam --SORT_ORDER=coordinate --TMP_DIR=/raid/myrun
# Mark Duplicates
$ gatk MarkDuplicates --java-options -Xmx30g -I=cpu.bam -O=mark_dups_cpu.bam \
-M=metrics.txt --TMP_DIR=/raid/myrun
# Generate BQSR Report
$ gatk BaseRecalibrator --java-options -Xmx30g --input mark_dups_cpu.bam --output \
recal_cpu.txt --known-sites Ref/Homo_sapiens_assembly38.known_indels.vcf.gz \
--reference Ref/Homo_sapiens_assembly38.fasta
# Run ApplyBQSR Step
$ gatk ApplyBQSR --java-options -Xmx30g -R Ref/Homo_sapiens_assembly38.fasta \
-I=mark_dups_cpu.bam --bqsr-recal-file=recal_file.txt -O=cpu_nodups_BQSR.bam
#Run Haplotype Caller
$ gatk HaplotypeCaller --java-options -Xmx30g --input cpu_nodups_BQSR.bam --output \
result_cpu.vcf --reference Ref/Homo_sapiens_assembly38.fasta \
--native-pair-hmm-threads 16
- --ref
- --in-fq
- --in-se-fq
- --out-bam
- --out-variants
- --in-mba-file
- --out-recal-file
- --knownSites
- --tmp-dir
- --num-gpus
- --no-markdups
- --out-duplicate-metrics
- --markdups-assume-sortorder-queryname
- --optical-duplicate-pixel-distance
- --mba
- --read-group-sm
- --read-group-lb
- --read-group-pl
- --read-group-id-prefix
- --static-quantized-quals
- --batch
- --disable-read-filter
- --ploidy
- --interval-file
- --interval
- --interval-padding
- --gvcf
- --bwa-options
- --haplotypecaller-options
- --max-alternate-alleles
- --annotation-group
- --gvcf-gq-bands
- --num-gpus
- --gpu-devices
(required) The reference genome in fasta format. We assume that the indexing required to run bwa has been completed by the user.
(required) Pair ended fastq files. These can be in .fq.gz or .fastq.gz format. You can provide multiple pairs as inputs like so:... --in-fq $fq1 $fq2 --in-fq $fq3 $fq4 ...
(required) Single ended fastq files. These can be in .fastq or .fastq.gz format. You can provide read group information as an optional third argument.
Example 1:
--in-se-fq sampleX.fastq.gz
Example 2:
--in-se-fq sampleX.fastq.gz "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:sample\tPU:unit1"
This option can be repeated multiple times as well.
Example 1:
--in-se-fq sampleX_1.fastq.gz --in-se-fq sampleX_2.fastq.gz
Example 2:
--in-se-fq sampleX_1.fastq.gz "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:sample\tPU:unit1" \
--in-se-fq sampleX_2.fastq.gz "@RG\tID:foo2\tLB:lib1\tPL:bar\tSM:sample\tPU:unit2"
Either all sets of inputs have read group or none should have it and will be automatically added by the pipeline. For the same sample, Read Groups should have the same sample name (SM) and different ID and PU.
(required) Path to the file that will contain BAM output.
(required) Name of VCF/GVCF/GVCF.GZ file after Variant Calling. Absolute or relative path can be given.
Path to a file containing options for MergeBAMAlignment. Currently supported options are ATTRIBUTES_TO_RETAIN, ATTRIBUTES_TO_REMOVE, ATTRIBUTES_TO_REMOVE, MAX_INSERTIONS_OR_DELETIONS, PRIMARY_ALIGNMENT_STRATEGY, UNMAPPED_READ_STRATEGY, ALIGNER_PROPER_PAIR_FLAGS, UNMAP_CONTAMINANT_READS, and ADD_PG_TAG_TO_READS. Each option must be specified on a new line in the file. Refer to Picard MergeBAMAlignment documentation for details on these options.
Path of report file (.txt format) after Base Quality Score Recalibration.
Full path to a known indels file. Must be in vcf format. This option can be used multiple times.
Defaults to .. Full path to the directory where temporary files will be stored.
Defaults to number of GPUs in the system.
The number of GPUs to be used for this analysis task.
Defaults to False.
Do not mark duplicates, generate bam after co-ordinate sorting.
Path of duplicate metrics file after Marking Duplicates.
Assume the reads are sorted by queryname for Marking Duplicates. This will mark secondary, supplementary and unmapped reads as duplicates as well. This flag will not impact variant calling while increasing processing times.
The maximum offset between two duplicate clusters in order to consider them optical duplicates. Ignored if –out-duplicate-metrics is not passed.
Run MergeBAMAlignment after alignment.
SM tag for read groups in this run.
LB tag for read groups in this run.
PL tag for read groups in this run.
Prefix for ID and PU tag for read groups in this run. This prefix will be used for all pair of fastq files in this run. The ID and PU tag will consist of this prefix and an identifier which will be unique for a pair of fastq files.
Use static quantized quality scores to a given number of levels. Repeat this option multiple times for multiple bins.
Given an input list of BAMs, run the variant calling of each BAM using one GPU, and process BAMs in parallel based on how many GPUs the system has.
Disable the read filters for bam entries. Currently supported read filters that can be disabled are: MappingQualityAvailableReadFilter, MappingQualityReadFilter, and NotSecondaryAlignmentReadFilter.
Defaults to 2. ploidy assumed for the bam file. Currently only haploid (ploidy 1) and diploid (ploidy 2) are supported.
Path to an interval file for BQSR step with possible formats: Picard-style (.interval_list or .picard), GATK-style (.list or .intervals), or BED file (.bed). This option can be used multiple times (default: None)
(-L) Interval strings within which to call variants from the input reads. All intervals will have a padding of 100 to get read records and overlapping intervals will be combined. Interval files should be passed using the –interval-file option. This option can be used multiple times. e.g. -L chr1 -L chr2:10000 -L chr3:20000+ -L chr4:10000-20000 (default: None)
(-ip) Padding size (in base pairs) to add to each interval you are including (default: None)
Defaults to False.
Generate variant calls in gvcf format. Final output will have .g.vcf extension.
Pass supported bwa mem options as one string. Current original bwa mem supported options, -M, -Y, -T.
Pass supported haplotype caller options as one string. Current original original haplotypecaller supported options, - min_pruning , -standard-min-confidence-threshold-for- calling .
Maximum number of alternate alleles to genotype (default: None)
(-G) Which groups of annotations to add to the output variant calls. Currently supported annotation groups: StandardAnnotation, StandardHCAnnotation, AS_StandardAnnotation (default: None)
(-GQB) Exclusive upper bounds for reference confidence GQ bands. Must be in the range [1, 100] and specified in increasing order (default: None)
Defaults to number of GPUs in the system. The number of GPUs to be used for this analysis task.
Which GPU devices to use for a run. By default, all GPU devices will be used. To set specific GPU devices, enter a comma-separated list of GPU device numbers.
Option1: Use the DNAnexus command line dialog to run the workflow:
$ dx run pbgermline
Option 2: Specify your inputs via command line options:
$ dx run pbgermline -y \
--allow-ssh \
--destination=MY_OUTPUT_DIR \
-iref=MY_REF_FILE_ID \
-iknown_sites=MY_KNOWN_INDELS_FILE_ID \
-iin_fq=MY_FIRT_FQ_FILE_ID \
-iin_fq=MY_SECOND_FQ_FILE_ID